Visual Captions
v1.0
Visual Captions subtitle tool, Visual Captions is a newly launched powerful subtitle tool that can improve the display of more subtitles for users’ work meetings and make office communication more convenient. Users in need can come and join us.
Google demonstrated a system, Visual Captions, at the ACM CHI (Conference on Human Factors in Computing Systems), the top conference on human-computer interaction, introducing a new visual solution in remote meetings that can generate or retrieve pictures in the context of the conversation to improve the other party's performance. Knowledge of complex or unfamiliar concepts.
The Visual Captions system is based on a fine-tuned large-scale language model that can proactively recommend relevant visual elements in open-vocabulary conversations, and has been integrated into the open source project ARChat.
In the user survey, the researchers invited 26 participants in the laboratory and 10 participants outside the laboratory to evaluate the system. More than 80% of users basically agreed that Video Captions can provide video captions in various scenarios. Visual recommendations that are useful, meaningful, and enhance the communication experience.
Before development, the researchers first invited 10 internal participants, including software engineers, researchers, UX designers, visual artists, students and other practitioners with technical and non-technical backgrounds, to discuss the specific needs and requirements for real-time visual enhancement services. expect.
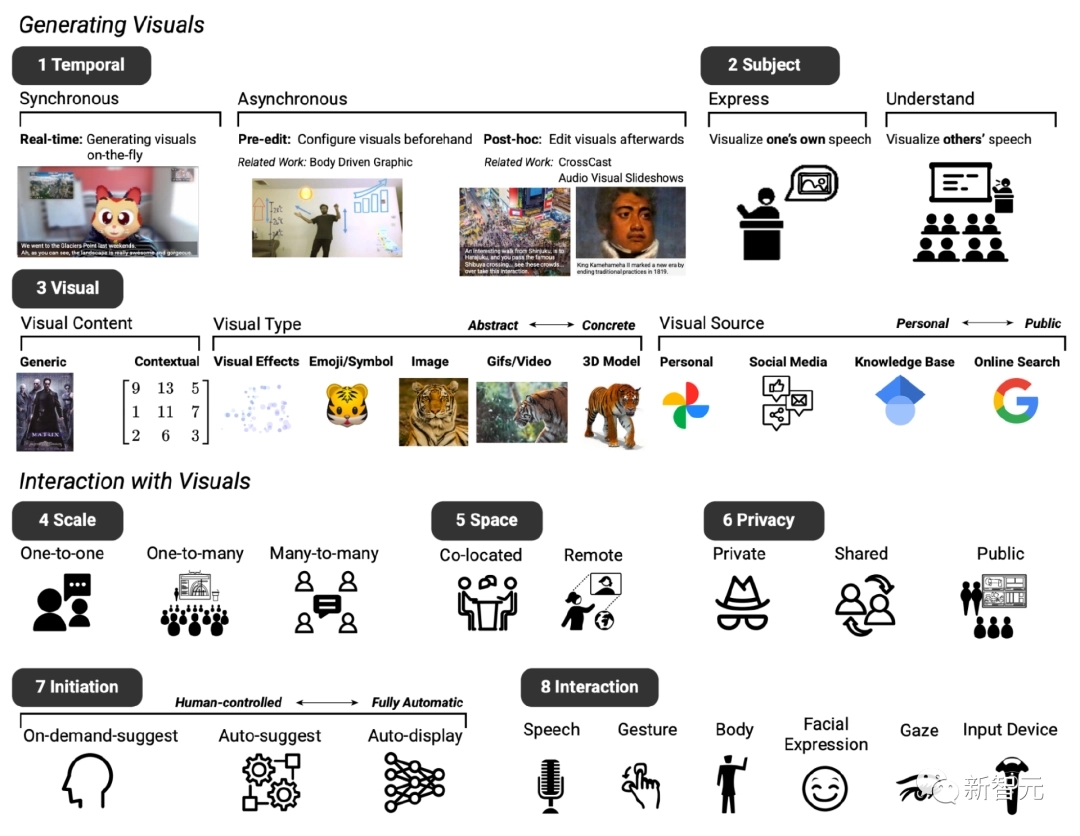
After two meetings, based on the existing text-to-image system, the basic design of the expected prototype system was established, mainly including eight dimensions (denoted as D1 to D8).
D1: Timing, the visual enhancement system can be displayed synchronously or asynchronously with the dialogue
D2: Topic, which can be used to express and understand speech content
D3: Visual, using a wide range of visual content, visual types and visual sources
D4: Scale, visual enhancements may vary depending on meeting size
D5: Space, whether the video conference is co-located or in a remote setting
D6: Privacy, these factors also influence whether visuals should be displayed privately, shared among participants, or made available to everyone
D7: Initial state, participants also identified different ways they would like to interact with the system when engaging in a conversation, for example, different levels of “initiative” where users can autonomously determine when the system intervenes in the chat D8: Interaction, participants envisioned different interaction methods, such as input using voice or gestures