bitnet.cpp هو إطار الاستدلال الرسمي لـ LLMs ذات 1 بت (على سبيل المثال، BitNet b1.58). إنه يقدم مجموعة من النوى المحسنة، التي تدعم الاستدلال السريع وغير المنقوص لنماذج 1.58 بت على وحدة المعالجة المركزية (مع دعم NPU وGPU بعد ذلك).
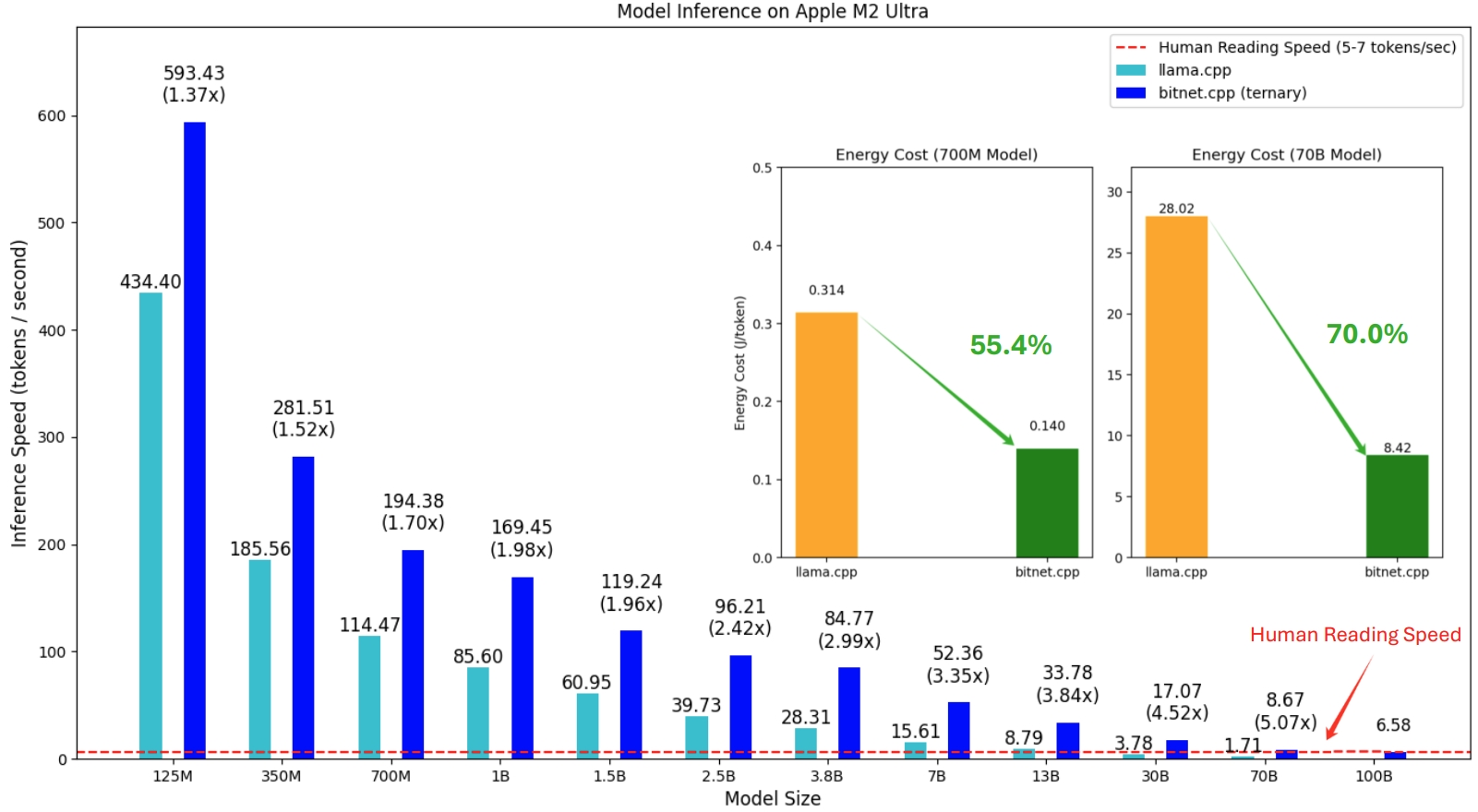
الإصدار الأول من bitnet.cpp هو دعم الاستدلال على وحدات المعالجة المركزية (CPUs). يحقق bitnet.cpp سرعات تصل إلى 1.37x إلى 5.07x على وحدات المعالجة المركزية ARM، مع تحقيق الطرز الأكبر مكاسب أكبر في الأداء. بالإضافة إلى ذلك، فهو يقلل من استهلاك الطاقة بنسبة 55.4% إلى 70.0% ، مما يعزز الكفاءة الإجمالية. على وحدات المعالجة المركزية x86، تتراوح عمليات التسريع من 2.37x إلى 6.17x مع تخفيضات في الطاقة تتراوح بين 71.9% إلى 82.2% . علاوة على ذلك، يمكن لـ bitnet.cpp تشغيل نموذج 100B BitNet b1.58 على وحدة معالجة مركزية واحدة، مما يحقق سرعات مماثلة للقراءة البشرية (5-7 رموز في الثانية)، مما يعزز بشكل كبير إمكانية تشغيل LLMs على الأجهزة المحلية. يرجى الرجوع إلى التقرير الفني لمزيد من التفاصيل.


النماذج التي تم اختبارها عبارة عن إعدادات وهمية تستخدم في سياق البحث لتوضيح أداء الاستدلال لـ bitnet.cpp.
عرض توضيحي لـ bitnet.cpp الذي يقوم بتشغيل طراز BitNet b1.58 3B على Apple M2:
21/10/2024 الأشعة تحت الحمراء للذكاء الاصطناعي 1 بت: الجزء 1.1، استنتاج BitNet b1.58 السريع وغير المنقوص على وحدات المعالجة المركزية (CPU)
17/10/2024 تم إصدار bitnet.cpp 1.0.
21/03/2024 عصر 1 بت LLMs__Training_Tips_Code_FAQ
27/02/2024 عصر دورات LLM ذات 1 بت: جميع نماذج اللغات الكبيرة موجودة في 1.58 بت
17/10/2023 BitNet: قياس محولات 1 بت لنماذج اللغات الكبيرة
يعتمد هذا المشروع على إطار عمل llama.cpp. نود أن نشكر جميع المؤلفين على مساهماتهم في مجتمع المصادر المفتوحة. كما أن نواة bitnet.cpp مبنية على أعلى منهجيات جدول البحث الرائدة في T-MAC. للاستدلال على LLMs العامة ذات البت المنخفض خارج النماذج الثلاثية، نوصي باستخدام T-MAC.
❗️ نحن نستخدم LLMs ذات 1 بت المتوفرة على Hugging Face لتوضيح إمكانيات الاستدلال الخاصة بـ bitnet.cpp. لم يتم تدريب هذه النماذج ولم يتم إصدارها بواسطة Microsoft. نأمل أن يكون إصدار bitnet.cpp مصدر إلهام لتطوير LLMs ذات 1 بت في إعدادات واسعة النطاق من حيث حجم النموذج ورموز التدريب.
| نموذج | حدود | وحدة المعالجة المركزية | نواة | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-كبير | 0.7 ب | x86 | ✔ | ✘ | ✔ |
| ذراع | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3 ب | x86 | ✘ | ✘ | ✔ |
| ذراع | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-الرموز | 8.0 ب | x86 | ✔ | ✘ | ✔ |
| ذراع | ✔ | ✔ | ✘ | ||
بيثون>=3.9
كميك>=3.22
رنة>=18
تطوير سطح المكتب باستخدام C++
أدوات C++-CMake لنظام التشغيل Windows
جيت لنظام التشغيل Windows
مترجم C++-Clang لنظام التشغيل Windows
دعم MS-Build لمجموعة أدوات LLVM (clang)
بالنسبة لمستخدمي Windows، قم بتثبيت Visual Studio 2022. في برنامج التثبيت، قم بالتبديل على الخيارات التالية على الأقل (يؤدي هذا أيضًا إلى تثبيت الأدوات الإضافية المطلوبة تلقائيًا مثل CMake):
بالنسبة لمستخدمي Debian/Ubuntu، يمكنك التنزيل باستخدام البرنامج النصي للتثبيت التلقائي
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
كوندا (نوصي بشدة)
مهم
إذا كنت تستخدم نظام التشغيل Windows، فيرجى تذكر استخدام موجه أوامر المطور / PowerShell لـ VS2022 دائمًا للأوامر التالية
استنساخ الريبو
استنساخ بوابة - العودية https://github.com/microsoft/BitNet.gitcd BitNet
تثبيت التبعيات
# (مستحسن) إنشاء بيئة كوندا جديدةconda create -n bitnet-cpp python=3.9 كوندا تفعيل bitnet-cpp تثبيت النقطة -r متطلبات.txt
بناء المشروع
# قم بتنزيل النموذج من Hugging Face، وقم بتحويله إلى تنسيق gguf الكمي، ثم قم بإنشاء مشروع python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# أو يمكنك تنزيل النموذج يدويًا و التشغيل باستخدام pathhuggingface-cli المحلي، تنزيل HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dirmodels/Llama3-8B-1.58-100B-tokens بايثون setup_env.py -mdmodels/Llama3-8B-1.58-100B-tokens -q i2_s
الاستخدام: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--النوع الكمي {i2_s,tl1}] [--quant-embd]
[--استخدام مضبوط]
إعداد البيئة لتشغيل الاستدلال
الحجج الاختيارية:
-h, --help في إظهار رسالة المساعدة هذه والخروج
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-الرموز}
النموذج المستخدم للاستدلال
--model-dir MODEL_DIR, -md MODEL_DIR
دليل لحفظ/تحميل النموذج
--log-dir LOG_DIR، -ld LOG_DIR
دليل لحفظ معلومات التسجيل
--النوع الكمي {i2_s,tl1}، -q {i2_s,tl1}
نوع التكميم
--quant-embd قم بتكميم التضمينات إلى f16
--use-pretuned, -p استخدم معلمات kernel المضبوطة مسبقًا# تشغيل الاستدلال باستخدام النموذج الكميpython run_inference.py -mmodels/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "عاد دانيال إلى الحديقة. وسافرت ماري إلى المطبخ. ساندرا سافرت إلى المطبخ. ذهبت ساندرا إلى الردهة. ذهب جون إلى غرفة النوم. عادت ماري إلى الحديقة. أين ماري؟ الإجابة:" -n 6 -temp 0# الإخراج:# عاد دانيال إلى الحديقة. ذهبت ماري إلى المطبخ. ذهبت ساندرا إلى المطبخ. ذهبت ساندرا إلى الردهة. ذهب جون إلى غرفة النوم. عادت مريم إلى الحديقة. أين مريم؟ #الجواب: مريم في البستان.
الاستخدام: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-درجة الحرارة المؤقتة]
تشغيل الاستدلال
الحجج الاختيارية:
-h, --help في إظهار رسالة المساعدة هذه والخروج
-م نموذج، - نموذج نموذج
المسار إلى ملف النموذج
-n N_PREDICT، --n- توقع N_PREDICT
عدد الرموز المميزة التي يجب التنبؤ بها عند إنشاء النص
-p موجه، --مطالبة موجه
المطالبة بإنشاء نص من
-t المواضيع، -- المواضيع المواضيع
عدد الخيوط المستخدمة
-c CTX_SIZE، --ctx-size CTX_SIZE
حجم السياق الفوري
- درجة الحرارة - درجة الحرارة - درجة الحرارة
درجة الحرارة، وهي معلمة مفرطة تتحكم في عشوائية النص الذي تم إنشاؤهنحن نقدم البرامج النصية لتشغيل معيار الاستدلال الذي يوفر نموذجًا.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
وفيما يلي شرح موجز لكل وسيطة:
-m , --model : المسار إلى ملف النموذج. هذه وسيطة مطلوبة يجب توفيرها عند تشغيل البرنامج النصي.
-n , --n-token : عدد الرموز المميزة التي سيتم إنشاؤها أثناء الاستدلال. إنها وسيطة اختيارية بقيمة افتراضية تبلغ 128.
-p , --n-prompt : عدد الرموز المميزة المستخدمة لإنشاء النص. هذه وسيطة اختيارية بقيمة افتراضية تبلغ 512.
-t , --threads : عدد الخيوط المستخدمة لتشغيل الاستدلال. إنها وسيطة اختيارية بقيمة افتراضية تبلغ 2.
-h , --help : إظهار رسالة المساعدة والخروج. استخدم هذه الوسيطة لعرض معلومات الاستخدام.
على سبيل المثال:
بايثون utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
سيعمل هذا الأمر على تشغيل معيار الاستدلال باستخدام النموذج الموجود في /path/to/model ، مما يؤدي إلى إنشاء 200 رمز مميز من 256 رمزًا مميزًا، باستخدام 4 سلاسل رسائل.
بالنسبة لتخطيط النموذج الذي لا يدعمه أي نموذج عام، فإننا نقدم نصوصًا برمجية لإنشاء نموذج وهمي باستخدام تخطيط النموذج المحدد، وتشغيل المعيار على جهازك:
python utils/generate-dummy-bitnet-model.pymodels/bitnet_b1_58-large --outfilemodels/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# قم بتشغيل المعيار باستخدام النموذج الذي تم إنشاؤه، استخدم -m لتحديد مسار النموذج، -p لتحديد الموجه الذي تمت معالجته، -n لتحديد عدد الرمز المميز المطلوب إنشاء بايثون utils/e2e_benchmark.py -mmodels/dummy-bitnet-125m.tl1.gguf -p 512 -n 128