ke dialogue
1.0.0


وهذا هو تنفيذ الورقة:
تعلم قواعد المعرفة مع معلمات أنظمة الحوار الموجهة نحو المهام . أندريا مادوتو ، صامويل كاهياويجايا، جينتا إندرا ويناتا، يان شو، زيهان ليو، تشاوجيانغ لين، باسكال فونغ، نتائج EMNLP 2020 [PDF]
إذا كنت تستخدم أي رموز مصدر أو مجموعات بيانات مضمنة في مجموعة الأدوات هذه في عملك، فيرجى الاستشهاد بالمقالة التالية. Bibtex مدرج أدناه:
@article{madotto2020learning,
title={تعلم قواعد المعرفة باستخدام معلمات أنظمة الحوار الموجهة نحو المهام},
المؤلف={مادوتو، أندريا وكاهياويجايا، صامويل وويناتا، جينتا إندرا وشو، يان وليو، زيهان ولين، تشاوجيانغ وفونغ، باسكال}،
مجلة = {arXiv طبعة أولية arXiv:2009.13656}،
العام={2020}
}
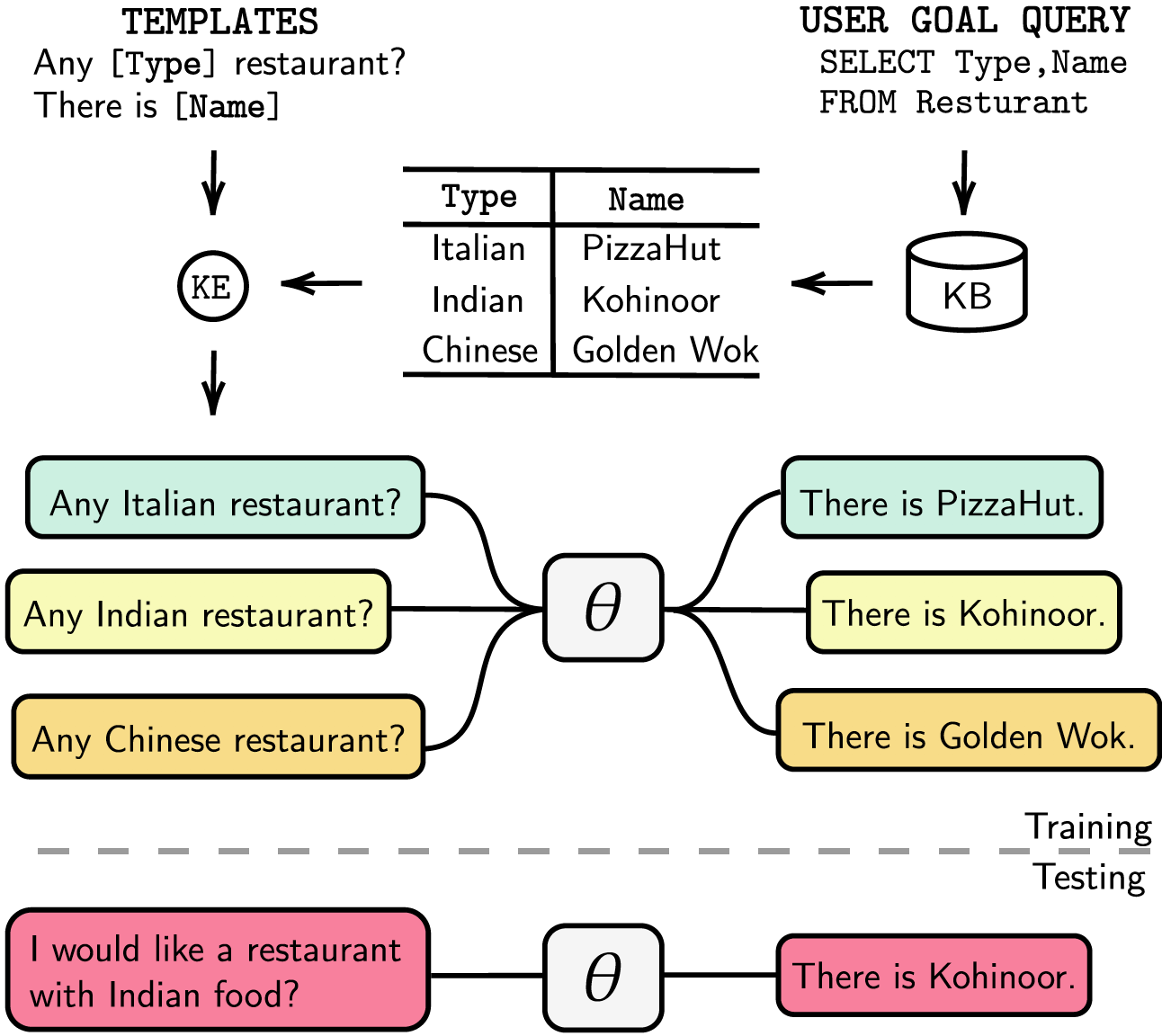
تكون أنظمة الحوار الموجهة نحو المهام إما نموذجية مع تتبع حالة الحوار المنفصل (DST) وخطوات الإدارة أو قابلة للتدريب من البداية إلى النهاية. وفي كلتا الحالتين، تلعب قاعدة المعرفة (KB) دورًا أساسيًا في تلبية طلبات المستخدم. تعتمد الأنظمة المعيارية على التوقيت الصيفي للتفاعل مع قاعدة المعارف، وهو أمر مكلف من حيث وقت التعليق التوضيحي والاستدلال. تستخدم الأنظمة الشاملة قاعدة المعارف مباشرة كمدخل، لكن لا يمكنها التوسع عندما تكون قاعدة المعارف أكبر من بضع مئات من الإدخالات. في هذا البحث، نقترح طريقة لتضمين قاعدة المعرفة، بأي حجم، مباشرة في معلمات النموذج. لا يتطلب النموذج الناتج أي استجابات للتوقيت الصيفي أو القالب، ولا قاعدة المعارف كمدخلات، ويمكنه تحديث قاعدة المعارف الخاصة به ديناميكيًا عبر الضبط الدقيق. نقوم بتقييم الحل الذي نقدمه في خمس مجموعات بيانات للحوار موجهة نحو المهام بحجم كيلوبايت صغير ومتوسط وكبير. تُظهر تجاربنا أن النماذج الشاملة يمكنها تضمين قواعد المعرفة بشكل فعال في معاييرها وتحقيق أداء تنافسي في جميع مجموعات البيانات التي تم تقييمها.
لقد أدرجنا تبعياتنا في ملف requirements.txt ، ويمكنك تثبيت التبعيات عن طريق التشغيل
❱❱❱ pip install -r requirements.txt بالإضافة إلى ذلك، يشتمل الكود الخاص بنا أيضًا على دعم fp16 مع apex . يمكنك العثور على الحزمة من https://github.com/NVIDIA/apex.
مجموعة البيانات قم بتنزيل مجموعة البيانات التي تمت معالجتها مسبقًا ووضع الملف المضغوط داخل المجلد ./knowledge_embed/babi5 . قم باستخراج الملف المضغوط عن طريق التنفيذ
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipقم بإنشاء مربعات حوار غير معجمية من مجموعة بيانات bAbI-5 عبر
❱❱❱ python3 generate_delexicalization_babi.pyقم بإنشاء البيانات المعجمية من مجموعة بيانات bAbI-5 عبر
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 حيث الحد الأقصى <num_augmented_knowledge> هو 558 (موصى به) و <num_augmented_dialogues> > هو 264 لأنه يتوافق مع عدد المعرفة وعدد الحوارات في مجموعة بيانات bAbI-5.
ضبط GPT-2
نحن نقدم نقطة التفتيش لنموذج GPT-2 المضبوط بدقة على مجموعة تدريب bAbI. يمكنك أيضًا اختيار تدريب النموذج بنفسك باستخدام الأمر التالي.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> يلاحظ أن قيمة --kbpercentage تساوي <num_augmented_dialogues> تلك التي تأتي من المعجمية. يتم استخدام هذه المعلمة لتحديد ملف التعزيز لتضمينه في مجموعة بيانات القطار.
يمكنك تقييم النموذج عن طريق تنفيذ البرنامج النصي التالي
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks تسجيل النقاط bAbI-5 لتشغيل المسجل لنموذج المهمة bAbI-5، يمكنك تشغيل الأمر التالي. سوف يقرأ برنامج Scorer جميع ملفات result.json الموجودة ضمن مجلد runs الذي تم إنشاؤه من evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0مجموعة البيانات
قم بتنزيل مجموعة البيانات التي تمت معالجتها مسبقًا ووضع الملف المضغوط ضمن المجلد ./knowledge_embed/camrest . قم بفك ضغط الملف المضغوط عن طريق التنفيذ
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipقم بإنشاء مربعات حوار غير معجمية من مجموعة بيانات CamRest عبر
❱❱❱ python3 generate_delexicalization_CAMREST.pyقم بإنشاء البيانات المعجمية من مجموعة بيانات CamRest عبر
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 حيث يكون الحد الأقصى لـ <num_augmented_knowledge> هو 201 (موصى به) و <num_augmented_dialogues> > هو 156، وهو رقم كبير جدًا لأنه يتوافق مع عدد المعرفة وعدد الحوارات في مجموعة بيانات CamRest.
ضبط GPT-2
نحن نقدم نقطة التفتيش لنموذج GPT-2 المضبوط بدقة على مجموعة تدريب CamRest. يمكنك أيضًا اختيار تدريب النموذج بنفسك باستخدام الأمر التالي.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> يلاحظ أن قيمة --kbpercentage تساوي <num_augmented_dialogues> تلك التي تأتي من المعجمية. يتم استخدام هذه المعلمة لتحديد ملف التعزيز لتضمينه في مجموعة بيانات القطار.
يمكنك تقييم النموذج عن طريق تنفيذ البرنامج النصي التالي
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest تسجيل النقاط CamRest لتشغيل المسجل لنموذج المهمة bAbI 5، يمكنك تشغيل الأمر التالي. سوف يقرأ برنامج Scorer جميع ملفات result.json ضمن مجلد runs الذي تم إنشاؤه من evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0مجموعة البيانات
قم بتنزيل مجموعة البيانات التي تمت معالجتها مسبقًا ووضعها ضمن المجلد ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipضبط GPT-2
نحن نقدم نقطة تفتيش لنموذج GPT-2 المضبوط بدقة على مجموعة تدريب SMD. قم بتنزيل نقطة التفتيش ووضعها ضمن مجلد ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsيمكنك أيضًا اختيار تدريب النموذج بنفسك باستخدام الأمر التالي.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12إعداد الحوارات المضمنة المعرفة
أولا، نحن بحاجة إلى بناء قواعد بيانات لاستعلام SQL.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test ثم نقوم بإنشاء حوارات بناءً على قوالب مصممة مسبقًا حسب المجالات. يمكّنك الأمر التالي من إنشاء حوارات في مجال weather . يرجى استبدال weather navigate أو schedule في dialogue_path ووسائط domain إذا كنت تريد إنشاء مربعات حوار في المجالين الآخرين. يمكنك أيضًا تغيير عدد القوالب المستخدمة في عملية إعادة التعميم عن طريق تغيير الوسيطة num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testقم بتكييف نموذج GPT-2 المضبوط بدقة مع مجموعة الاختبار
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""يمكنك أيضًا تسريع عملية الضبط عن طريق إجراء التجارب بشكل متوازي. يرجى تعديل إعداد GPU في #L14 من الكود.
❱❱❱ python runner_expe_SMD.py مجموعة البيانات
قم بتنزيل مجموعة البيانات التي تمت معالجتها مسبقًا ووضعها ضمن المجلد ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipإعداد مربعات الحوار المضمنة للمعرفة (يمكنك تخطي هذه الخطوة، إذا قمت بتنزيل الملف المضغوط أعلاه)
يمكنك تحضير مجموعات البيانات عن طريق التشغيل
❱❱❱ bash generate_MWOZ_all_data.shيقوم البرنامج النصي Shell بإنشاء مربعات حوار غير معجمية من مجموعة بيانات MWOZ عن طريق الاتصال
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyضبط GPT-2
نحن نقدم نقطة تفتيش لنموذج GPT-2 المضبوط بدقة على مجموعة تدريب MWOZ. قم بتنزيل نقطة التفتيش ووضعها ضمن مجلد ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsيمكنك أيضًا اختيار تدريب النموذج بنفسك باستخدام الأمر التالي.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 الشروع في العمل نحن نستخدم إصدار خادم مجتمع neo4j ومكتبة apoc لمعالجة بيانات الرسم البياني. يتم استخدام apoc لموازاة الاستعلام في neo4j ، حتى نتمكن من معالجة الرسم البياني واسع النطاق بشكل أسرع
قبل المتابعة إلى قسم مجموعة البيانات، عليك التأكد من تثبيت neo4j (https://neo4j.com/download-center/#community) و apoc (https://neo4j.com/developer/neo4j-apoc/) على النظام الخاص بك.
إذا لم تكن على دراية بتركيبات CYPHER و apoc ، فيمكنك اتباع البرنامج التعليمي في https://neo4j.com/developer/cypher/ و https://neo4j.com/blog/intro-user-defined-procedures-apoc/
مجموعة البيانات قم بتنزيل مجموعة البيانات الأصلية ووضع الملف المضغوط داخل المجلد ./knowledge_embed/opendialkg . قم باستخراج الملف المضغوط عن طريق التنفيذ
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipقم بإنشاء مربعات حوار غير معجمية من مجموعة بيانات opendialkg عبر ( تحذير : يتطلب هذا حوالي 12 ساعة للتشغيل)
❱❱❱ python3 generate_delexicalization_DIALKG.py سينتج هذا البرنامج النصي ./opendialkg/dialogkg_train_meta.pt والذي سيتم استخدامه لإنشاء الحوار المعجمي. يمكنك بعد ذلك إنشاء الحوار المعجمي من مجموعة بيانات opendialkg عبر
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 سينتج هذا البرنامج النصي عينات من الحوارات في معظم عينات batch_size * max_iter ، ولكن في كل دفعة هناك احتمال عدم وجود مرشح صالح مما يؤدي إلى عينات أقل. عدد التوليد محدود بعامل آخر يسمى stop_count والذي سيوقف التوليد إذا كان عدد العينات التي تم إنشاؤها أكبر من عدد stop_count المحدد. سينتج الملف 4 ملفات: ./opendialkg/db_count_records_{random_seed}.csv و ./opendialkg/used_count_records_{random_seed}.csv و ./opendialkg/generation_iteration_{random_seed}.csv Generation_iteration_{random_seed}.csv والتي تستخدم للتحقق من تحول توزيع العد في قاعدة البيانات. و ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json الذي يحتوي على العينات التي تم إنشاؤها.
ملحوظات :
neo4j داخل generate_delexicalization_DIALKG.py و generate_dialogues_DIALKG.py يدويًا.ضبط GPT-2
نحن نقدم نقطة التفتيش لنموذج GPT-2 المضبوط بدقة على مجموعة التدريب opendialkg. يمكنك أيضًا اختيار تدريب النموذج بنفسك باستخدام الأمر التالي.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 يلاحظ أن قيمة --kbpercentage تساوي <random_seed> تلك التي تأتي من المعجمية. يتم استخدام هذه المعلمة لتحديد ملف التعزيز لتضمينه في مجموعة بيانات القطار.
يمكنك تقييم النموذج عن طريق تنفيذ البرنامج النصي التالي
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg تسجيل النقاط OpenDialKG لتشغيل المسجل لنموذج المهمة bAbI-5، يمكنك تشغيل الأمر التالي. سوف يقرأ برنامج Scorer جميع ملفات result.json الموجودة ضمن مجلد runs الذي تم إنشاؤه من evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 للحصول على التفاصيل المتعلقة بالتجارب والمعلمات الفائقة ونتائج التقييم، يمكنك العثور عليها في الورقة الرئيسية والمواد التكميلية لعملنا.



