كوزموس اكس
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) أنشئ التكوين الخاص بك باستخدام: accelerate config ثم: accelerate launch train.py
يستخدم KOSMOS-1 بنية محول لوحدة فك التشفير فقط تعتمد على Magneto (المحولات الأساسية)، أي بنية تستخدم ما يسمى بنهج LN الفرعي حيث تتم إضافة توحيد الطبقة قبل وحدة الانتباه (ما قبل LN) وبعد ذلك (ما بعد-LN) ln) يجمع بين المزايا التي يتمتع بها أي من النهجين لنمذجة اللغة وفهم الصور على التوالي. تتم أيضًا تهيئة النموذج وفقًا لمقياس محدد موصوف أيضًا في الورقة، مما يسمح بتدريب أكثر استقرارًا بمعدلات تعلم أعلى.
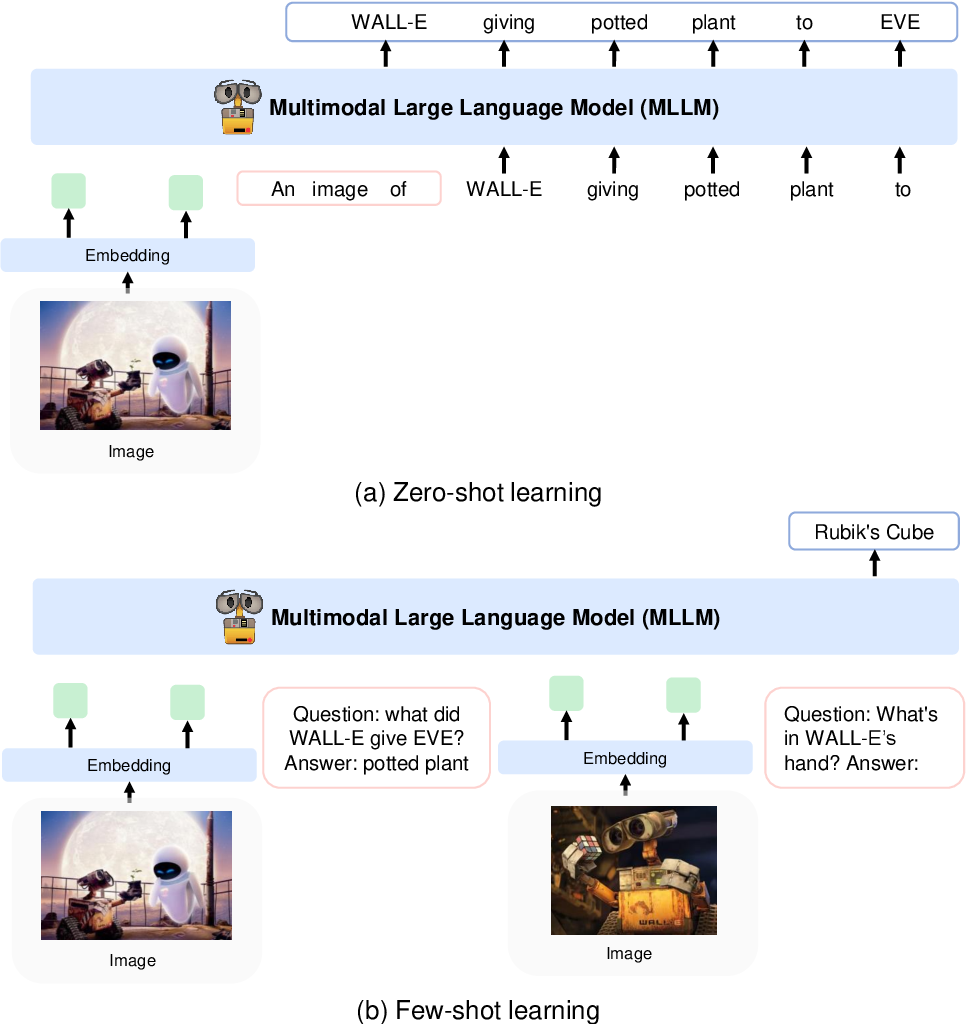
يقومون بتشفير الصور إلى ميزات الصورة باستخدام نموذج CLIP VIT-L/14 ويستخدمون أداة إعادة تشكيل المدرك المقدمة في Flamingo لتجميع ميزات الصورة من 256 -> 64 رمزًا مميزًا. يتم دمج ميزات الصورة مع تضمينات الرمز المميز عن طريق إضافتها إلى تسلسل الإدخال محاطًا برموز خاصة . على سبيل المثال
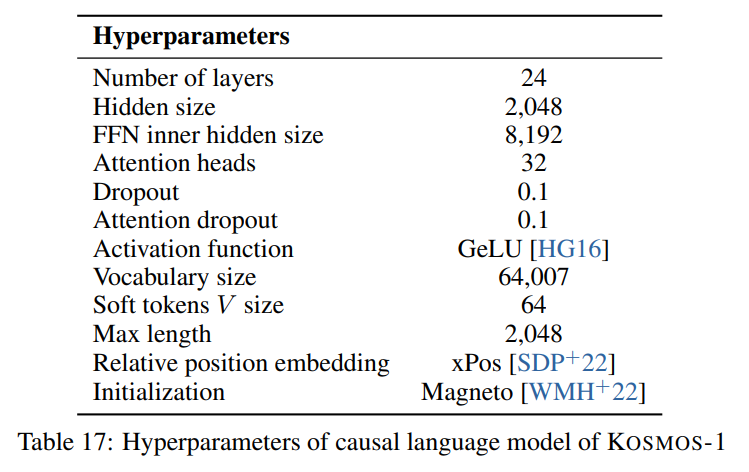
نحن نتبع المعلمات الفائقة الموضحة في الورقة الظاهرة في الصورة التالية:
نحن نستخدم تطبيق مقياس الشعلة لبنية المحولات الخاصة بجهاز فك التشفير فقط من Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)بالنسبة لنموذج الصورة (CLIP VIT-L/14) نستخدم نموذج OpenClip المُدرب مسبقًا:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]نحن نتبع المعلمات الفائقة الافتراضية لمعيد تشكيل المدرك حيث لا يتم تقديم معلمات مفرطة في الورقة:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) نظرًا لأن النموذج يتوقع بُعدًا مخفيًا هو 2048 ، فإننا نستخدم طبقة nn.Linear لعرض ميزات الصورة على البعد الصحيح وتهيئتها وفقًا لمخطط تهيئة Magneto:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) تصف الورقة قطعة جملة تحتوي على مفردات مكونة من 64007 رمزًا. من أجل البساطة (نظرًا لعدم توفر مجموعة التدريب لدينا)، نستخدم البديل التالي الأفضل مفتوح المصدر وهو أداة الرمز المميز T5 الكبيرة المُدربة مسبقًا من HuggingFace. يحتوي هذا الرمز المميز على مفردات تبلغ 32002 رمزًا.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "" , "" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) نقوم بعد ذلك بتضمين الرموز المميزة بطبقة nn.Embedding . نحن في الواقع نستخدم bnb.nn.Embedding من وحدات البت والبايت مما يسمح لنا باستخدام AdamW ذو 8 بتات لاحقًا.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)للتضمين الموضعي نستخدم:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)نضيف أيضًا طبقة إسقاط الإخراج لإسقاط البعد المخفي على حجم المفردات وتهيئته وفقًا لمخطط تهيئة Magneto:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) اضطررت إلى إجراء بعض التغييرات الطفيفة على وحدة فك التشفير للسماح لها بقبول الميزات المضمنة بالفعل في التمرير الأمامي. كان هذا ضروريًا للسماح بتسلسل الإدخال الأكثر تعقيدًا الموصوف أعلاه. تظهر التغييرات في الفرق التالي في السطر 391 من torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )فيما يلي جدول تخفيض السعر الذي يحتوي على البيانات الوصفية لمجموعات البيانات المذكورة في الورقة:
| مجموعة البيانات | وصف | مقاس | وصلة |
|---|---|---|---|
| الكومة | مجموعة نصية إنجليزية متنوعة | 800 جيجابايت | معانقة |
| الزحف المشترك | بيانات الزحف على الويب | - | الزحف المشترك |
| لايون-400 م | أزواج الصور والنص من الزحف المشترك | 400 مليون زوج | معانقة |
| لايون-2ب | أزواج الصور والنص من الزحف المشترك | أزواج 2B | أركايف |
| كويو | أزواج الصور والنص من الزحف المشترك | 700 مليون زوج | جيثب |
| التسميات التوضيحية المفاهيمية | أزواج النص البديل للصور | 15 مليون زوج | أركايف |
| بيانات CC المتداخلة | النص والصور من الزحف المشترك | 71 مليون وثيقة | مجموعة البيانات المخصصة |
| StoryCloze | المنطق المنطقي | 16 ألف أمثلة | مختارات الرباط الصليبي الأمامي |
| هيلاسواج | الفطرة السليمة NLI | 70 ألف أمثلة | أركايف |
| مخطط فينوغراد | غموض الكلمة | 273 أمثلة | بي كي آر آر 2012 |
| فينوغراندي | غموض الكلمة | 1.7 ألف أمثلة | AAAI 2020 |
| بيكا | ضمان الجودة المنطقية المادية | 16 ألف أمثلة | AAAI 2020 |
| BoolQ | ضمان الجودة | 15 ألف أمثلة | دوري أبطال آسيا 2019 |
| سي بي | استنتاج اللغة الطبيعية | 250 أمثلة | Sinn وBedeutung 2019 |
| قانون كوبا | الاستدلال السببي | 1 ألف أمثلة | ندوة الربيع AAAI 2011 |
| الحجم النسبي | المنطق المنطقي | 486 زوجا | آركايف 2016 |
| لون الذاكرة | المنطق المنطقي | 720 أمثلة | آركايف 2021 |
| مصطلحات اللون | المنطق المنطقي | 320 أمثلة | دوري أبطال آسيا 2012 |
| اختبار الذكاء | المنطق غير اللفظي | 50 أمثلة | مجموعة البيانات المخصصة |
| تعليق كوكو | تعليق الصورة | 413 ألف صورة | بامي 2015 |
| فليكر30ك | تعليق الصورة | 31 ألف صورة | تي سي ال 2014 |
| VQAv2 | ضمان الجودة البصرية | 1 مليون زوج ضمان الجودة | سي في بي آر 2017 |
| VizWiz | ضمان الجودة البصرية | 31 ألف زوج ضمان الجودة | سي في بي آر 2018 |
| WebSRC | ضمان الجودة على شبكة الإنترنت | 1.4 ألف أمثلة | EMNLP 2021 |
| إيماج نت | تصنيف الصور | 1.28 مليون صورة | سي في بي آر 2009 |
| شبل | تصنيف الصور | 200 نوع من الطيور | توج 2011 |
أباتشي
