nim anywhere
1.0.0

يرجى الانضمام إلى قناة #cdd-nim-anywhere Slack إذا كنت مستخدمًا داخليًا، وافتح مشكلة إذا كنت خارجيًا لأي سؤال أو تعليقات.
إحدى الفوائد الأساسية لاستخدام الذكاء الاصطناعي للمؤسسات هي قدرتها على العمل مع بياناتها الداخلية والتعلم منها. يعد توليد الاسترجاع المعزز (RAG) أحد أفضل الطرق للقيام بذلك. قامت NVIDIA بتطوير مجموعة من الخدمات الصغيرة تسمى خدمة NIM الصغيرة لمساعدة شركائنا وعملائنا على بناء خط أنابيب RAG فعال بسهولة.
يحتوي NIM Anywhere على كافة الأدوات المطلوبة لبدء دمج NIMs لـ RAG. إنه يمتد أصلاً إلى مختبرات كاملة الحجم ويصل إلى بيئات الإنتاج. هذه أخبار رائعة لبناء بنية RAG وإضافة NIMs بسهولة حسب الحاجة. إذا لم تكن معتادًا على RAG، فإنه يسترد ديناميكيًا المعلومات الخارجية ذات الصلة أثناء الاستدلال دون تعديل النموذج نفسه. تخيل أنك قائد التقنية لشركة لديها قاعدة بيانات محلية تحتوي على معلومات سرية وحديثة. لا تريد أن يصل OpenAI إلى بياناتك، لكنك تحتاج إلى النموذج لفهمها للإجابة على الأسئلة بدقة. الحل هو ربط نموذج اللغة الخاص بك بقاعدة البيانات وتزويدهم بالمعلومات.
لمعرفة المزيد حول سبب كون RAG حلاً ممتازًا لتعزيز دقة وموثوقية نماذج الذكاء الاصطناعي التوليدية لديك، اقرأ هذه المدونة.
ابدأ مع NIM Anywhere الآن باستخدام تعليمات البدء السريع وقم بإنشاء أول تطبيق RAG باستخدام NIMs!
للسماح لـ AI Workbench بالوصول إلى الموارد السحابية لـ NVIDIA، ستحتاج إلى تزويدها بمفتاح شخصي. تبدأ هذه المفاتيح بـ nvapi- .
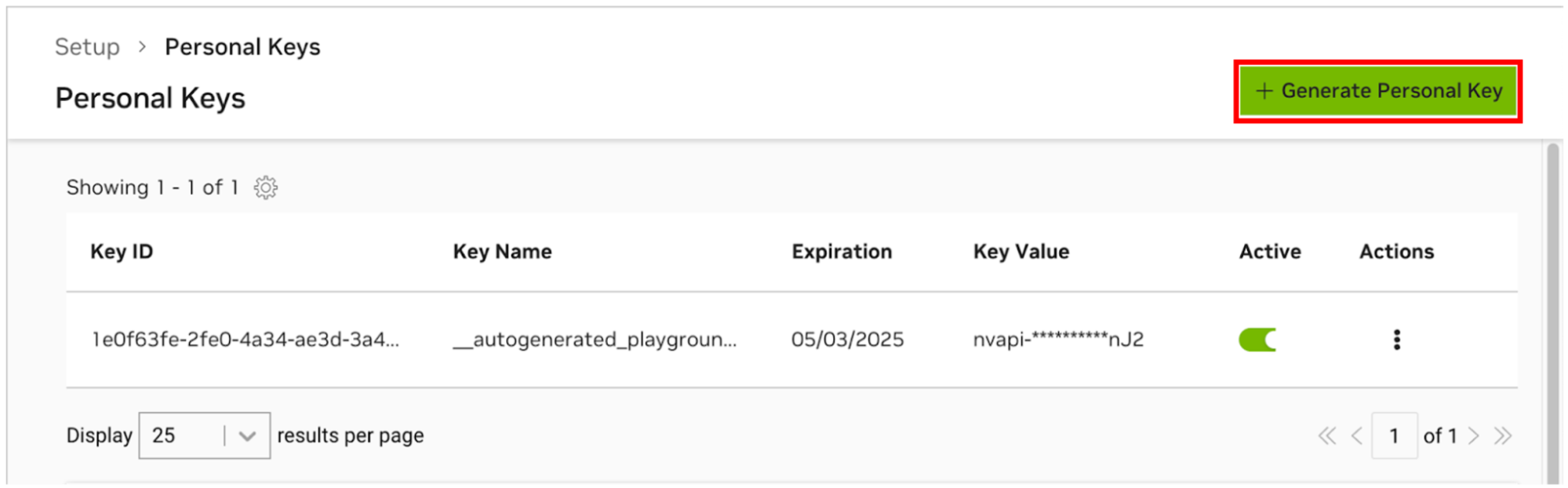
انتقل إلى NGC Personal Key Manager. إذا طُلب منك ذلك، فقم بالتسجيل للحصول على حساب جديد وقم بتسجيل الدخول.
تلميح يمكنك العثور على هذه الأداة عن طريق تسجيل الدخول إلى ngc.nvidia.com، وتوسيع قائمة ملف التعريف الخاص بك في الجزء العلوي الأيمن، وتحديد Setup ، ثم تحديد Generate Personal Key .
حدد إنشاء مفتاح شخصي .
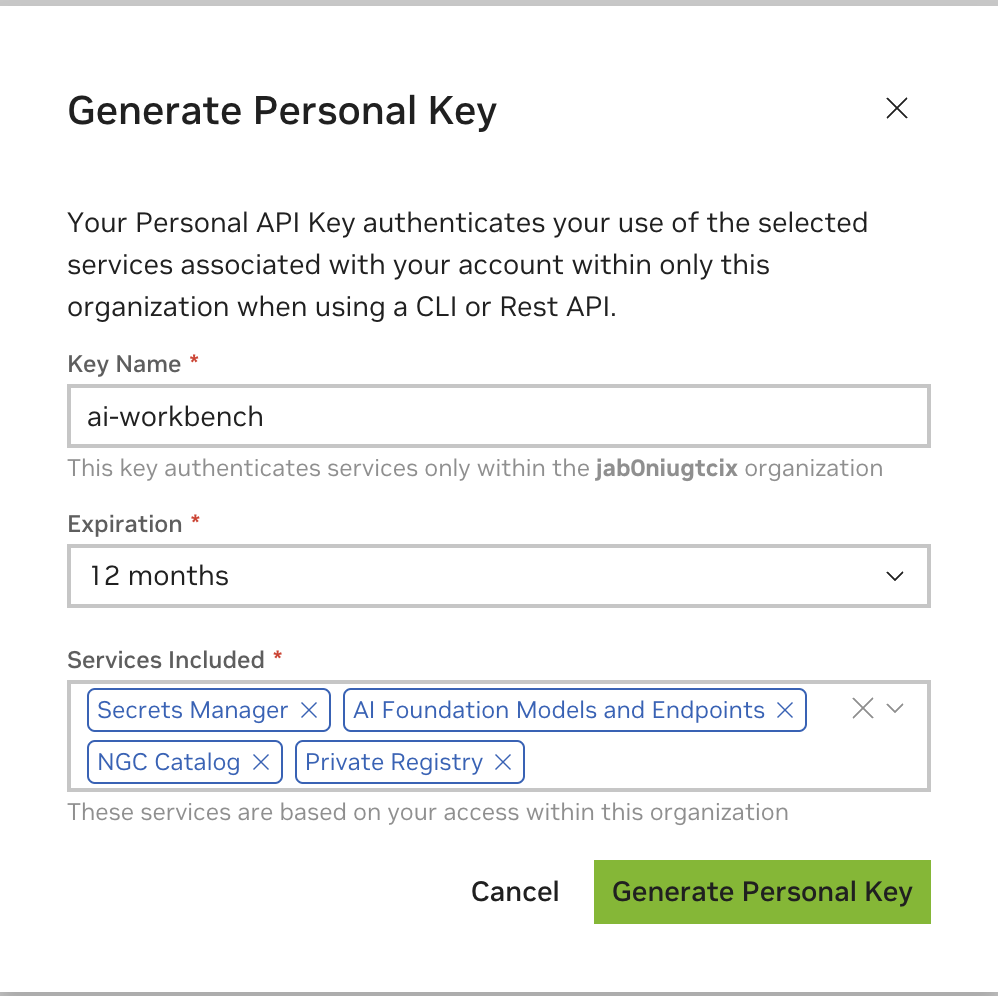
أدخل أي قيمة كاسم المفتاح، ولا بأس بانتهاء الصلاحية لمدة 12 شهرًا، ثم حدد كافة الخدمات. اضغط على "إنشاء مفتاح شخصي" عند الانتهاء.
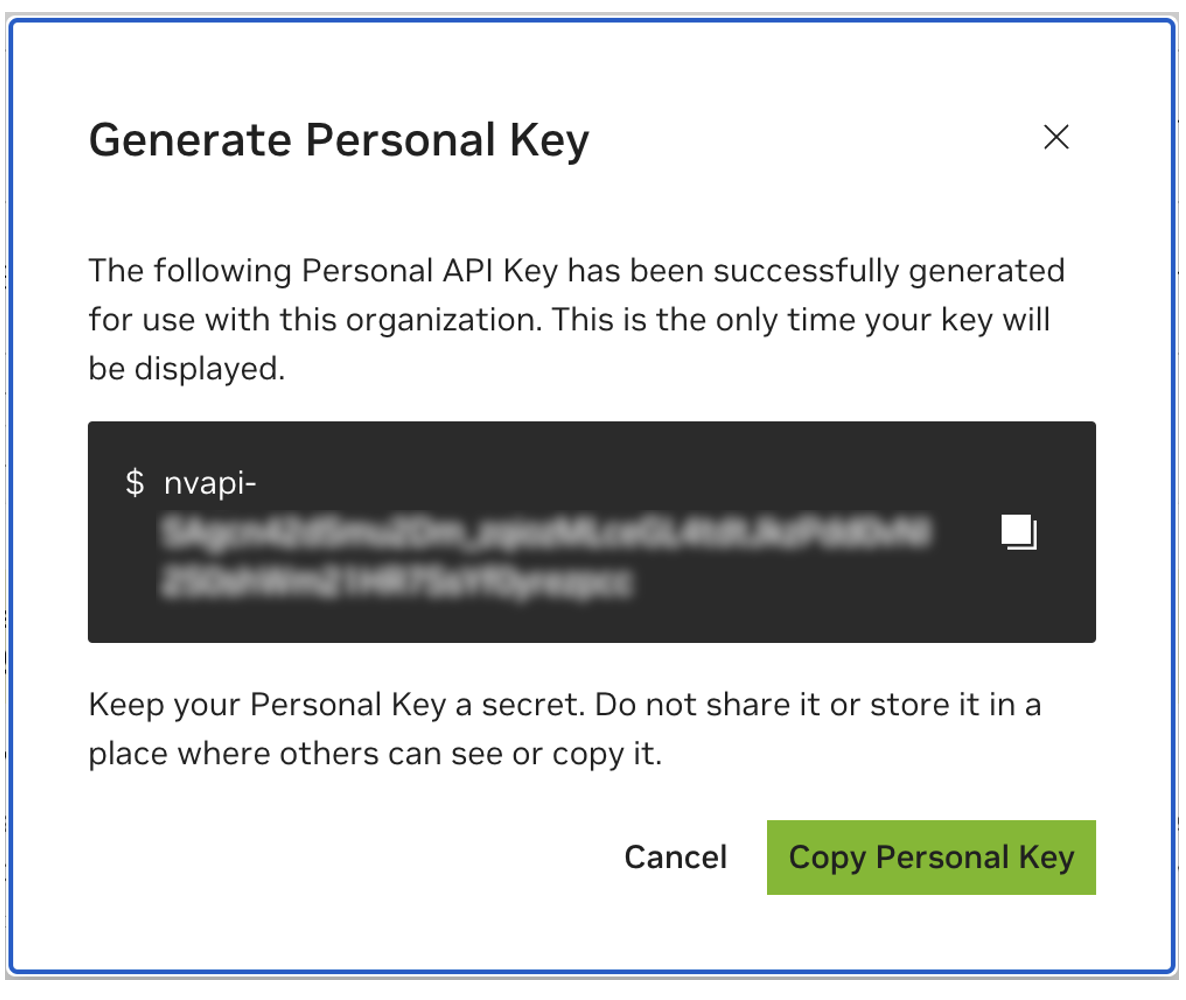
احفظ مفتاحك الشخصي لوقت لاحق. سوف يحتاجها Workbench ولا توجد طريقة لاستعادتها لاحقًا. في حالة فقدان المفتاح، يجب إنشاء مفتاح جديد. قم بحماية هذا المفتاح كما لو كان كلمة مرور.
تم تصميم هذا المشروع ليتم استخدامه مع NVIDIA AI Workbench. على الرغم من أن هذا ليس شرطًا، فإن تشغيل هذا العرض التوضيحي بدون AI Workbench سيتطلب عملاً يدويًا نظرًا لأن عمليات الأتمتة والتكامل التي تم تكوينها مسبقًا قد لا تكون متاحة.
سيفترض دليل البدء السريع هذا أنه يتم استخدام جهاز معمل عن بعد للتطوير وأن الجهاز المحلي هو عميل رفيع للوصول عن بعد إلى جهاز التطوير. وهذا يسمح لموارد الحوسبة بالبقاء في موقع مركزي وللمطورين أن يكونوا أكثر قابلية للتنقل. لاحظ أن جهاز المختبر البعيد يجب أن يقوم بتشغيل Ubuntu، لكن العميل المحلي يمكنه تشغيل Windows أو MacOS أو Ubuntu. لتثبيت هذا المشروع محليًا فقط، ما عليك سوى تخطي التثبيت عن بُعد.
مخطط انسيابي LR
محلي
بيئة معمل الرسم البياني الفرعي
آلة المختبر عن بعد
نهاية
جهاز <-.ssh.-> المحلي
Ubuntu مطلوب إذا كان العميل المحلي سيتم استخدامه أيضًا للمطور. عند استخدام جهاز مختبر عن بعد، يمكن أن يكون Windows أو MacOS أو Ubuntu.
للحصول على التعليمات الكاملة، راجع دليل مستخدم NVIDIA AI Workbench.
تثبيت البرامج المطلوبة
قم بتنزيل برنامج التثبيت NVIDIA AI Workbench وقم بتنفيذه. قم بتخويل Windows للسماح للمثبت بإجراء التغييرات.
اتبع الإرشادات الموجودة في معالج التثبيت. إذا كنت بحاجة إلى تثبيت WSL2، قم بتفويض Windows لإجراء التغييرات وإعادة تشغيل الجهاز المحلي عند الطلب. عند إعادة تشغيل النظام، يجب أن يتم استئناف برنامج تثبيت NVIDIA AI Workbench تلقائيًا.
حدد Docker باعتباره وقت تشغيل الحاوية الخاصة بك.
قم بتسجيل الدخول إلى حساب GitHub الخاص بك باستخدام خيار تسجيل الدخول من خلال GitHub.com .
أدخل معلومات مؤلف git إذا طلب ذلك.
للحصول على التعليمات الكاملة، راجع دليل مستخدم NVIDIA AI Workbench.
تثبيت البرامج المطلوبة
قم بتنزيل صورة قرص NVIDIA AI Workbench (ملف .dmg ) وافتحها.
اسحب AI Workbench إلى مجلد التطبيقات وقم بتشغيل NVIDIA AI Workbench من مشغل التطبيق. 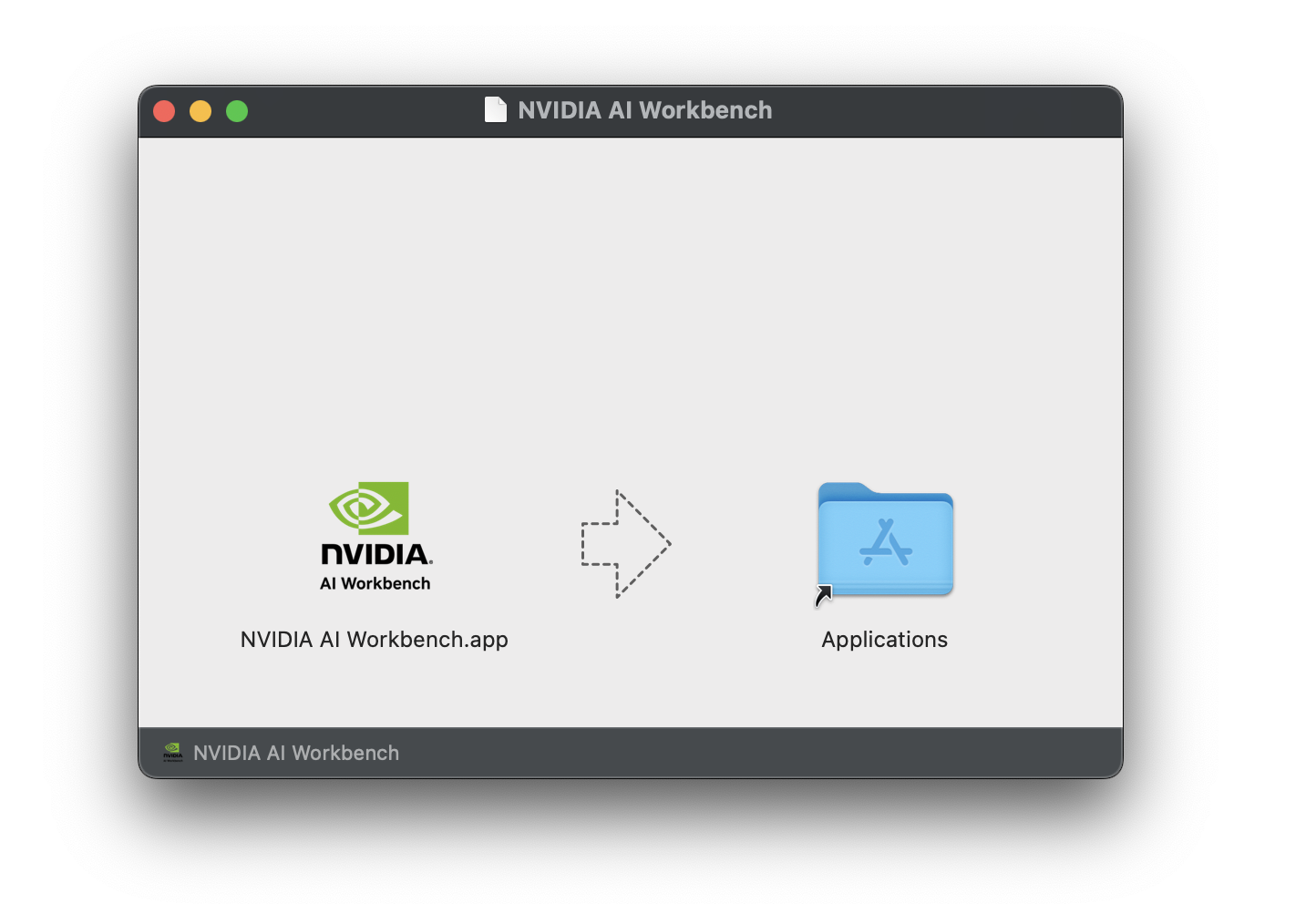
حدد Docker باعتباره وقت تشغيل الحاوية الخاصة بك.
قم بتسجيل الدخول إلى حساب GitHub الخاص بك باستخدام خيار تسجيل الدخول من خلال GitHub.com .
أدخل معلومات مؤلف git إذا طلب ذلك.
للحصول على التعليمات الكاملة، راجع دليل مستخدم NVIDIA AI Workbench. قم بتشغيل هذا التثبيت باسم المستخدم الذي سيكون Workbench المستخدم. لا تقم بتشغيل هذه الخطوات root .
تثبيت البرامج المطلوبة
قم بتنزيل برنامج التثبيت NVIDIA AI Workbench، واجعله قابلاً للتنفيذ، ثم قم بتشغيله. يمكنك جعل الملف قابلاً للتنفيذ باستخدام الأمر التالي:
chmod +x NVIDIA-AI-Workbench- * .AppImageسيقوم AI Workbench بتثبيت برامج تشغيل NVIDIA لك (إذا لزم الأمر). ستحتاج إلى إعادة تشغيل جهازك المحلي بعد تثبيت برامج التشغيل ثم إعادة تشغيل تثبيت AI Workbench بالنقر المزدوج فوق أيقونة NVIDIA AI Workbench على سطح المكتب.
حدد Docker باعتباره وقت تشغيل الحاوية الخاصة بك.
قم بتسجيل الدخول إلى حساب GitHub الخاص بك باستخدام خيار تسجيل الدخول من خلال GitHub.com .
أدخل معلومات مؤلف git إذا طلب ذلك.
يتم دعم Ubuntu فقط للأجهزة البعيدة.
للحصول على التعليمات الكاملة، راجع دليل مستخدم NVIDIA AI Workbench. قم بتشغيل هذا التثبيت باسم المستخدم الذي سيستخدم Workbench. لا تقم بتشغيل هذه الخطوات root .
تأكد من تمكين المصادقة المستندة إلى مفتاح SSH من الجهاز المحلي إلى الجهاز البعيد. إذا لم يكن هذا ممكّنًا حاليًا، فستقوم الأوامر التالية بتمكين ذلك في معظم المواقف. قم بتغيير REMOTE_USER و REMOTE-MACHINE ليعكس عنوانك البعيد.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINESSH في المضيف البعيد. ثم استخدم الأوامر التالية لتنزيل وتنفيذ NVIDIA AI Workbench Installer.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installسيقوم AI Workbench بتثبيت برامج تشغيل NVIDIA لك (إذا لزم الأمر). ستحتاج إلى إعادة تشغيل جهازك البعيد بعد تثبيت برامج التشغيل ثم إعادة تشغيل تثبيت AI Workbench عن طريق إعادة تشغيل الأوامر في الخطوة السابقة.
حدد Docker باعتباره وقت تشغيل الحاوية الخاصة بك.
قم بتسجيل الدخول إلى حساب GitHub الخاص بك باستخدام خيار تسجيل الدخول من خلال GitHub.com .
أدخل معلومات مؤلف git إذا طلب ذلك.
بمجرد اكتمال التثبيت عن بعد، يمكن إضافة الموقع البعيد إلى مثيل AI Workbench المحلي. افتح تطبيق AI Workbench، وانقر فوق Add Remote Location ، ثم أدخل المعلومات المطلوبة. عند الانتهاء، انقر فوق "إضافة موقع" .
REMOTE-MACHINE .REMOTE_USER ./home/USER/.ssh/id_rsa .هناك طريقتان لتنزيل هذا المشروع للاستخدام المحلي: Cloning وForking.
يعد استنساخ هذا المستودع هو الطريقة الموصى بها للبدء. لن يسمح هذا بإجراء تعديلات محلية، ولكنه الأسرع للبدء. يتيح هذا أيضًا أسهل طريقة لسحب التحديثات.
يوصى بتقسيم هذا المستودع للتطوير حيث سيكون من الممكن حفظ التغييرات. ومع ذلك، للحصول على التحديثات، سيتعين على مشرف الشوكة أن يسحب بانتظام من الريبو المنبع. للعمل من شوكة، اتبع تعليمات GitHub ثم قم بالإشارة إلى عنوان URL للشوكة الشخصية الخاصة بك في بقية هذا القسم.
افتح نافذة NVIDIA AI Workbench المحلية. من قائمة المواقع المعروضة، حدد إما الموقع البعيد الذي قمت بإعداده للتو، أو الموقع المحلي إذا كنت ستعمل محليًا.
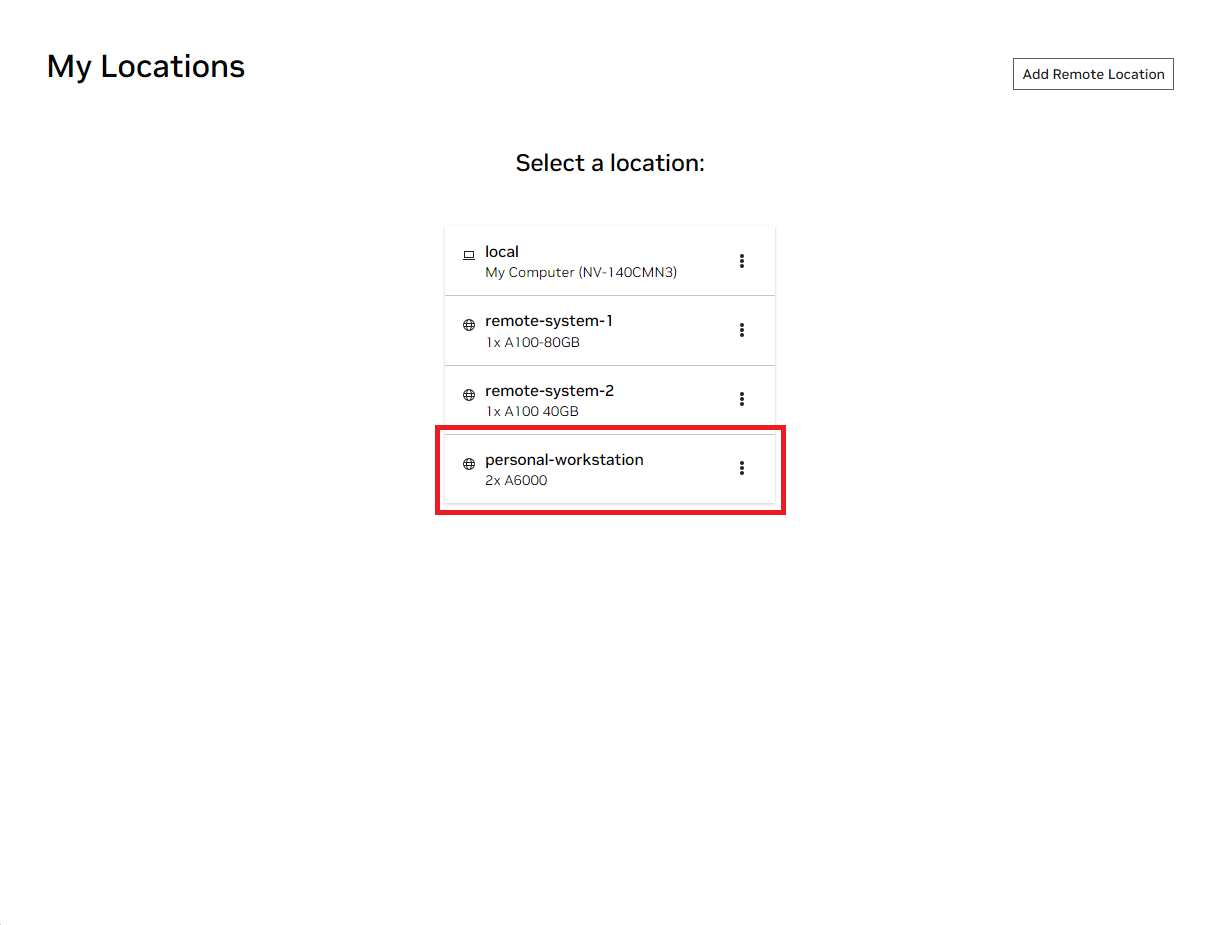
بمجرد دخولك إلى الموقع، حدد Clone Project .
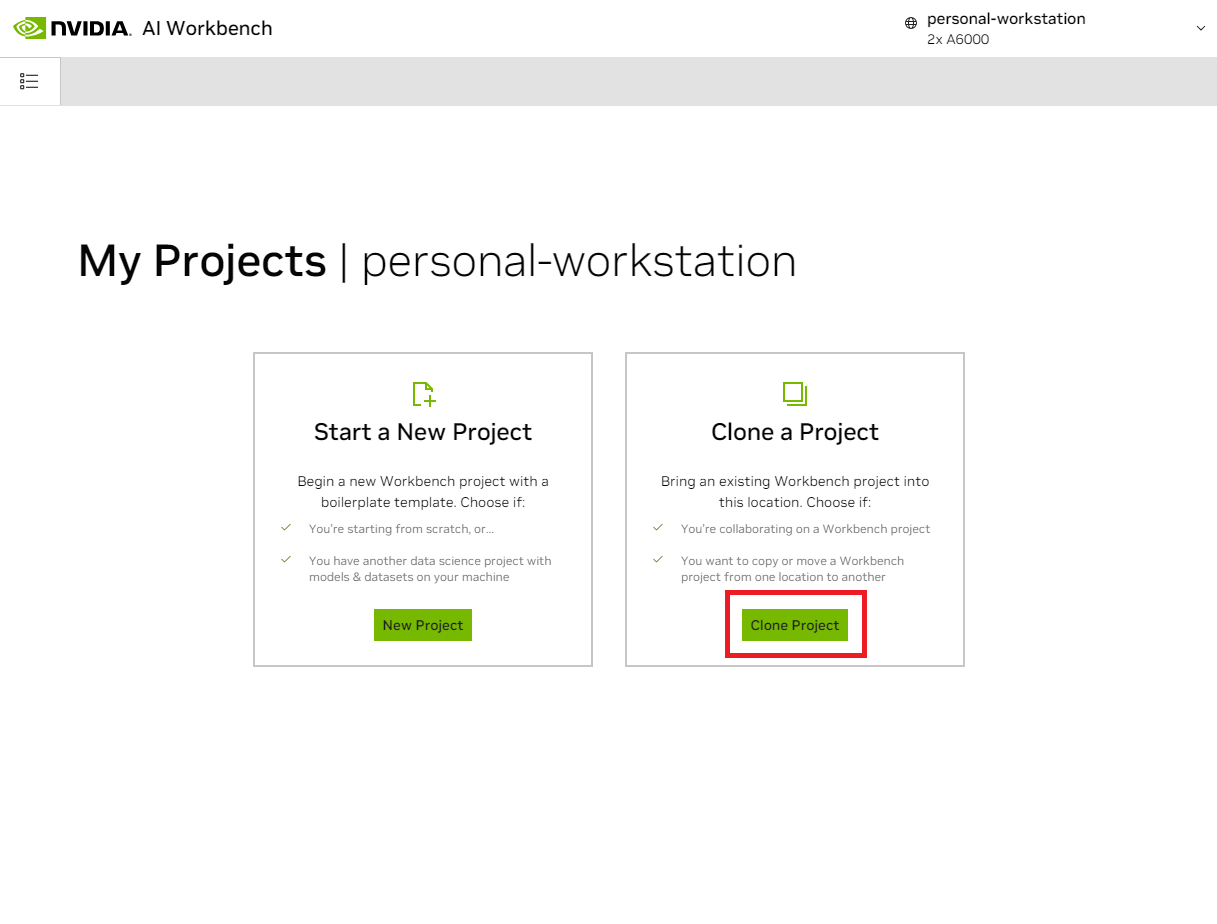
في النافذة المنبثقة "Clone Project"، قم بتعيين عنوان URL للمستودع على https://github.com/NVIDIA/nim-anywhere.git . يمكنك ترك المسار باعتباره المسار الافتراضي لـ /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git . انقر فوق استنساخ .`
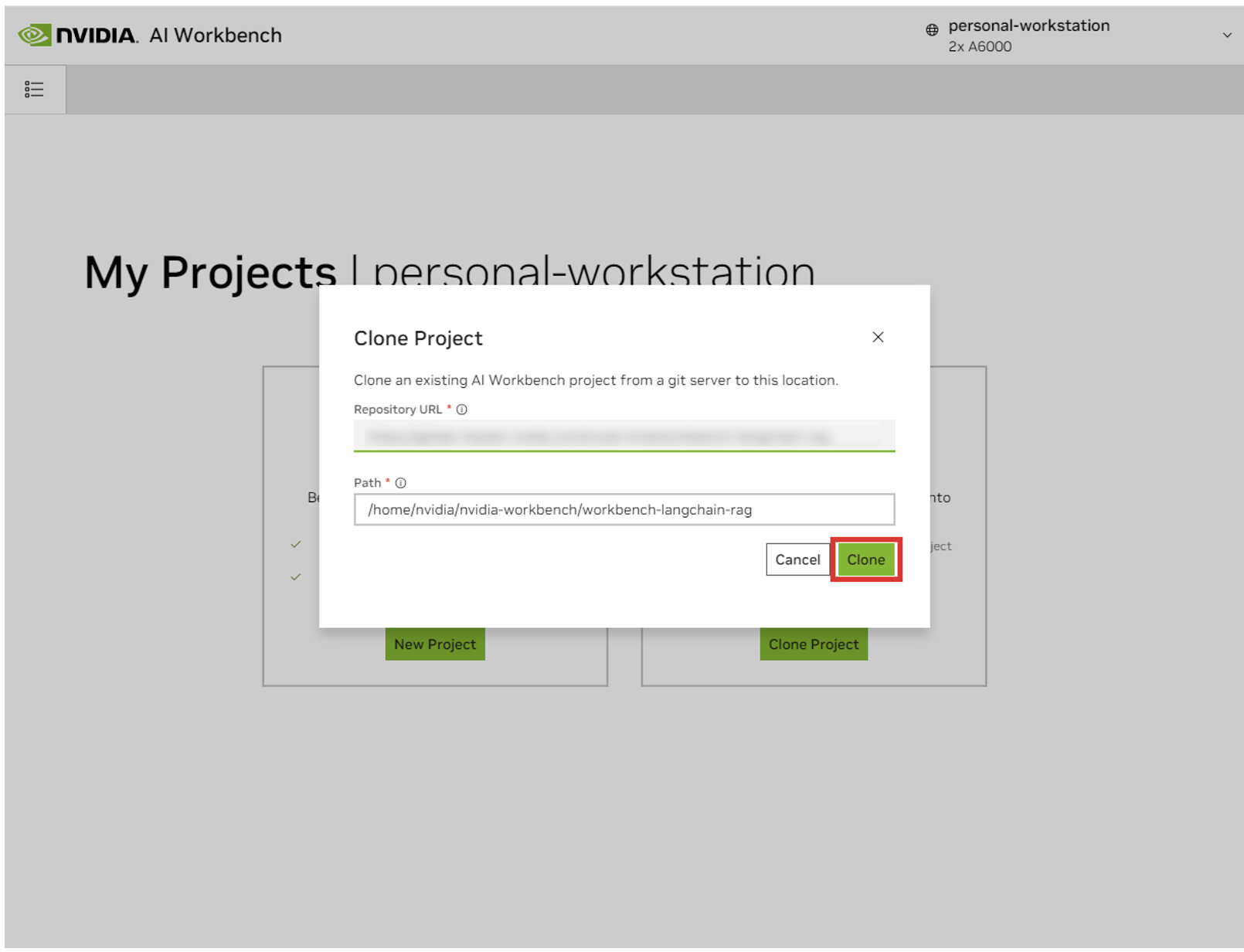
ستتم إعادة توجيهك إلى صفحة المشروع الجديد. سيقوم Workbench تلقائيًا بتمهيد بيئة التطوير. يمكنك عرض التقدم في الوقت الفعلي عن طريق توسيع الإخراج من أسفل النافذة.
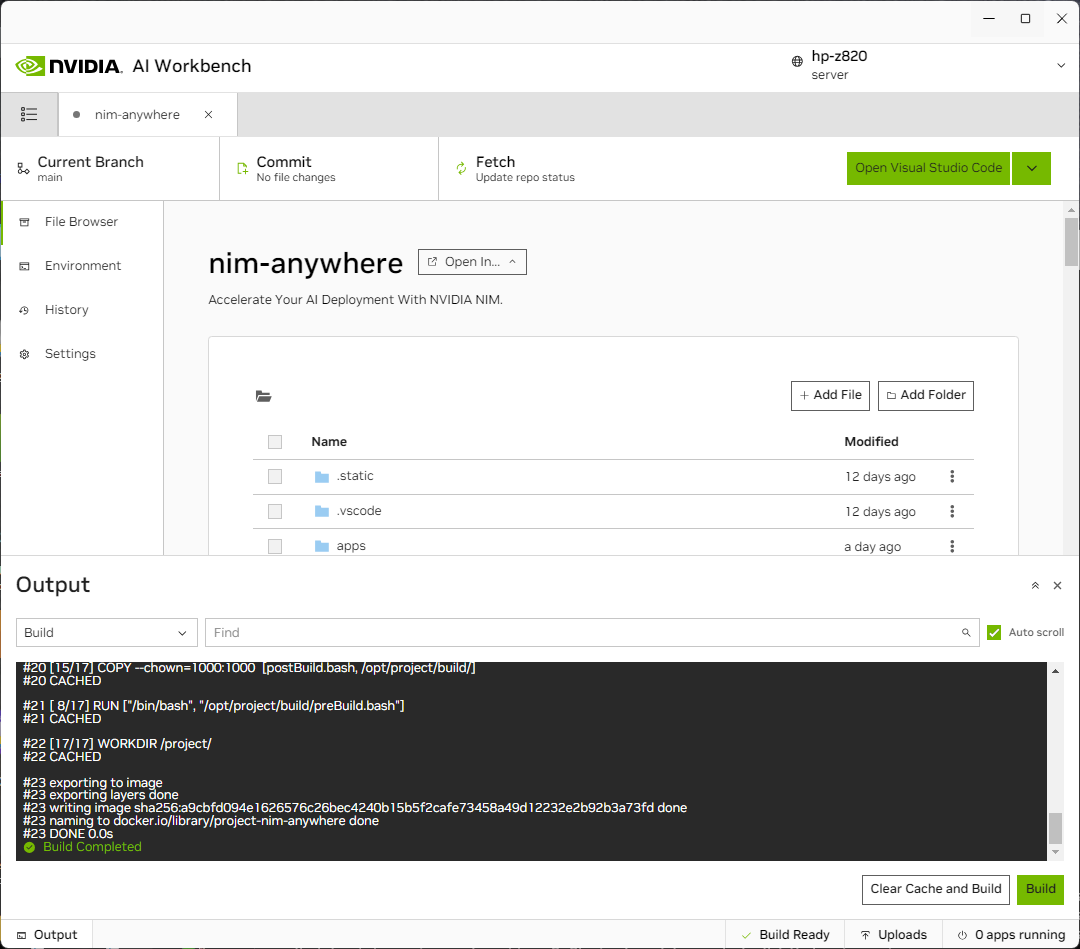
يجب تكوين المشروع للعمل مع موارد الجهاز المحلي.
قبل التشغيل لأول مرة، يجب توفير التكوين الخاص بالمشروع. يتم تكوين المشروع باستخدام علامة التبويب "البيئة" من اللوحة اليمنى.
قم بالتمرير لأسفل إلى قسم المتغيرات وابحث عن إدخال NGC_HOME . يجب ضبطه على شيء مثل ~/.cache/nvidia-nims . يتم استخدام القيمة هنا بواسطة Workbench. يظهر نفس الموقع أيضًا في قسم Mounts الذي يقوم بتثبيت هذا الدليل في الحاوية.
قم بالتمرير لأسفل إلى قسم "الأسرار" وابحث عن إدخال NGC_API_KEY . اضغط على "تكوين" وقم بتوفير المفتاح الشخصي لـ NGC الذي تم إنشاؤه مسبقًا.
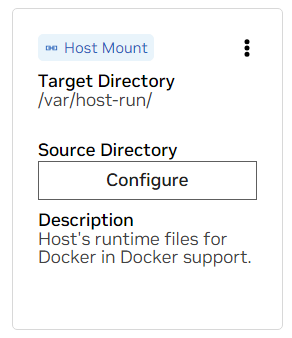
قم بالتمرير لأسفل إلى قسم الجبال . هنا، هناك نوعان من الحوامل لتكوينها.
أ. ابحث عن أداة التثبيت لـ /var/host-run. يُستخدم هذا للسماح لبيئة التطوير بالوصول إلى البرنامج الخفي Docker الخاص بالمضيف في نمط يسمى Docker out of Docker. اضغط على "تكوين" وقم بتوفير الدليل /var/run .
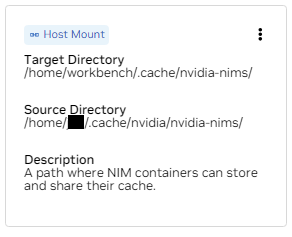
ب. ابحث عن أداة التثبيت لـ /home/workbench/.cache/nvidia-nims. يتم استخدام هذا التحميل كذاكرة تخزين مؤقت لوقت التشغيل لـ NIMs حيث يمكنهم تخزين ملفات النماذج مؤقتًا. تؤدي مشاركة ذاكرة التخزين المؤقت هذه مع المضيف إلى تقليل استخدام القرص وعرض النطاق الترددي للشبكة.
إذا لم يكن لديك ذاكرة تخزين مؤقت مؤقتة بالفعل، أو لم تكن متأكدًا، فاستخدم الأوامر التالية لإنشاء واحدة على /home/USER/.cache/nvidia-nims .
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsستتم إعادة البناء بعد تغيير هذه الإعدادات.
بمجرد اكتمال البناء برسالة Build Ready ، ستكون جميع التطبيقات متاحة لك.
حتى أبسط سلاسل LLM تعتمد على عدد قليل من الخدمات الصغيرة الإضافية. ويمكن تجاهل ذلك أثناء تطوير البدائل الموجودة في الذاكرة، ولكن بعد ذلك يلزم إجراء تغييرات على التعليمات البرمجية للانتقال إلى الإنتاج. لحسن الحظ، يقوم Workbench بإدارة تلك الخدمات الصغيرة الإضافية لبيئات التطوير.
تلميح: بالنسبة لكل تطبيق، يمكن مراقبة إخراج التصحيح في واجهة المستخدم عن طريق النقر فوق رابط الإخراج في الزاوية اليسرى السفلية، وتحديد القائمة المنسدلة، واختيار التطبيق محل الاهتمام.
يمكن التحكم في جميع التطبيقات المجمعة في مساحة العمل هذه بالانتقال إلى البيئة > التطبيقات .
أولاً، قم بالتبديل بين Milvus Vector DB و Redis . يتم استخدام Milvus كقاعدة معرفية غير منظمة ويستخدم Redis لتخزين تواريخ المحادثات.
بمجرد بدء هذه الخدمات، يمكن تشغيل Chain Server بأمان. يحتوي هذا على رمز LangChain المخصص لتنفيذ سلسلة الاستدلال الخاصة بنا. افتراضيًا، سيستخدم Milvus وRedis المحلي، لكنه سيستخدم ai.nvidia.com لاستدلال نماذج LLM وEmbedding.
[اختياري]: بعد ذلك، ابدأ LLM NIM . في المرة الأولى التي يتم فيها تشغيل LLM NIM، سيستغرق تنزيل الصورة والنماذج المحسنة بعض الوقت.
أ. أثناء بداية طويلة، للتأكد من بدء LLM NIM، يمكن ملاحظة التقدم من خلال عرض السجلات باستخدام جزء الإخراج في الجزء السفلي الأيسر من واجهة المستخدم.
ب. إذا كانت السجلات تشير إلى خطأ في المصادقة، فهذا يعني أن NGC_API_KEY المقدم لا يمكنه الوصول إلى NIMs. يرجى التحقق من أنه تم إنشاؤه بشكل صحيح وفي مؤسسة NGC التي تتمتع بدعم NVIDIA AI Enterprise أو النسخة التجريبية.
ج. إذا بدت السجلات عالقة في ..........: Pull complete . ..........: Verifying complete ، أو ..........: Download complete ؛ هذا كله ناتج طبيعي من Docker حيث تم تنزيل الطبقات المختلفة لصورة الحاوية.
د. أي إخفاقات أخرى هنا تحتاج إلى معالجة.
بمجرد تشغيل Chain Server ، يمكن بدء تشغيل واجهة الدردشة . سيؤدي بدء تشغيل الواجهة إلى فتحها تلقائيًا في نافذة المتصفح.
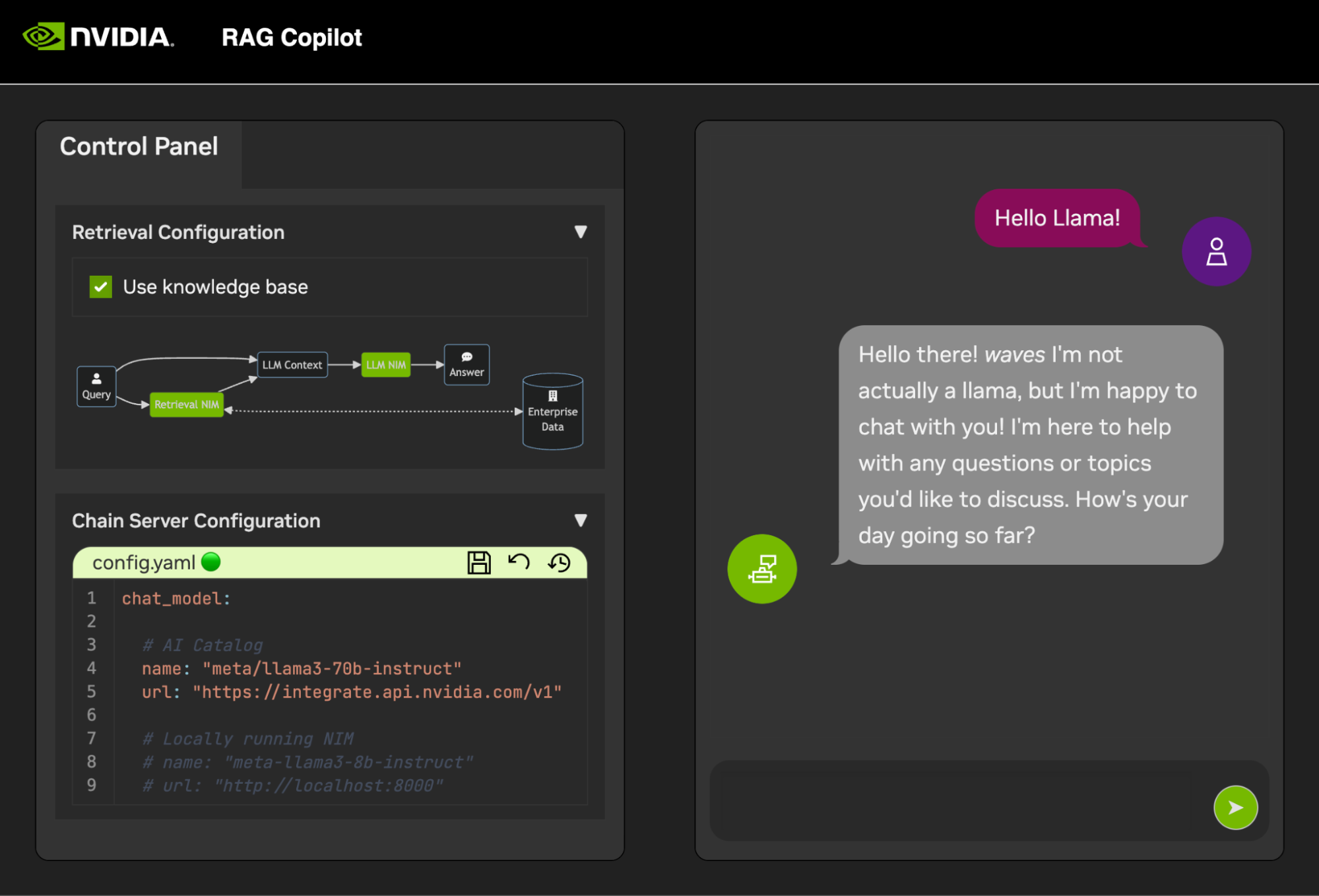
للبدء في تطوير العروض التوضيحية، يتم توفير مجموعة بيانات نموذجية مع Jupyter Notebook يوضح كيفية استيعاب البيانات في قاعدة بيانات المتجهات.
لاستيراد وثائق PDF إلى قاعدة بيانات المتجهات، افتح Jupyter باستخدام مشغل التطبيق في AI Workbench.
استخدم Jupyter Notebook على code/upload-pdfs.ipynb لاستيعاب مجموعة البيانات الافتراضية. في حالة استخدام مجموعة البيانات الافتراضية، لا يلزم إجراء أي تغييرات.
في حالة استخدام مجموعة بيانات مخصصة، قم بتحميلها إلى دليل data/ في Jupyter وقم بتعديل دفتر الملاحظات المقدم حسب الضرورة.
يحتوي هذا المشروع على تطبيقات لعدد قليل من الخدمات التجريبية بالإضافة إلى عمليات التكامل مع الخدمات الخارجية. يتم تنسيق كل ذلك بواسطة NVIDIA AI Workbench.
الخدمات التجريبية كلها في مجلد code . يحتوي المستوى الجذر لمجلد التعليمات البرمجية على عدد قليل من دفاتر الملاحظات التفاعلية المخصصة للتعمق التقني. يعد Chain Server نموذجًا لتطبيق يستخدم NIMs مع LangChain. (لاحظ أن Chain Server هنا يمنحك خيار التجربة باستخدام RAG وبدونه). يحتوي مجلد Chat Frontend على خادم واجهة مستخدم تفاعلي لممارسة خادم السلسلة. وأخيرًا، يتم توفير نماذج من دفاتر الملاحظات في دليل التقييم لتوضيح نقاط الاسترجاع والتحقق من صحتها.
com.mindmap
الجذر ((منضدة الذكاء الاصطناعي))
الخدمات التجريبية
خادم السلسلة<br />LangChain + NIMs
الواجهة الأمامية<br />واجهة المستخدم التجريبية التفاعلية
التقييم<br />التحقق من صحة النتائج
أجهزة الكمبيوتر المحمولة<br />الاستخدام المتقدم
التكامل
Redis</br>سجل المحادثات
Milvus</br>قاعدة بيانات المتجهات
LLM NIM</br> LLMs الأمثل
يمكن تكوين Chain Server إما بملف تكوين أو بمتغيرات البيئة.
افتراضيًا، سيبحث التطبيق عن ملف التكوين في كافة المواقع التالية. إذا تم العثور على ملفات تكوين متعددة، فستكون للقيم من الملفات الأدنى في القائمة الأولوية.
يمكن تحديد مسار ملف تكوين إضافي من خلال متغير بيئة يسمى APP_CONFIG . ستكون للقيمة الموجودة في هذا الملف الأولوية على جميع مواقع الملفات الافتراضية.
export APP_CONFIG=/etc/my_config.yaml يمكن أيضًا ضبط التكوين باستخدام متغيرات البيئة. ستكون أسماء المتغيرات على الشكل التالي: APP_FIELD__SUB_FIELD القيم المحددة كمتغيرات بيئة ستكون لها الأولوية على كافة القيم من الملفات.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
تحتوي الواجهة الأمامية للدردشة أيضًا على عدد قليل من خيارات التكوين. يمكن ضبطها بنفس طريقة ضبط الخادم المتسلسل.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
جميع ردود الفعل والمساهمات في هذا المشروع هي موضع ترحيب. عند إجراء تغييرات على هذا المشروع، سواء للاستخدام الشخصي أو للمساهمة، فمن المستحسن العمل على شوكة في هذا المشروع. بمجرد اكتمال التغييرات على الفورك، يجب فتح طلب دمج.
تمت تهيئة هذا المشروع باستخدام Linters التي تم ضبطها لمساعدة التعليمات البرمجية على البقاء متسقة دون أن تكون مرهقة للغاية. نستخدم اللينترات التالية:
تم تكوين بيئة VSCode المضمنة لتشغيل الفحص والتحقق في الوقت الفعلي.
لتشغيل الفحص الذي يتم إجراؤه بواسطة خطوط أنابيب CI يدويًا، قم بتنفيذ /project/code/tools/lint.sh . يمكن إجراء الاختبارات الفردية عن طريق تحديدها بالاسم: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . سيؤدي تشغيل أداة الوبر في وضع الإصلاح إلى تصحيح ما يمكن فعله تلقائيًا عن طريق تشغيل Black، وتحديث الملف README، ومسح مخرجات الخلية على جميع أجهزة Jupyter Notebooks.
تم تصميم الواجهة الأمامية في محاولة لتقليل تطوير HTML وJavascript المطلوب. يتم توفير غلاف تطبيق ذو علامة تجارية ومصمم تم إنشاؤه باستخدام HTML وJavascript وCSS. لقد تم تصميمه ليكون سهل التخصيص، ولكن لا ينبغي أبدًا أن يكون مطلوبًا. يتم إنشاء جميع المكونات التفاعلية للواجهة الأمامية في Gradio ويتم تثبيتها في غلاف التطبيق باستخدام إطارات iframe.
توجد على طول الجزء العلوي من غلاف التطبيق قائمة تسرد طرق العرض المتاحة. قد يكون لكل طريقة عرض تخطيطها الخاص الذي يتكون من صفحة واحدة أو بضع صفحات.
تحتوي الصفحات على المكونات التفاعلية للعرض التوضيحي. رمز الصفحات موجود في دليل code/frontend/pages . لإنشاء صفحة جديدة:
__init__.py في الدليل الجديد الذي يستخدم Gradio لتعريف واجهة المستخدم. يجب تحديد تخطيط Gradio Blocks في متغير يسمى page .chat للحصول على مثال.code/frontend/pages/__init__.py ، واستورد الصفحة الجديدة، وأضف الصفحة الجديدة إلى القائمة __all__ .ملاحظة: لن يؤدي إنشاء صفحة جديدة إلى إضافتها إلى الواجهة الأمامية. ويجب إضافته إلى طريقة العرض حتى يظهر على الواجهة الأمامية.
يتكون العرض من صفحة واحدة أو بضع صفحات ويجب أن يعمل بشكل مستقل عن بعضها البعض. يتم تعريف جميع طرق العرض في الوحدة النمطية code/frontend/server.py . ستتم إضافة جميع طرق العرض المعلنة تلقائيًا إلى شريط قوائم الواجهة الأمامية وإتاحتها في واجهة المستخدم.
لتحديد طريقة عرض جديدة، قم بتعديل القائمة المسماة views . هذه قائمة View الكائنات. سيحدد ترتيب الكائنات ترتيبها في قائمة الواجهة الأمامية. سيكون العرض المحدد الأول هو العرض الافتراضي.
تصف كائنات العرض اسم العرض والتخطيط. ويمكن إعلانها على النحو التالي:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) جميع إعلانات الصفحة، View.left أو View.right ، اختيارية. إذا لم يتم الإعلان عنها، فسيتم إخفاء إطارات iframe المرتبطة بها في تخطيط الويب. سيتم توسيع إطارات iframe الأخرى لملء الفجوات. توضح الرسوم البيانية التالية التخطيطات المختلفة.
كتلة بيتا
الأعمدة 1
القائمة["شريط القوائم"]
حاجز
الأعمدة 2
اليسار واليمين
نهاية
كتلة بيتا
الأعمدة 1
القائمة["شريط القوائم"]
حاجز
الأعمدة 1
اليسار:1
نهاية
تحتوي الواجهة الأمامية على عدد قليل من الأصول ذات العلامات التجارية التي يمكن تخصيصها لحالات استخدام مختلفة.
تحتوي الواجهة الأمامية على شعار في أعلى يسار الصفحة. لتعديل الشعار، يلزم وجود صورة SVG للشعار المطلوب. يمكن بعد ذلك تعديل غلاف التطبيق بسهولة لاستخدام ملف SVG الجديد عن طريق تعديل ملف code/frontend/_assets/index.html . يوجد div واحد بمعرف logo . يحتوي هذا المربع على ملف SVG واحد. قم بتحديث هذا إلى تعريف SVG المطلوب.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > يتم تعريف تصميم App Shell في code/frontend/_static/css/style.css . قد يتم تعديل الألوان الموجودة في هذا الملف بأمان.
يتم تعريف تصميم الصفحات المختلفة في code/frontend/pages/*/*.css . قد تتطلب هذه الملفات أيضًا تعديلًا لأنظمة الألوان المخصصة.
يتم تعريف سمة Gradio في code/frontend/_assets/theme.json . يمكن تعديل الألوان الموجودة في هذا الملف بأمان إلى العلامة التجارية المطلوبة. قد يتم أيضًا تغيير الأنماط الأخرى في هذا الملف، ولكنها قد تتسبب في حدوث تغييرات جذرية في الواجهة الأمامية. تحتوي وثائق Gradio على مزيد من المعلومات حول سمات Gradio.
ملاحظة: هذا موضوع متقدم لن يطلبه معظم المطورين أبدًا.
في بعض الأحيان، قد يكون من الضروري وجود صفحات متعددة في طريقة عرض تتواصل مع بعضها البعض. لهذا الغرض، يتم استخدام إطار مراسلة postMessage الخاص بـ Javascript. ستتم إعادة توجيه أي رسالة موثوقة يتم نشرها على غلاف التطبيق إلى كل إطار iframe حيث يمكن للصفحات التعامل مع الرسالة حسب الرغبة. تستخدم صفحة control هذه الميزة لتعديل تكوين صفحة chat .
سيقوم ما يلي بنشر رسالة إلى غلاف التطبيق ( window.top ). ستحتوي الرسالة على قاموس بالمفتاح use_kb وقيمة true. باستخدام Gradio، يمكن تنفيذ Javascript بواسطة أي حدث Gradio.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; سيتم إرسال هذه الرسالة تلقائيًا إلى جميع الصفحات بواسطة غلاف التطبيق. سوف يستهلك نموذج التعليمات البرمجية التالي الرسالة على صفحة أخرى. سيتم تشغيل هذا الرمز بشكل غير متزامن عند تلقي حدث message . إذا كانت الرسالة موثوقة، فسيتم تحديث مكون Gradio باستخدام elem_id الخاص بـ use_kb إلى القيمة المحددة في الرسالة. بهذه الطريقة، يمكن تكرار قيمة مكون Gradio عبر الصفحات.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; يتم عرض الملف README تلقائيًا؛ سيتم الكتابة فوق التعديلات المباشرة. من أجل تعديل الملف README، ستحتاج إلى تحرير الملفات الخاصة بكل قسم على حدة. سيتم دمج كل هذه الملفات وسيتم إنشاء الملف README تلقائيًا. يمكنك العثور على جميع الملفات ذات الصلة في مجلد docs .
تتم كتابة الوثائق في Github Flavoured Markdown ثم يتم تقديمها إلى ملف Markdown النهائي بواسطة Pandoc. يتم تعريف تفاصيل هذه العملية في Makefile. يتم تحديد ترتيب الملفات التي تم إنشاؤها في docs/_TOC.md . يمكن معاينة الوثائق في نافذة متصفح ملف Workbench.
ملف الرأس هو الملف الأول المستخدم لتجميع الوثائق. يمكن العثور على هذا الملف على docs/_HEADER.md . سيتم كتابة محتويات هذا الملف حرفيًا، دون أي تلاعب، إلى الملف التمهيدي (README) قبل أي شيء آخر.
يحتوي ملف الملخص على وصف سريع ورسم يصف هذا المشروع. ستتم إضافة محتويات هذا الملف إلى الملف README مباشرةً بعد الرأس وقبل جدول المحتويات مباشرةً. تتم معالجة هذا الملف بواسطة Pandoc لتضمين الصور قبل الكتابة إلى ملف README.
الملف الأكثر أهمية للتوثيق هو ملف جدول المحتويات الموجود في docs/_TOC.md . يحدد هذا الملف قائمة بالملفات التي يجب أن تكون متسلسلة لإنشاء دليل README النهائي. يجب أن تكون الملفات في هذه القائمة ليتم تضمينها.
احفظ كل المحتوى الثابت، بما في ذلك الصور، في المجلد _static . وهذا سوف يساعد في التنظيم.
قد يكون من المفيد الحصول على مستندات يتم تحديثها وكتابتها بنفسها. لإنشاء مستند ديناميكي، ما عليك سوى إنشاء ملف قابل للتنفيذ يكتب مستند Markdown المنسق إلى stdout. أثناء وقت الإنشاء، إذا كان الإدخال في ملف جدول المحتويات قابلاً للتنفيذ، فسيتم تنفيذه وسيتم استخدام stdout الخاص به في مكانه.
عندما يتم دفع التزام متعلق بالوثائق، فإن إجراء GitHub سيعرض الوثائق. سيتم تنفيذ أية تغييرات على ملف README تلقائيًا.
تتم معظم عمليات تكوين بيئة التطوير باستخدام متغيرات البيئة. لإجراء تغييرات دائمة على متغيرات البيئة، قم بتعديل variables.env أو استخدم واجهة مستخدم Workbench.
يستخدم هذا المشروع بيئة Python واحدة في /usr/bin/python3 وتتم إدارة التبعيات باستخدام pip . نظرًا لأن كل التطوير يتم داخل حاوية، فإن أي تغييرات في بيئة Python ستكون سريعة الزوال. لتثبيت حزمة Python بشكل دائم، قم بإضافتها إلى ملف requirements.txt أو استخدم واجهة مستخدم Workbench.
تعتمد بيئة التطوير على Ubuntu 22.04. يتمتع المستخدم الأساسي بإمكانية الوصول إلى sudo بدون كلمة مرور، ولكن جميع التغييرات في النظام ستكون سريعة الزوال. لإجراء تغييرات دائمة على الحزم المثبتة، قم بإضافتها إلى ملف [ apt.txt ]. لإجراء تغييرات أخرى على نظام التشغيل مثل معالجة الملفات وإضافة متغيرات البيئة وما إلى ذلك؛ استخدم ملفات postBuild.bash و preBuild.bash .
من الممارسات الجيدة عادةً تحديث التبعيات شهريًا لضمان عدم كشف أي مخاطر خطيرة خطيرة من خلال التبعيات التي يساء استخدامها. يمكن استخدام العملية التالية لتصحيح هذا المشروع. يوصى بإجراء اختبار الانحدار بعد التصحيح للتأكد من عدم حدوث أي خلل في التحديث.
/project/code/tools/bump.sh ./project/code/tools/audit.sh . سيقوم هذا البرنامج النصي بطباعة تقرير بجميع حزم Python في حالة تحذير وجميع الحزم في حالة خطأ. يجب حل أي شيء في حالة خطأ لأنه سيكون به مخاطر خطيرة خطيرة ونقاط ضعف معروفة.

