Facebook Messenger Bot
1.0.0
برنامج الدردشة الآلي FB Messenger الذي قمت بتدريبه على التحدث مثلي. منشور المدونة المرتبط.
بالنسبة لهذا المشروع، أردت تدريب نموذج "من تسلسل إلى تسلسل" على سجلات محادثاتي السابقة من مواقع التواصل الاجتماعي المختلفة. يمكنك قراءة المزيد حول الدافع وراء هذا النهج، وتفاصيل نموذج ML، والغرض من كل نص برمجي لـ Python في منشور المدونة، ولكنني أريد استخدام هذا الملف التمهيدي لشرح كيف يمكنك تدريب برنامج الدردشة الآلي الخاص بك على التحدث مثلك .
لتشغيل هذه البرامج النصية، ستحتاج إلى المكتبات التالية.
قم بتنزيل هذا المستودع بأكمله وفك ضغطه من GitHub، إما بشكل تفاعلي أو عن طريق إدخال ما يلي في المحطة الطرفية الخاصة بك.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitانتقل إلى الدليل العلوي للريبو على جهازك
cd Facebook-Messenger-Botمهمتنا الأولى هي تنزيل جميع بيانات المحادثة الخاصة بك من مواقع التواصل الاجتماعي المختلفة. بالنسبة لي، استخدمت Facebook وGoogle Hangouts وLinkedIn. إذا كان لديك مواقع أخرى تحصل منها على البيانات، فلا بأس بذلك. سيكون عليك فقط إنشاء طريقة جديدة في createDataset.py.
بيانات فيسبوك : قم بتنزيل بياناتك من هنا. بمجرد التنزيل، يجب أن يكون لديك ملف كبير إلى حد ما يسمى messages.htm . سيكون ملفًا كبيرًا جدًا (أكثر من 190 ميجابايت بالنسبة لي). سنحتاج إلى تحليل هذا الملف الكبير واستخراج جميع المحادثات. للقيام بذلك، سنستخدم هذه الأداة التي تفضل ديلون ديكسون بفتحها. ستمضي قدمًا وتقوم بتثبيت هذه الأداة عن طريق التشغيل
pip install fbchat-archive-parserثم تشغيل:
fbcap ./messages.htm > fbMessages.txtسيوفر لك هذا جميع محادثاتك على Facebook في ملف نصي موحد إلى حد ما. شكرا ديلون! تابع ثم قم بتخزين هذا الملف في مجلد Facebook-Messenger-Bot الخاص بك.
بيانات LinkedIn : قم بتنزيل بياناتك من هنا. بمجرد التنزيل، يجب أن تشاهد ملف inbox.csv . لن نحتاج إلى اتخاذ أي خطوات أخرى هنا، نريد فقط نسخها إلى مجلدنا.
بيانات Google Hangouts : قم بتنزيل نموذج البيانات الخاص بك هنا. بمجرد التنزيل، ستحصل على ملف JSON الذي سنحتاج إلى تحليله. للقيام بذلك، سنستخدم هذا المحلل اللغوي الذي تم العثور عليه من خلال منشور المدونة الرائع هذا. سنرغب في حفظ البيانات في ملفات نصية، ثم نسخ المجلد إلى مجلدنا.
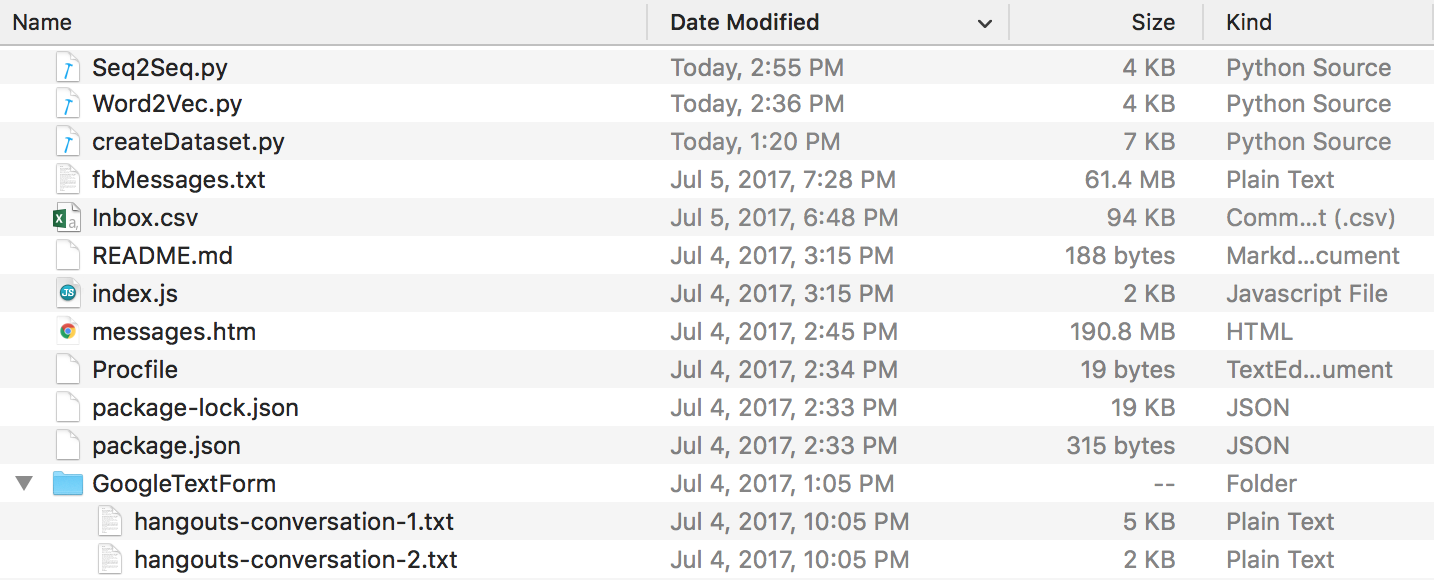
في نهاية كل هذا، يجب أن يكون لديك بنية دليل تبدو هكذا. تأكد من إعادة تسمية المجلدات وأسماء الملفات إذا كانت أسماءك مختلفة.
بيانات Discord : يمكنك استخراج سجلات الدردشة الخاصة بك باستخدام DiscordChatExporter الرائع الذي صممته Tyrrz. اتبع وثائقه لاستخراج سجلات الدردشة الفردية المطلوبة بتنسيق .txt (وهذا مهم). يمكنك بعد ذلك وضعها جميعًا في مجلد باسم DiscordChatLogs في دليل الريبو.
بيانات WhatsApp : تأكد من أن لديك هاتفًا خلويًا وضعه بتنسيق التاريخ الأمريكي إذا لم يكن موجودًا بالفعل (سيكون هذا مهمًا لاحقًا عند تحليل ملف السجل إلى .csv). لا يمكنك استخدام واتساب ويب لهذا الغرض. افتح الدردشة التي تريد إرسالها، اضغط على زر القائمة، اضغط على المزيد، ثم انقر على "الدردشة عبر البريد الإلكتروني". أرسل البريد الإلكتروني إلى نفسك وقم بتنزيله على جهاز الكمبيوتر الخاص بك. سيعطيك هذا ملف .txt، لتحليله، سنقوم بتحويله إلى .csv. للقيام بذلك، انتقل إلى هذا الرابط وأدخل كل النص في ملف السجل الخاص بك. انقر فوق تصدير، وقم بتنزيل ملف CSV وقم ببساطة بتخزينه في مجلد Facebook-Messenger-Bot الخاص بك تحت اسم "whatsapp_chats.csv".
ملاحظة : يبدو أن المحلل اللغوي الموجود في الرابط أعلاه قد تمت إزالته. إذا كان لا يزال لديك ملف .csv بالتنسيق الصحيح ، فلا يزال بإمكانك استخدامه. بخلاف ذلك، قم بتنزيل سجلات دردشة whatsapp الخاصة بك كملفات .txt ووضعها جميعًا في مجلد باسم WhatsAppChatLogs في دليل الريبو. سيعمل createDataset.py مع هذه الملفات بدلاً من ذلك فقط إذا لم يعثر على ملف .csv باسم whatsapp_chats.csv .
في حالة استخدام سجلات الدردشة بتنسيق .txt ، لاحظ أن التنسيق المتوقع هو-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(أو)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
الآن بعد أن أصبح لدينا جميع سجلات المحادثات بتنسيق نظيف، يمكننا المضي قدمًا وإنشاء مجموعة البيانات الخاصة بنا. في الدليل الخاص بنا، لنبدأ:
python createDataset.pyسيُطلب منك بعد ذلك إدخال اسمك (حتى يعرف البرنامج النصي الشخص الذي تبحث عنه)، ومواقع التواصل الاجتماعي التي لديك بيانات عنها. سيقوم هذا البرنامج النصي بإنشاء ملف باسم communicationDictionary.npy وهو كائن Numpy يحتوي على أزواج على شكل (FRIENDS_MESSAGE، ردك). سيتم أيضًا إنشاء ملف باسم communicationData.txt . هذا مجرد ملف نصي كبير يحتوي على بيانات القاموس في شكل موحد.
الآن بعد أن أصبح لدينا هذين الملفين، يمكننا البدء في إنشاء متجهات الكلمات من خلال نموذج Word2Vec. هذه الخطوة تختلف قليلا عن غيرها. تعمل وظيفة Tensorflow التي نراها لاحقًا (في seq2seq.py) أيضًا على معالجة جزء التضمين. لذلك يمكنك إما أن تقرر تدريب المتجهات الخاصة بك أو أن تقوم الدالة seq2seq بذلك بشكل مشترك، وهو ما انتهى بي الأمر إلى القيام به. إذا كنت تريد إنشاء متجهات الكلمات الخاصة بك من خلال Word2Vec، فقل y في الموجه (بعد تشغيل ما يلي). إذا لم تقم بذلك، فلا بأس، قم بالرد بـ n وستقوم هذه الوظيفة فقط بإنشاء ملف wordList.txt.
python Word2Vec.pyإذا قمت بتشغيل word2vec.py بالكامل، فسيؤدي ذلك إلى إنشاء 4 ملفات مختلفة. Word2VecXTrain.npy و Word2VecYTrain.npy هما مصفوفات التدريب التي سيستخدمها Word2Vec. نقوم بحفظها في المجلد الخاص بنا، في حالة احتياجنا إلى تدريب نموذج Word2Vec الخاص بنا مرة أخرى باستخدام معلمات تشعبية مختلفة. نقوم أيضًا بحفظ wordList.txt ، الذي يحتوي ببساطة على جميع الكلمات الفريدة في مجموعتنا. آخر ملف تم حفظه هو embeddingMatrix.npy وهو عبارة عن مصفوفة Numpy تحتوي على كافة متجهات الكلمات التي تم إنشاؤها.
الآن، يمكننا استخدام إنشاء وتدريب نموذج Seq2Seq الخاص بنا.
python Seq2Seq.pyسيؤدي هذا إلى إنشاء 3 ملفات مختلفة أو أكثر. Seq2SeqXTrain.npy و Seq2SeqYTrain.npy هما مصفوفات التدريب التي سيستخدمها Seq2Seq. مرة أخرى، نحفظ هذه العناصر فقط في حالة أردنا إجراء تغييرات على بنية النموذج الخاص بنا، ولا نريد إعادة حساب مجموعة التدريب الخاصة بنا. سيكون الملف (الملفات) الأخير عبارة عن ملفات .ckpt التي تحتوي على نموذج Seq2Seq المحفوظ لدينا. سيتم حفظ النماذج في فترات زمنية مختلفة في حلقة التدريب. سيتم استخدامها ونشرها بمجرد إنشاء برنامج الدردشة الآلي الخاص بنا.
الآن بعد أن أصبح لدينا نموذج محفوظ، فلنقم الآن بإنشاء برنامج الدردشة الآلي الخاص بنا على Facebook. للقيام بذلك، أوصي باتباع هذا البرنامج التعليمي. لا تحتاج إلى قراءة أي شيء أسفل قسم "تخصيص ما يقوله الروبوت". سيتعامل نموذج Seq2Seq الخاص بنا مع هذا الجزء. هام - سيخبرك البرنامج التعليمي بإنشاء مجلد جديد حيث سيكون مشروع Node. ضع في اعتبارك أن هذا المجلد سيكون مختلفًا عن المجلد الخاص بنا. يمكنك اعتبار هذا المجلد هو المكان الذي تكمن فيه المعالجة المسبقة للبيانات والتدريب على النماذج، في حين أن المجلد الآخر محجوز بشكل صارم لتطبيق Express (تحرير: أعتقد أنه يمكنك اتباع خطوات البرنامج التعليمي داخل مجلدنا وإنشاء مشروع Node فقط، ملفات Procfile وindex.js هنا إذا كنت تريد). يجب أن يكون البرنامج التعليمي نفسه كافيًا، ولكن إليك ملخصًا للخطوات.
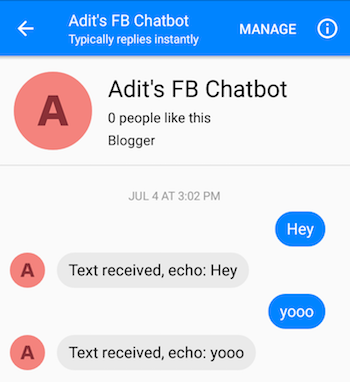
بعد اتباع الخطوات بشكل صحيح، من المفترض أن تكون قادرًا على إرسال رسائل إلى برنامج الدردشة الآلي والحصول على الردود.
آه، لقد انتهيت تقريبًا! الآن، يتعين علينا إنشاء خادم Flask حيث يمكننا نشر نموذج Seq2Seq المحفوظ لدينا. لدي رمز لهذا الخادم هنا. دعونا نتحدث عن الهيكل العام. عادةً ما تحتوي خوادم Flask على ملف .py رئيسي واحد حيث يمكنك تحديد كافة نقاط النهاية. سيكون هذا هو app.py في حالتنا. سيكون هذا هو المكان الذي نقوم بتحميله في نموذجنا. يجب عليك إنشاء مجلد يسمى "النماذج"، وتعبئته بأربعة ملفات (ملف نقطة تفتيش، وملف بيانات، وملف فهرس، وملف تعريف). هذه هي الملفات التي يتم إنشاؤها عند حفظ نموذج Tensorflow.

في ملف app.py هذا، نريد إنشاء مسار (/تنبؤ في حالتي) حيث سيتم إدخال مدخلات المسار في النموذج المحفوظ لدينا، ويكون إخراج وحدة فك التشفير هو السلسلة التي يتم إرجاعها. تفضل بالمضي قدمًا وإلقاء نظرة فاحصة على app.py إذا كان الأمر لا يزال مربكًا بعض الشيء. الآن بعد أن أصبح لديك app.py والنماذج الخاصة بك (والملفات المساعدة الأخرى إذا كنت في حاجة إليها)، يمكنك نشر خادمك. سوف نستخدم Heroku مرة أخرى. هناك الكثير من البرامج التعليمية المختلفة حول نشر خوادم Flask إلى Heroku، لكني أحب هذا البرنامج على وجه الخصوص (لست بحاجة إلى قسمي Foreman وLogging).
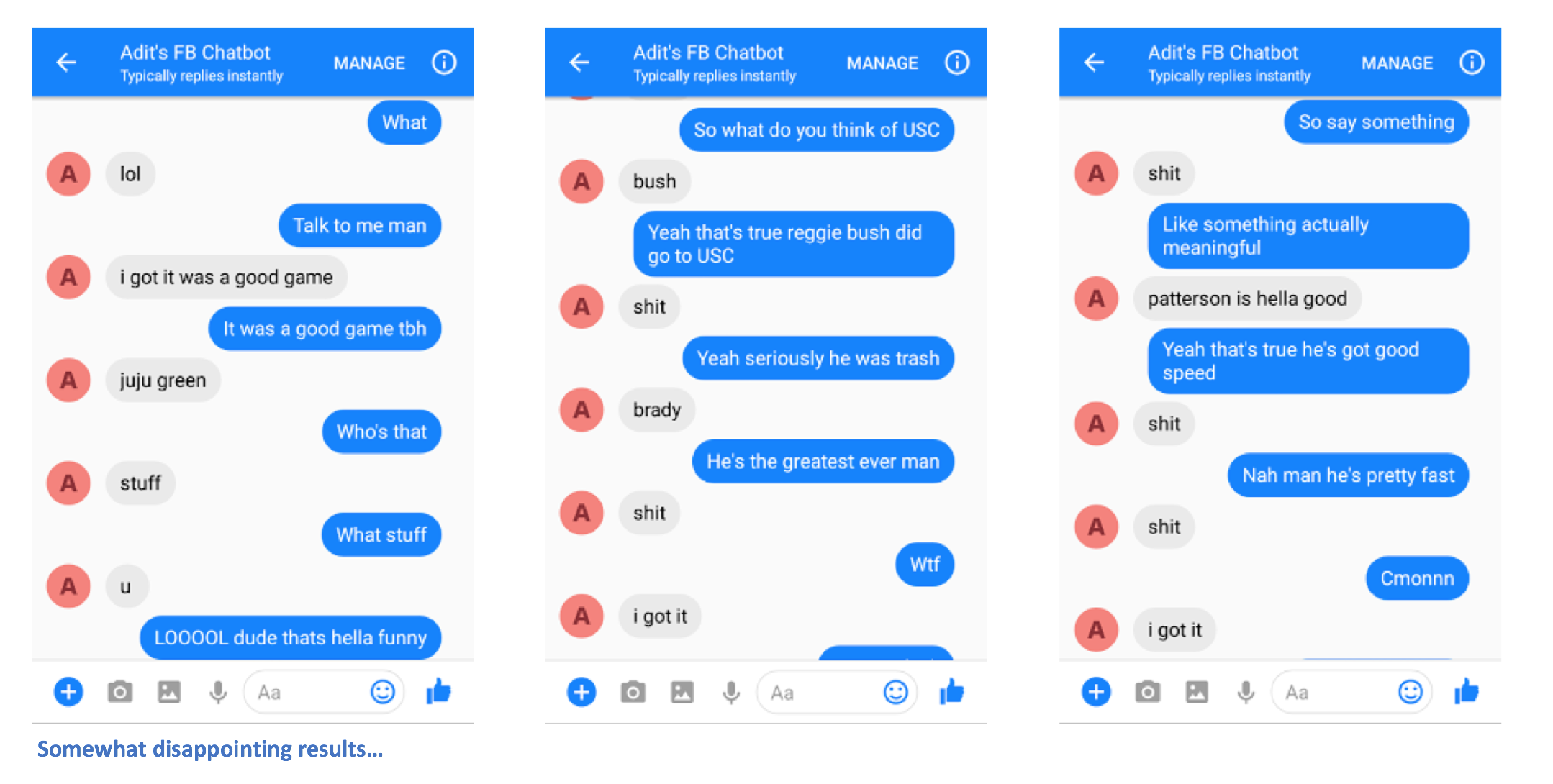
ها أنت ذا. يجب أن تكون قادرًا على إرسال رسائل إلى برنامج الدردشة الآلي، ورؤية بعض الردود المثيرة للاهتمام التي (نأمل) أن تشبهك بطريقة ما.
يرجى إعلامي إذا كانت لديك أية مشكلات أو إذا كان لديك أي اقتراحات لتحسين هذا الملف التمهيدي. إذا كنت تعتقد أن خطوة معينة غير واضحة، فأخبرني بذلك وسأبذل قصارى جهدي لتحرير الملف التمهيدي وتقديم أي توضيحات.