Stock_Price_Analysis
1.0.0
تم إنشاء هذا المشروع لتوضيح استخدام وحدات الماكرو التي تم تطويرها باستخدام VBA لبرنامج Excel والتي يمكن استخدامها لأتمتة جمع البيانات وتصورها من مجموعة مختارة من مخزونات الطاقة الخضراء. تم استخدام هذا لإظهار إمكانية استخدام وحدات الماكرو وكيف يمكن تشغيلها تلقائيًا باستخدام واجهات رسومية مثل الأزرار للسماح بالاستخدام المتكرر للمهمة. تم استخدام بيانات المخزون الخاصة بهذا المشروع لـ 12 سهمًا تم جمعها في عامي 2017 و2018. وتضمنت البيانات المستخدمة رمز المؤشر وقيم فتح وإغلاق الأسهم وحجم التداول اليومي لكل يوم. ومن هذا يمكننا تحديد سعر السهم الأول والأخير وحجم التداول الإجمالي لكل سهم يتم تحليله.
كان الهدف الآخر لهذا المشروع هو النظر في كيفية تحسين كفاءة التعليمات البرمجية باستخدام إعادة البناء لتحسين قوة الحوسبة اللازمة لإكمال وحدات الماكرو. ولهذا استخدمنا نسختنا الأولية من الكود والتي كانت وظيفية ولكنها تطلبت من البرنامج إكمال تكرار مجموعة البيانات بأكملها لكل شريط أسهم كنا نتطلع إلى تحليله. كان الهدف هو تطوير نسخة مُعاد تشكيلها من الكود الأصلي الذي يتطلب من البرنامج أن يكتمل فقط عند تكرار مجموعة البيانات والحصول على نفس البيانات مثل الإصدار الأول.
للبدء، قمنا بتطوير كود وظيفي يسمح بجمع إجمالي حجم المخزون السنوي والأداء السنوي لكل سهم كنا نتطلع إلى تحليله. كما هو موضح في الكود الذي قدمناه أدناه، تم جمع البيانات لكل سهم من خلال استكمال تكرار مجموعة البيانات وإدراج البيانات في ورقة عمل Excel قبل الانتقال إلى السهم التالي.

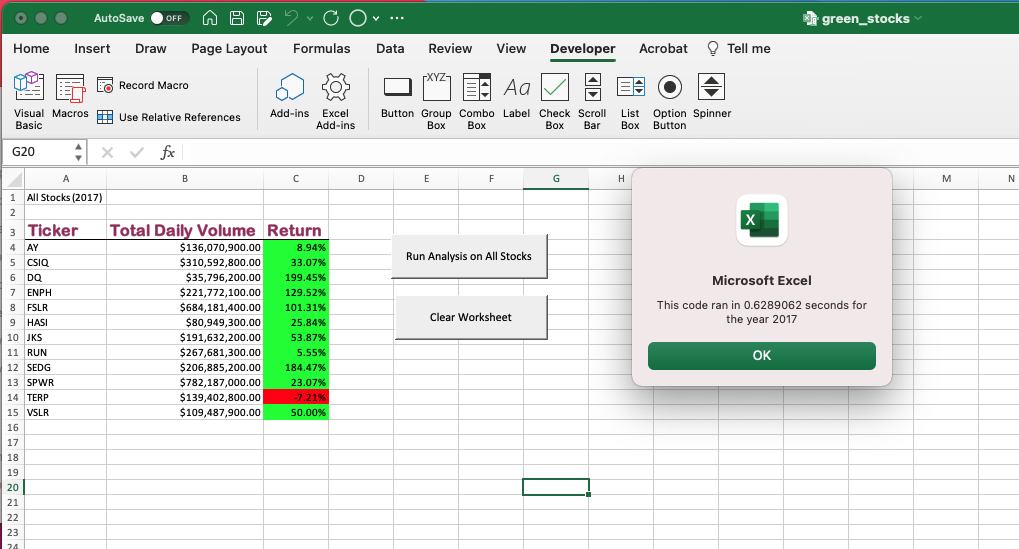
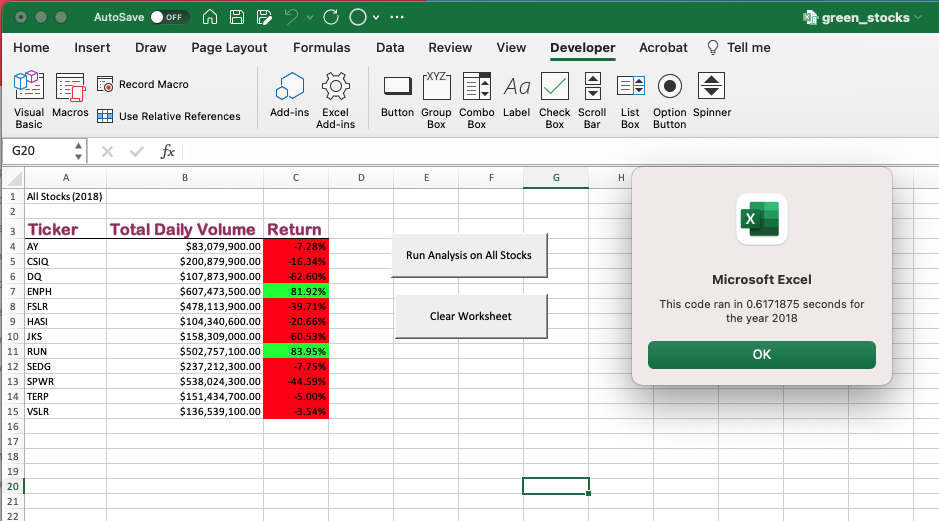
تم تضمين مؤقت في الكود يعرض الوقت الذي يستغرقه تشغيل البرنامج وإظهار النتائج. باستخدام هذا يمكننا مقارنة الوقت اللازم لإكمال الكود الأولي لجمع البيانات لمجموعات البيانات لكل عام. لقد وفر لنا هذا وقت تنفيذ الكود لكل عام كما هو موضح في الصور أدناه. يوضح أن الكود الأولي استغرق 0.6289062 ثانية لإكمال مجموعة بيانات 2017 و0.6171875 لإكمال مجموعة بيانات 2018.
من خلال إعادة هيكلة كود العمل الأصلي، يمكن تحقيق استخدام أكثر كفاءة للحوسبة عن طريق تقليل عدد التكرارات الإجمالية لمجموعة البيانات مما يؤدي إلى زيادة في سرعة تنفيذ المهمة. لإعادة بناء هذا الكود، كان هناك حاجة إلى إضافة مكونين إلى الماكرو الذي يتم تطويره. الأول كان عبارة عن فهرس لكل شريط سيتم تكراره لكل سطر من البيانات في مجموعات البيانات التي يتم تحليلها. هذا الأمر بالنسبة لكل سطر من البيانات داخل مجموعة البيانات، سيحدد البرنامج المؤشر الموجود ويخزن البيانات ذات الصلة المتعلقة بقيمة الفهرس. والثاني عبارة عن مجموعة من صفائف البيانات لتخزين نقاط البيانات المتعددة لكل شريط أسهم. نظرًا لأنه يمكن استرداد كل قيمة محفوظة في المصفوفة بناءً على ترتيب جمعها، فقد كان من الممكن ربط هذه البيانات مرة أخرى بمؤشر المؤشر المستخدم. سمح استخدام هاتين الأداتين بإعادة هيكلة الكود كما هو موضح في العينة أدناه.

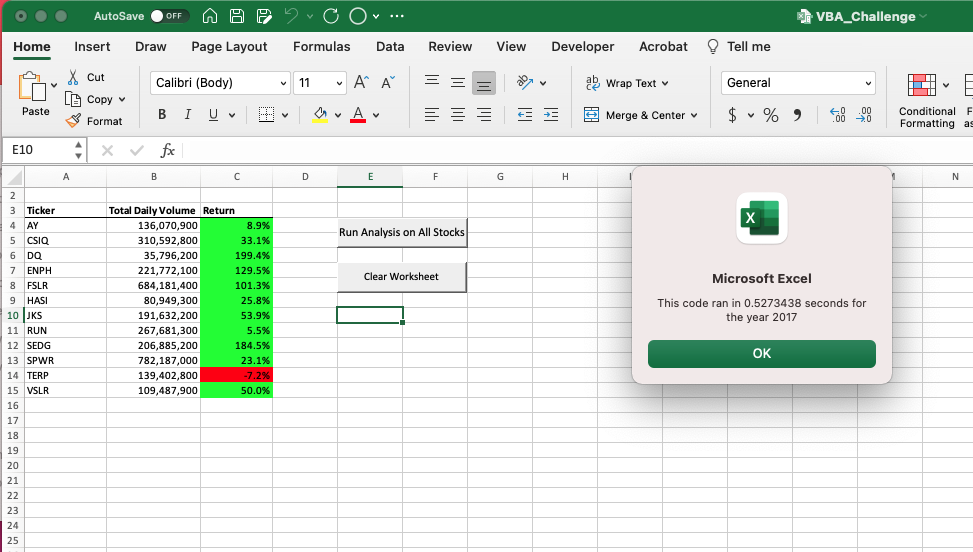
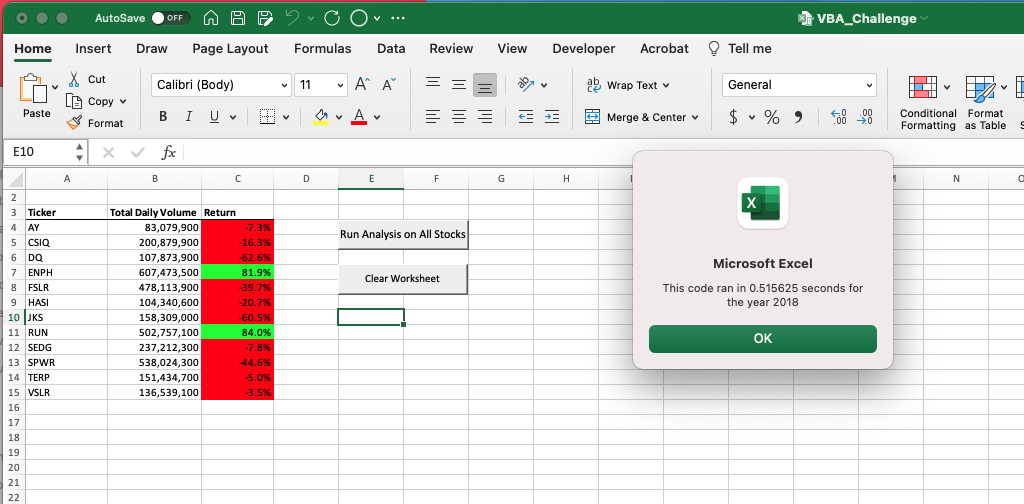
وباستخدام نفس الكود المستخدم لتحديد وقت تنفيذ الكود الأولي، كان من الممكن معرفة ما إذا كان هناك أي تحسن في وقت التنفيذ الذي تمت ملاحظته في الكود المُعاد هيكلته للتحليل. كما هو موضح في الصور أدناه، تم التنافس على الوقت الذي استغرقه استكمال تحليل البيانات من عامي 2017 و2018 باستخدام الكود الجديد وتم استخدام هذا للمقارنة مع الكود الأولي المستخدم. من هذا يمكننا أن نرى أن الأمر استغرق 0.5273438 ثانية لإكمال مجموعة بيانات 2017 و0.516825 ثانية لإكمال مجموعة بيانات 2018.
من المعلومات التي تم جمعها بناءً على الوقت اللازم لاستكمال تنفيذ التعليمات البرمجية الأولية والمعاد هيكلتها، كان هناك انخفاض قدره 0.1015624 ثانية لمجموعة بيانات 2017 و0.1103625 ثانية لمجموعة بيانات 2018.
عملية إعادة هيكلة التعليمات البرمجية لها بعض المزايا والعيوب لاستخدامها. أولا دعونا نلقي نظرة على بعض المزايا
بعض عيوب استخدام إعادة هيكلة التعليمات البرمجية.
في المثال الذي عرضناه هنا، كانت هناك بعض الإيجابيات والسلبيات لعملية إعادة البناء التي تم إكمالها لتحسين كفاءة الكود.
بعض الأفكار الإيجابية التي كانت نتيجة لتغيير الكود هي كما يلي:
تقليل الوقت المستخدم لإكمال التحليل عن طريق تقليل عدد التكرارات المكتملة لجمع البيانات.
أدى ذلك إلى رمز أكثر قوة يمكن توسيعه بسهولة ليشمل مجموعات بيانات أكبر ومعايير بحث أكثر
المصفوفات المستخدمة لتخزين البيانات التي يمكن استخدامها لإجراء حسابات أو تحليلات أخرى إذا كانت هناك حاجة إلى تحليل أكثر تعمقًا للبيانات
تتضمن بعض العوامل السلبية لاستخدام إعادة البناء في هذا الكود ما يلي
https://www.c-sharpcorner.com/article/pros-and-cons-of-code-refactoring/" ↩ ↩ 2


