
[توصيات ذات صلة: دروس فيديو JavaScript، الواجهة الأمامية للويب]
بغض النظر عن لغة البرمجة التي تستخدمها، تعد السلاسل نوعًا مهمًا من البيانات. تابعني لمعرفة المزيد حول سلاسل JavaScript !
السلسلة هي سلسلة مكونة من أحرف، إذا كنت قد درست C و Java ، فيجب أن تعلم أن الأحرف نفسها يمكن أن تصبح نوعًا مستقلاً. ومع ذلك، JavaScript لا تحتوي على نوع حرف واحد، فقط سلاسل بطول 1 .
تستخدم سلاسل JavaScript ترميز UTF-16 ثابتًا، وبغض النظر عن الترميز الذي نستخدمه عند كتابة البرنامج، فلن يتأثر.
السلاسل: علامات الاقتباس المفردة، وعلامات الاقتباس المزدوجة، وعلامات الاقتباس الخلفية.
Let Single = 'abcdefg';// علامات الاقتباس المفردة Let double = "asdfghj";// علامات الاقتباس المزدوجة Let backti = `zxcvbnm`;// علامات
الاقتباس المفردة والمزدوجة لها نفس الحالة، ولا نفرق.
تتيح لنا العلامات الخلفيةلتنسيق السلسلة
تنسيق السلاسل بشكل أنيق باستخدام ${...} بدلاً من استخدام إضافة السلسلة.
Let str = `عمري ${Math.round(18.5)} سنة.`;console.log(str) ;

للسلسلة متعددة الأسطر
أيضًا للسلسلة بتمديد الأسطر، وهو أمر مفيد جدًا عندما نكتب سلاسل متعددة الأسطر.
Let ques = `هل المؤلف وسيم؟ أ. وسيم جدًا؛ ب. وسيم جدًا؛ C. وسيم جدًا;`;console.log(ques)
;
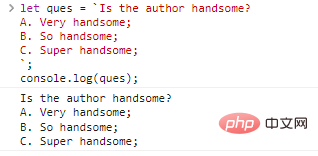
ألا يبدو أنه لا يوجد شيء خاطئ في ذلك؟ ولكن لا يمكن تحقيق ذلك باستخدام علامات الاقتباس المفردة والمزدوجة. إذا كنت تريد الحصول على نفس النتيجة، فيمكنك الكتابة على النحو التالي:
Let ques = 'هل المؤلف وسيم؟nA. وسيم جدًا؛nB وسيم جدًا؛nC. Super beautiful;'; console.log(ques);
يحتوي الكود أعلاه على حرف خاص n ، وهو الحرف الخاص الأكثر شيوعًا في عملية البرمجة لدينا.
n المعروف أيضًا باسم "حرف السطر الجديد"، يدعم علامات الاقتباس المفردة والمزدوجة لإخراج سلاسل متعددة الأسطر. عندما يقوم المحرك بإخراج سلسلة، إذا واجه n ، فسوف يستمر في الإخراج على سطر آخر، وبالتالي تحقيق سلسلة متعددة الأسطر.
على الرغم من أن n يبدو وكأنه حرفين، إلا أنه يشغل موضع حرف واحد فقط، وذلك لأن هو حرف هروب في السلسلة، وتصبح الأحرف التي تم تعديلها بواسطة حرف الهروب أحرفًا خاصة.
قائمة الأحرف الخاصة
| وصف | الأحرف الخاصة |
|---|---|
n | حرف السطر الجديد، يُستخدم لبدء سطر جديد من نص الإخراج. |
r | بنقل المؤشر إلى بداية السطر في أنظمة Windows ، يُستخدم rn لتمثيل فاصل الأسطر، مما يعني أن المؤشر يحتاج إلى الانتقال إلى بداية السطر أولاً، ثم بعد ذلك. إلى السطر التالي قبل أن يتمكن من التغيير إلى سطر جديد. يمكن للأنظمة الأخرى استخدام n مباشرة. |
' " | علامات الاقتباس المفردة والمزدوجة، ويرجع ذلك أساسًا إلى أن علامات الاقتباس المفردة والمزدوجة هي أحرف خاصة. إذا أردنا استخدام علامات الاقتباس المفردة والمزدوجة في سلسلة، فيجب علينا الهروب منها. |
\ | الشرطة المائلة العكسية، أيضًا لأن |
b f v | مسافة للخلف، وتغذية الصفحة، والتسمية العمودية - لم يعد |
xXX | حرف Unicode سداسي عشري مشفر كـ XX ، على سبيل المثال : x7A يعني z (ترميز Unicode السداسي العشري لـ z هو 7A ). |
uXXXX | يتم ترميزه كحرف Unicode السداسي العشري لـ XXXX ، على سبيل المثال: u00A9 يعني © |
( 1-6 أحرف سداسية عشرية u{X...X} | UTF-32 الترميز هو رمز Unicode لـ X...X . |
على سبيل المثال:
console.log('I'ma Student.');// 'console.log(""I love U. "");/ / "console.log("\n هو حرف سطر جديد.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// الكود نتائج التنفيذ:
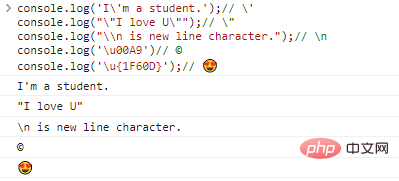
مع وجود حرف الهروب ، يمكننا من الناحية النظرية إخراج أي حرف، طالما وجدنا الترميز المقابل له.
تجنب استخدام ' و "
لعلامات الاقتباس المفردة والمزدوجة في السلاسل. يمكننا استخدام علامات الاقتباس المزدوجة بذكاء ضمن علامات الاقتباس المفردة، أو استخدام علامات الاقتباس المفردة ضمن علامات الاقتباس المزدوجة، أو استخدام علامات الاقتباس المفردة والمزدوجة مباشرةً ضمن علامات الاقتباس الخلفية. تجنب استخدام أحرف الهروب، على سبيل المثال:
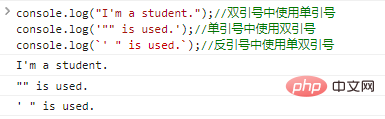
console.log("أنا طالب.");
// استخدم علامات الاقتباس المفردة ضمن علامات الاقتباس المزدوجة console.log('"" isused.');
// استخدم علامات الاقتباس المزدوجة داخل علامات الاقتباس المفردة console.log(`' " isused.`);
// نتائج تنفيذ التعليمات البرمجية باستخدام علامات الاقتباس المفردة والمزدوجة في العلامات الخلفية هي كما يلي:
من خلال خاصية .length للسلسلة، يمكننا الحصول على طول السلسلة:
console.log("HelloWorldn".length);//11 n هنا يحتل حرفًا واحدًا فقط.
في فصل "طرق الأنواع الأساسية"، اكتشفنا سبب احتواء الأنواع الأساسية في
JavaScriptعلى خصائص وطرق. هل مازلت تتذكر؟
السلسلة عبارة عن سلسلة من الأحرف يمكننا الوصول إلى حرف واحد من خلال [字符下标] يبدأ من 0 :
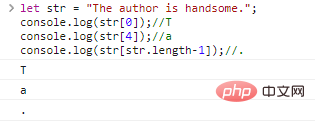
Let str = "المؤلف وسيم.";console.log(str[0]);//Tconsole.log(str[4])
;
//aconsole.log(str[str.length-1]);//.
يمكننا أيضًا استخدام الدالة charAt(post) للحصول على الأحرف:
Let str = "المؤلف وسيم.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.
تأثير التنفيذ للاثنين هو نفسه تمامًا، والفرق الوحيد هو عند الوصول إلى الأحرف خارج الحدود:
Let str = "01234"; console.log(str[ 9]);//undefconsole.log(str.charAt(9));//"" (سلسلة فارغة)
يمكننا أيضًا استخدام for ..of لاجتياز السلسلة:
for(let c of '01234'){
console.log(c);} لا يمكن تغيير السلسلة في JavaScript بمجرد تعريفها. على سبيل المثال:
Let str = "Const";str[0] = 'c' ;console.log(str)
; نتائج:
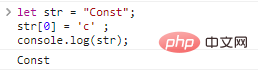
إذا كنت تريد الحصول على سلسلة مختلفة، يمكنك فقط إنشاء سلسلة جديدة:
Let str = "Const";str = str.replace('C','c');console.log(str) ; قمنا بتغيير سلسلة الأحرف، في الواقع لم يتم تغيير السلسلة الأصلية، ما حصلنا عليه هو السلسلة الجديدة التي تم إرجاعها بواسطة طريقة replace .
يحول حالة سلسلة، أو يحول حالة حرف واحد في سلسلة.
تعد طرق هاتين السلسلتين بسيطة نسبيًا، كما هو موضح في المثال:
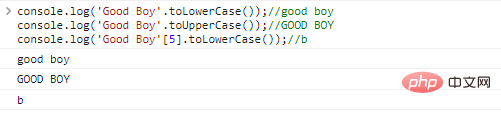
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());// نتائج تنفيذ التعليمات البرمجية ب:
تبدأ الدالة .indexOf(substr,idx) من موضع idx للسلسلة، وتبحث عن موضع substr الفرعية، وترجع منخفض الحرف الأول من السلسلة. سلسلة فرعية إذا نجحت، أو -1 إذا فشلت.
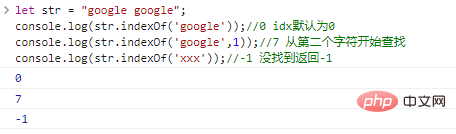
Let str = "google google";console.log(str.indexOf('google'));
//0 الافتراضي لـ idx هو 0console.log(str.indexOf('google',1));
//7 بحث console.log(str.indexOf('xxx')); بدءًا من الحرف الثاني.
// -1 لم يتم العثور على إرجاع -1 نتيجة تنفيذ التعليمات البرمجية:
إذا أردنا الاستعلام عن مواضع جميع السلاسل الفرعية في السلسلة، فيمكننا استخدام حلقة:
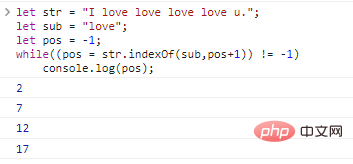
Let str = "I love love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); نتائج تنفيذ التعليمات البرمجية هي كما يلي:
يبحث .lastIndexOf(substr,idx) عن السلاسل الفرعية بشكل عكسي، ويبحث أولاً عن آخر سلسلة مطابقة:
Let str = "google google";console.log(str.lastIndexOf('google'));//7 إعدادات idx الافتراضية هي 0 لأن أساليب indexOf() و lastIndexOf() ستعيد -1 عندما يكون الاستعلام غير ناجح، و ~-1 === 0 . وهذا يعني أن استخدام ~ يكون صحيحًا فقط عندما لا تكون نتيجة الاستعلام -1 ، لذا يمكننا:
Let str = "google google";if(~indexOf('google',str)){
...} عادةً، لا نوصي باستخدام بناء جملة لا يمكن أن تنعكس فيه خصائص بناء الجملة بوضوح، لأن ذلك سيكون له تأثير على سهولة القراءة. ولحسن الحظ فإن الكود أعلاه يظهر فقط في النسخة القديمة من الكود وهو مذكور هنا حتى لا يرتبك الجميع عند قراءة الكود القديم.
الملحق:
~هو عامل نفي البت على سبيل المثال: الشكل الثنائي للرقم العشري2هو0010، والشكل الثنائي لـ~2هو1101(مكمل)، وهو-3.طريقة بسيطة للفهم،
~nتعادل-(n+1)، على سبيل المثال:~2 === -(2+1) === -3
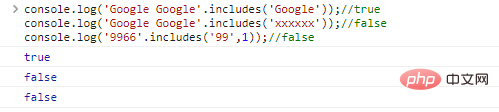
يتم استخدام .includes(substr,idx) لتحديد ما إذا كان substr موجودًا في السلسلة أم لا. idx هو موضع البداية للاستعلام
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));// نتائج تنفيذ التعليمات البرمجية الخاطئة:
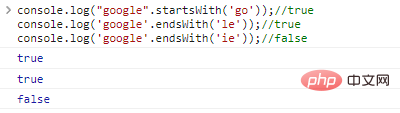
يحدد .startsWith('substr') و .endsWith('substr') على التوالي ما إذا كانت السلسلة تبدأ أو تنتهي بـ substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));// نتيجة تنفيذ التعليمات البرمجية الخاطئة:
.substr() , .substring() , .slice() كلها تستخدم للحصول على سلاسل فرعية من السلاسل، ولكن استخدامها مختلف.
.substr(start,len)
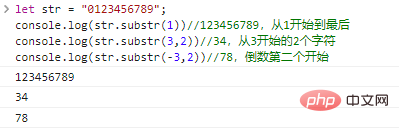
يُرجع سلسلة تتكون من أحرف len تبدأ من start . إذا تم حذف len ، فسيتم اعتراضها حتى نهاية السلسلة الأصلية. يمكن أن يكون start رقمًا سالبًا، يشير إلى حرف start من الخلف إلى الأمام.
Let str = "0123456789";console.log(str.substr(1))//123456789، بدءًا من 1 إلى النهاية console.log(str.substr(3,2))//34, 2 بدءًا من 3 أحرف console.log(str.substr(-3,2))//78،
نتيجة تنفيذ كود البدء قبل الأخير:
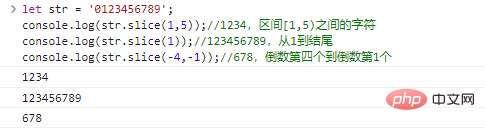
.slice(start,end)
يُرجع السلسلة التي تبدأ من start وتنتهي عند end (حصريًا). يمكن أن تكون start end أرقامًا سالبة، مما يشير إلى أحرف start/end قبل الأخيرة.
Let str = '0123456789';console.log(str.slice(1,5));//1234، الأحرف بين الفاصل الزمني [1,5) console.log(str.slice(1));//123456789 , من 1 إلى النهاية console.log(str.slice(-4,-1));//678،
نتائج تنفيذ التعليمات البرمجية من الرابع إلى الأخير:
.substring(start,end)
هي تقريبًا نفس وظيفة .slice() والفرق موجود في مكانين:
end > start غير مسموح به؛0 ،على سبيل المثال:
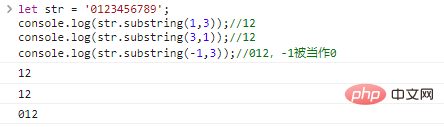
Let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 يتم التعامل معه على أنه
نتيجة تنفيذ التعليمات البرمجية 0:
قارن الاختلافات بين الثلاثة:
| معلمات | وصف | الطريقة |
|---|---|---|
| يمكن أن تكون الشريحة | .slice(start,end) | [start,end) | سالبة
.substring(start,end) | [start,end) | والقيمة السالبة 0 |
.substr(start,len) | يبدأ من start len | العديد |
من طرق السلسلة الفرعية السلبية لـ len، لذلك من الصعب بطبيعة الحال اختيارها. يوصى بتذكر
.slice()، وهو أكثر مرونة من الطريقتين الأخريين.
لقد ذكرنا بالفعل مقارنة السلاسل في المقالة السابقة. يتم ترتيب السلاسل حسب ترتيب القاموس. خلف كل حرف رمز، ويعتبر رمز ASCII مرجعًا مهمًا.
على سبيل المثال:
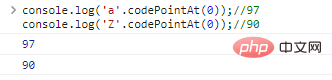
console.log('a'>'Z');// المقارنة بين الأحرف الحقيقية هي في الأساس مقارنة بين الترميزات التي تمثل الأحرف. تستخدم JavaScript UTF-16 لتشفير السلاسل، وكل حرف عبارة عن رمز مكون 16 بت. إذا كنت تريد معرفة طبيعة المقارنة، فأنت بحاجة إلى استخدام .codePointAt(idx) للحصول على ترميز الأحرف:
console.log('a). '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 نتائج تنفيذ التعليمات البرمجية:
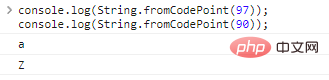
استخدم String.fromCodePoint(code) لتحويل الترميز إلى أحرف:
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
نتائج تنفيذ التعليمات البرمجية هي كما يلي:
يمكن تحقيق هذه العملية باستخدام حرف الهروب u ، كما يلي:
console.log('u005a');//Z, 005a هو التدوين السداسي العشري لـ 90 console.log('u0061');//a, 0061 إنه التدوين السداسي العشري للرقم 97. دعنا نستكشف الأحرف المشفرة في النطاق [65,220] :
Let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); نتائج جزء تنفيذ التعليمات البرمجية هي كما يلي:

الصورة أعلاه لا تظهر كافة النتائج، لذا اذهب وجربها.
ECMA-402 JavaScript .localeCompare() str1.localeCompare(str2)
str1 < str2 ، قم بإرجاع رقم سالبstr1 > str2 ، قم بإرجاع رقم موجب؛str1 == str2 ، قم بإرجاع 0؛على سبيل المثال:
console.log("abc".localeCompare('def'));//-1 لماذا لا تستخدم عوامل المقارنة مباشرة؟
وذلك لأن الأحرف الإنجليزية لها بعض الطرق الخاصة في الكتابة، على سبيل المثال، á هو متغير من a :
console.log('á' < 'z');// على الرغم من أن false هي أيضًا a ، إلا أنها أكبر من z ! !
في هذا الوقت، تحتاج إلى استخدام طريقة .localeCompare() :
console.log('á'.localeCompare('z'));//- 1 str.trim() يزيل أحرف المسافة البيضاء قبل وبعد سلسلة، str.trimStart() ، str.trimEnd() تحذف المسافات في البداية والنهاية؛
Let str = " 999 "
str.repeat(n) السلسلة n مرات؛
Let str = '6';console.log(str.repeat(3));//666
str.replace(substr,newstr) يستبدل السلسلة الفرعية الأولى، ويستخدم str.replaceAll() لاستبدال الكل substrings;
Let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6لا يزال هناك العديد من الطرق الأخرى ويمكننا زيارة الدليل لمزيد من المعرفة.
تستخدم JavaScript UTF-16 لتشفير السلاسل، أي يتم استخدام بايتين ( 16 بت) لتمثيل حرف واحد، ومع ذلك، يمكن للبيانات 16 بت أن تمثل 65536 حرفًا فقط لا يتم تضمين الأحرف الشائعة بطبيعة الحال، ومن السهل فهمها، ولكنها لا تكفي للأحرف النادرة (الصينية)، emoji ، والرموز الرياضية النادرة، وما إلى ذلك.
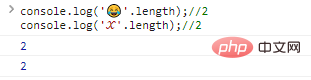
في هذه الحالة، تحتاج إلى توسيع واستخدام أرقام أطول ( 32 بت) لتمثيل الأحرف الخاصة، على سبيل المثال:
console.log(''.length);//2console.log('?'.length);//2 نتيجة تنفيذ الكود:
والنتيجة هي أننا لا نستطيع معالجتها باستخدام الطرق التقليدية. ماذا يحدث إذا قمنا بإخراج كل بايت على حدة؟
console.log(''[0]);console.log(''[1]); نتائج تنفيذ التعليمات البرمجية:
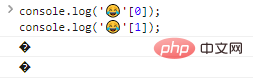
كما ترون، لا يتم التعرف على بايتات الإخراج الفردية.
ولحسن الحظ، يمكن للطرق String.fromCodePoint() و .codePointAt() التعامل مع هذا الموقف لأنه تمت إضافتها مؤخرًا. في الإصدارات الأقدم من JavaScript ، يمكنك فقط استخدام الأساليب String.fromCharCode() و .charCodeAt() لتحويل الترميزات والأحرف، ولكنها غير مناسبة للأحرف الخاصة.
يمكننا التعامل مع الأحرف الخاصة من خلال الحكم على نطاق ترميز الحرف لتحديد ما إذا كان حرفًا خاصًا أم لا. إذا كان رمز الحرف يقع بين 0xd800~0xdbff ، فهو الجزء الأول من الحرف 32 بت، ويجب أن يكون الجزء الثاني بين 0xdc00~0xdfff .
على سبيل المثال:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 نتيجة تنفيذ التعليمات البرمجية:

في اللغة الإنجليزية، هناك العديد من المتغيرات القائمة على الحروف، على سبيل المثال: الحرف a يمكن أن يكون الحرف الأساسي àáâäãåā . لا يتم تخزين كل هذه الرموز المتغيرة بتشفير UTF-16 نظرًا لوجود مجموعات كثيرة جدًا من الاختلافات.
من أجل دعم جميع مجموعات المتغيرات، يتم أيضًا استخدام أحرف Unicode متعددة لتمثيل حرف متغير واحد، أثناء عملية البرمجة، يمكننا استخدام الأحرف الأساسية بالإضافة إلى "الرموز الزخرفية" للتعبير عن الأحرف الخاصة:
console.log('au0307 '. );//t
console.log('au0308');//ş
console.log('au0309');//ş
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');// نتائج تنفيذ التعليمات البرمجية:
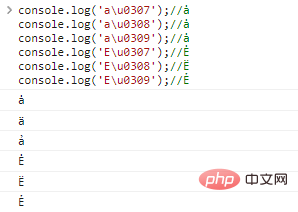
يمكن أن يحتوي الحرف الأساسي أيضًا على زخارف متعددة، على سبيل المثال:
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// نتائج تنفيذ
الكود:
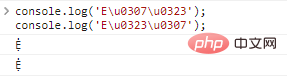
توجد مشكلة هنا في حالة تعدد الزخارف، يتم ترتيب الزخارف بشكل مختلف، ولكن الأحرف المعروضة فعليًا هي نفسها.
إذا قارنا هذين التمثيلين مباشرة، فسنحصل على نتيجة خاطئة:
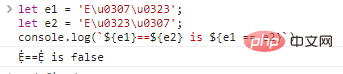
Let e1 = 'Eu0307u0323';
دع e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} هو ${e1 == e2}`) نتائج تنفيذ التعليمات البرمجية:
من أجل حل هذا الموقف، هناك خوارزمية تطبيع ** Unicode يمكنها تحويل السلسلة إلى تنسيق عالمي **، يتم تنفيذها بواسطة str.normalize() :
Let e1 = 'Eu0307u0323';
دع e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} هو ${e1.normalize() == e2.normalize()}`)
نتائج تنفيذ التعليمات البرمجية:

[توصيات ذات صلة: دروس فيديو جافا سكريبت، واجهة الويب الأمامية]
ما ورد أعلاه هو المحتوى التفصيلي للطرق الأساسية الشائعة لسلاسل جافا سكريبت لمزيد من المعلومات، يرجى الانتباه إلى المقالات الأخرى ذات الصلة على موقع PHP الصيني!