لقد قمنا بالزحف إلى جميع معلومات صفحة الويب في القسم السابق، وعلينا الآن العثور على المحتوى الذي نحتاجه في كود html، لذلك نحتاج إلى الدخول إلى موقع الويب وفقًا للمشكلة وتحليل المعلومات الموجودة في صفحة الويب.
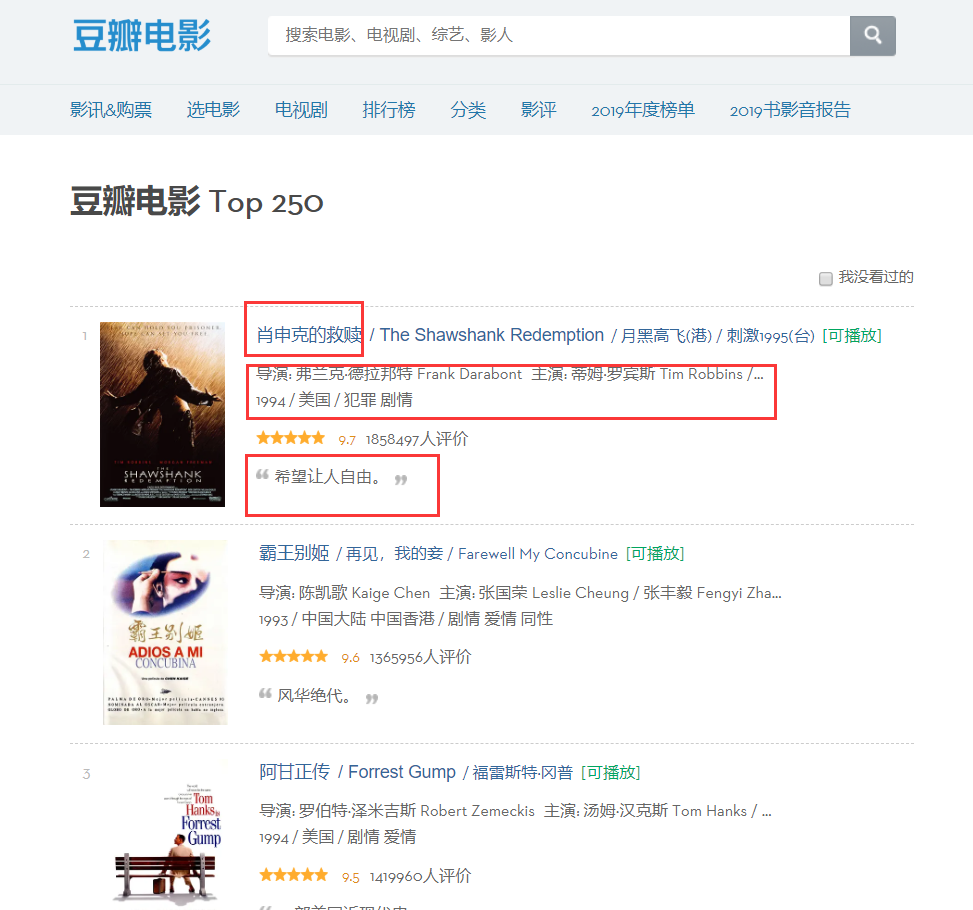
يمكن أن نجد من الصفحة أن المعلومات التي نحتاج إلى الزحف إليها موجودة في أقسام مختلفة، لذلك دعونا نتحقق من عناصر الصفحة، وانقر بزر الماوس الأيمن على الصفحة للتحقق من الكود المصدري لصفحة الويب أو F12.

قبل تحليل صفحة الويب، نحدد أولاً طريقة التخزين بعد التحليل، وهنا نستخدم قائمة لتخزين جميع المعلومات، ومن ثم يتوافق كل عنصر في القائمة مع قاموس، وكل قاموس يتوافق مع أنواع متعددة من المعلومات.
movie=[]#حدد أولاً قائمة لتخزين جميع المعلومات
من خلال التحليل، يمكننا تحديد أن موضع العنوان هو "الامتداد" الأول في أول "a" ضمن "div" المسمى "hd"، حتى نتمكن من قفل اسم كل فيلم من خلال الكود التالي، وبعد ذلك في القاموس.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename# عنصر في القاموسبنفس الطريقة، يمكن العثور على الكود المصدري لاسم المخرج بناءً على تحديد الموقع، لكن كود المصدر هذا يحتوي على الكثير من المعلومات، لذلك نحتاج إلى تصفيته من خلال التعبيرات العادية.
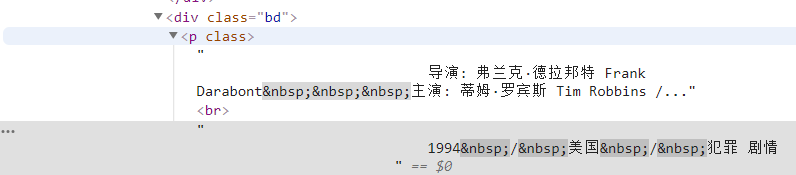
info=each.find('div',class_='bd').p.text.strip()أولاً، نقوم بالعثور على كل المحتوى ضمن هذه العلامة، ثم نقوم بتصفية المعلومات غير ذات الصلة من خلال التعبيرات العادية.
info=info.replace('n',)# يُرجع حرف التصفية info=info.replace(),)# تصفية المسافات info=info.replace(xa0,)# تصفية أحرف المسافات البيضاء غير المنفصلة Director=re.findall( r '[Director:].+[Starring:]',info)[0]director=director[3:len(director)-6]ثم قم بتعريفه كعنصر في القاموس.
movie['director']=director# عنصر في القاموس
يمكننا أن نجد أن نوع الفيلم موجود أيضًا في هذه العلامة "p"، ونحصل أيضًا على هذه المعلومات مباشرة من خلال التعبيرات العادية.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#أضف كعنصر في القاموسوأخيرا، قفل معلومات التصنيف.
star=each.find('div',class_='star')star=star.find('span',class_=' rating_num').text.strip()ثم تابع حفظه على شكل قاموس.
فيلم['نجم']=نجم
أخيرًا أضف هذا القاموس إلى القائمة وكرره على المخرجات.
movie.append(movie)# أضف القاموس إلى القائمة الخاصة بـ iinmovies:# اجتياز طباعة الإخراج (i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#محاكاة المتصفح للوصول إلى'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537. 36','Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 times r=requests.get(res ,headers=headers,timeout=10)#Set the timeout sauce=BeautifulSoup(r.text,html.parser)#قم بتعيين طريقة التحليل، ويمكن أيضًا استخدام طرق أخرى. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text .strip()movie['rank']=rankinfo=each.find('div',class_='bd').p.text.strip()info=info.replace('n',)info=info .replace(,)info=info.replace(xa0,)director=re.findall(r'[Director:].+[Starring:]',info)[0]director=director [3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0-9]{4}',info)[0]movie['release_date']=release_dateplot=re .findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index(' /')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each.find('div',class_='star')star=star. find('span',class_=' rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print(i)وحدة التحكم:

في هذا المثال، نتعلم بشكل أساسي كيفية العثور على المعلومات المقابلة في الكود المصدري لصفحة الويب. يمكن أن يساعدنا BeautifulSoup في تحديد موقعها بسرعة، ثم دمجها مع التعبيرات العادية لإكمال مطابقة المعلومات سيتم حفظ هذه البيانات في قاعدة البيانات.