يوفر أحدث نموذج لغة متعدد الوسائط BLIP-3-Video الذي أصدره فريق أبحاث Salesforce AI حلاً لمعالجة بيانات الفيديو المتزايدة بكفاءة. ويهدف هذا النموذج إلى تحسين كفاءة وتأثير فهم الفيديو، ويستخدم على نطاق واسع في مجالات مثل القيادة الذاتية والترفيه، مما يجلب الابتكار إلى جميع مناحي الحياة. سيشرح محرر Downcodes بالتفصيل التكنولوجيا الأساسية والأداء الممتاز لـ BLIP-3-Video.
أطلق فريق أبحاث Salesforce AI مؤخرًا نموذجًا جديدًا متعدد الوسائط للغة BLIP-3-Video. مع الزيادة السريعة في محتوى الفيديو، أصبحت كيفية معالجة بيانات الفيديو بكفاءة مشكلة ملحة يجب حلها. ويهدف ظهور هذا النموذج إلى تحسين كفاءة وفعالية فهم الفيديو وهو مناسب لمختلف الصناعات بدءًا من القيادة الذاتية وحتى الترفيه.
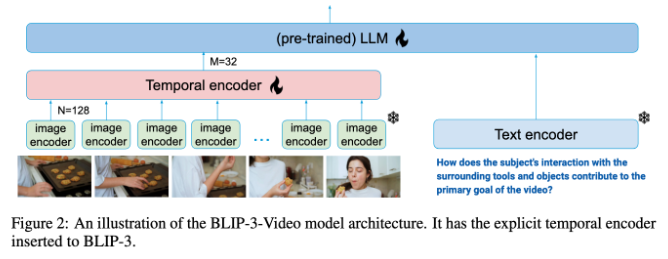
غالبًا ما تقوم نماذج فهم الفيديو التقليدية بمعالجة مقاطع الفيديو إطارًا تلو الآخر وتوليد كمية كبيرة من المعلومات المرئية. لا تستهلك هذه العملية الكثير من موارد الحوسبة فحسب، بل تحد أيضًا بشكل كبير من القدرة على معالجة مقاطع الفيديو الطويلة. مع استمرار نمو كمية بيانات الفيديو، يصبح هذا النهج غير فعال بشكل متزايد، لذلك من الضروري إيجاد حل يلتقط المعلومات الأساسية للفيديو مع تقليل العبء الحسابي.
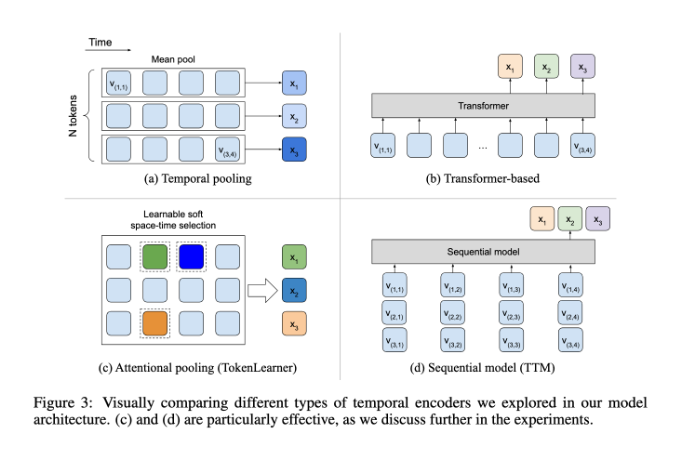
وفي هذا الصدد، يعمل BLIP-3-Video بشكل جيد جدًا. نجح هذا النموذج في تقليل كمية المعلومات المرئية المطلوبة في الفيديو إلى 16 إلى 32 علامة مرئية عن طريق إدخال "برنامج التشفير الزمني". يعمل هذا التصميم المبتكر على تحسين الكفاءة الحسابية بشكل كبير، مما يسمح للنموذج بإكمال مهام الفيديو المعقدة بتكلفة أقل. يستخدم هذا المشفر الزمني آلية تجميع الاهتمام الزماني المكاني القابلة للتعلم والتي تستخرج المعلومات الأكثر أهمية من كل إطار وتدمجها في مجموعة مدمجة من العلامات المرئية.
يعمل BLIP-3-Video أيضًا بشكل جيد جدًا. ومن خلال المقارنة مع النماذج الأخرى واسعة النطاق، وجدت الدراسة أن دقة هذا النموذج في مهام الإجابة على أسئلة الفيديو قابلة للمقارنة مع النماذج العليا. على سبيل المثال، يتطلب نموذج Tarsier-34B 4608 علامة لمعالجة 8 إطارات فيديو، بينما يحتاج BLIP-3-Video إلى 32 علامة فقط لتحقيق درجة معيارية MSVD-QA تبلغ 77.7%. يوضح هذا أن BLIP-3-Video يقلل بشكل كبير من استهلاك الموارد مع الحفاظ على الأداء العالي.
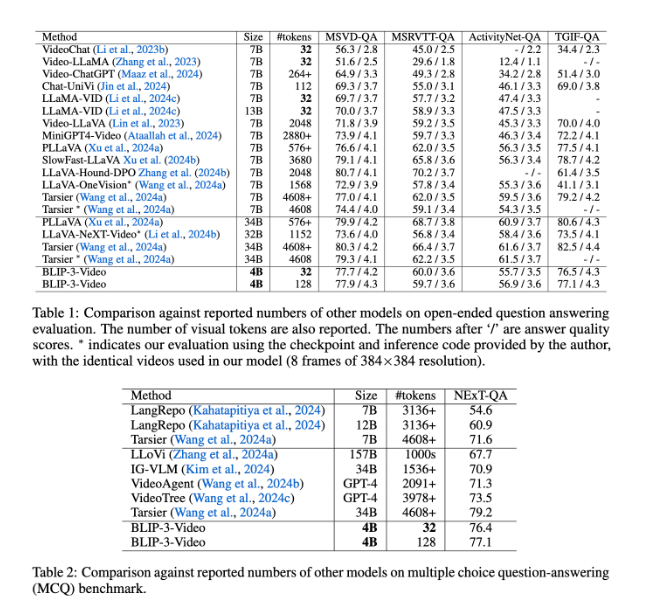
بالإضافة إلى ذلك، لا يمكن الاستهانة بأداء BLIP-3-Video في مهام الأسئلة والأجوبة متعددة الخيارات. وفي مجموعة بيانات NExT-QA، حقق النموذج درجة عالية بلغت 77.1%، وفي مجموعة بيانات TGIF-QA، حقق أيضًا دقة قدرها 77.1%. توضح هذه البيانات كفاءة BLIP-3-Video في معالجة مشكلات الفيديو المعقدة.

يفتح BLIP-3-Video إمكانيات جديدة في معالجة الفيديو باستخدام برنامج تشفير التوقيت المبتكر. إن إطلاق هذا النموذج لا يؤدي إلى تحسين كفاءة فهم الفيديو فحسب، بل يوفر أيضًا المزيد من الإمكانيات لتطبيقات الفيديو المستقبلية.
مدخل المشروع: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
يوفر BLIP-3-Video اتجاهًا جديدًا لتطوير تكنولوجيا الفيديو المستقبلية من خلال إمكانات معالجة الفيديو الفعالة. يوضح أدائها الممتاز في أسئلة وأجوبة الفيديو ومهام الأسئلة والأجوبة متعددة الخيارات إمكاناتها الهائلة في توفير الموارد وتحسين الأداء. ونحن نتطلع إلى أن يلعب BLIP-3-Video دورًا في المزيد من المجالات وتعزيز تقدم تكنولوجيا الفيديو.