حقق فريق البحث التابع لمعهد ابتكار الحوسبة بجامعة تشجيانغ تقدمًا كبيرًا في حل مشكلة عدم كفاية قدرة النماذج اللغوية الكبيرة على معالجة البيانات الجدولية وأطلق نموذجًا جديدًا TableGPT2. بفضل برنامج تشفير الجدول الفريد الخاص به، يستطيع TableGPT2 معالجة بيانات الجدول المختلفة بكفاءة، مما يؤدي إلى تغييرات ثورية في التطبيقات المعتمدة على البيانات مثل ذكاء الأعمال (BI). سيشرح محرر Downcodes بالتفصيل الابتكار واتجاه التطوير المستقبلي لـ TableGPT2.
أدى ظهور نماذج اللغات الكبيرة (LLMs) إلى إحداث تغييرات ثورية في تطبيقات الذكاء الاصطناعي، ومع ذلك، فهي تعاني من عيوب واضحة في معالجة البيانات الجدولية. ولمعالجة هذه المشكلة، أطلق فريق بحث من معهد ابتكار الحوسبة بجامعة تشجيانغ نموذجًا جديدًا يسمى TableGPT2، والذي يمكنه دمج البيانات الجدولية ومعالجتها بشكل مباشر وفعال، مما يفتح آفاقًا جديدة لذكاء الأعمال (BI) وغيرها من البيانات المستندة إلى البيانات. التطبيقات.
يكمن الابتكار الأساسي لـ TableGPT2 في برنامج تشفير الجدول الفريد الخاص به، والذي تم تصميمه خصيصًا لالتقاط المعلومات الهيكلية ومعلومات محتوى الخلية الخاصة بالجدول، وبالتالي تعزيز قدرة النموذج على التعامل مع الاستعلامات الغامضة وأسماء الأعمدة المفقودة والجداول غير المنتظمة الشائعة في الواقع. - تطبيقات العالم . يعتمد TableGPT2 على بنية Qwen2.5 وقد خضع لتدريب مسبق وضبط واسع النطاق، بما في ذلك أكثر من 593800 جدول و2.36 مليون صف عالي الجودة لمخرجات جدول الاستعلام، وهو نطاق غير مسبوق من الجداول ذات الصلة البيانات في البحوث السابقة.
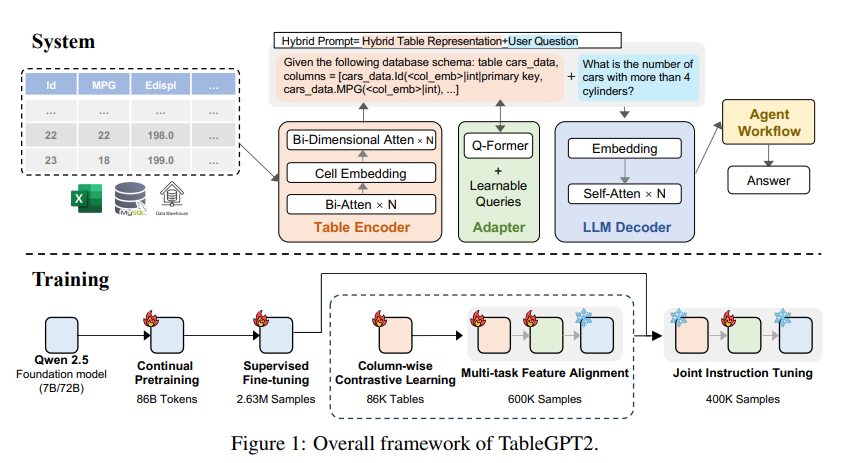
من أجل تحسين قدرات الترميز والاستدلال لـ TableGPT2، أجرى الباحثون تدريبًا مسبقًا مستمرًا (CPT)، حيث تم كتابة 80% من البيانات كرمز مشروح بعناية للتأكد من أنها تتمتع بقدرات ترميز قوية. بالإضافة إلى ذلك، قاموا أيضًا بجمع كمية كبيرة من بيانات الاستدلال والكتب المدرسية التي تحتوي على معرفة خاصة بالمجال لتعزيز قدرات الاستدلال للنموذج. تحتوي بيانات CPT النهائية على 86 مليار رمز مميز تمت تصفيته بدقة، مما يوفر إمكانات التشفير والاستدلال اللازمة لـ TableGPT2 للتعامل مع مهام ذكاء الأعمال المعقدة والمهام الأخرى ذات الصلة.
ولمعالجة القيود المفروضة على TableGPT2 في التكيف مع مهام وسيناريوهات ذكاء الأعمال المحددة، أجرى الباحثون ضبطًا دقيقًا تحت الإشراف (SFT) عليه. لقد قاموا ببناء مجموعة بيانات تغطي مجموعة متنوعة من السيناريوهات المهمة والواقعية، بما في ذلك جولات متعددة من المحادثات، والتفكير المعقد، واستخدام الأدوات، والاستعلامات الموجهة نحو الأعمال. تجمع مجموعة البيانات بين التعليقات التوضيحية اليدوية وعملية التعليقات التوضيحية الآلية التي يحركها الخبراء لضمان جودة البيانات وأهميتها. قامت عملية SFT، باستخدام إجمالي 2.36 مليون عينة، بتحسين النموذج بشكل أكبر لتلبية الاحتياجات المحددة لذكاء الأعمال والبيئات الأخرى التي تتضمن الجداول.
يقدم TableGPT2 أيضًا بشكل مبتكر برنامج تشفير الجدول الدلالي الذي يأخذ الجدول بأكمله كمدخل ويولد مجموعة مدمجة من ناقلات التضمين لكل عمود. تم تخصيص هذه البنية للخصائص الفريدة للبيانات الجدولية، مما يلتقط بشكل فعال العلاقات بين الصفوف والأعمدة من خلال آلية الاهتمام ثنائية الاتجاه وعملية استخراج الميزات الهرمية. بالإضافة إلى ذلك، تم اعتماد طريقة التعلم التقابلي العمودي لتشجيع النموذج على تعلم تمثيلات دلالية جدولية ذات معنى ومدركة للبنية.
من أجل دمج TableGPT2 بسلاسة مع أدوات تحليل البيانات على مستوى المؤسسة، صمم الباحثون أيضًا إطار عمل لسير عمل الوكيل. يتكون الإطار من ثلاثة مكونات أساسية: هندسة تلميحات وقت التشغيل، ووضع الحماية الآمن للكود، ووحدة تقييم الوكيل، والتي تعمل معًا على تعزيز قدرات الوكيل وموثوقيته. تدعم مهام سير العمل مهام تحليل البيانات المعقدة من خلال خطوات معيارية (تسوية الإدخال، وتنفيذ الوكيل، واستدعاء الأداة) التي تعمل معًا لإدارة أداء الوكيل ومراقبته. من خلال دمج الجيل المعزز للاسترجاع (RAG) من أجل استرجاع السياق بكفاءة ووضع الحماية للكود من أجل التنفيذ الآمن، يضمن إطار العمل أن TableGPT2 يقدم رؤى دقيقة وحساسة للسياق في مشاكل العالم الحقيقي.
أجرى الباحثون تقييمًا شاملاً لـ TableGPT2 على مجموعة متنوعة من المعايير الجدولية والأغراض العامة المستخدمة على نطاق واسع، وأظهرت النتائج أن TableGPT2 يتفوق في فهم الجدول ومعالجته واستدلاله، مع متوسط تحسن في الأداء بنسبة 35.20% لنموذج مكون من 7 مليارات معلمة، 720. ارتفع متوسط أداء نموذج 100 مليون معلمة بنسبة 49.32%، مع الحفاظ على الأداء العام القوي. للحصول على تقييم عادل، قاموا فقط بمقارنة TableGPT2 بالنماذج مفتوحة المصدر والمحايدة مثل Qwen وDeepSeek، مما يضمن أداءً متوازنًا ومتعدد الاستخدامات للنموذج في مجموعة متنوعة من المهام دون تجاوز أي اختبار مرجعي واحد. كما قاموا أيضًا بتقديم معيار جديد وإصداره جزئيًا، وهو RealTabBench، والذي يركز على الجداول غير التقليدية والحقول المجهولة والاستعلامات المعقدة لتكون أكثر اتساقًا مع سيناريوهات الحياة الواقعية.
على الرغم من أن TableGPT2 يحقق أداءً متطورًا في التجارب، إلا أن التحديات لا تزال موجودة في نشر LLM في بيئات ذكاء الأعمال الحقيقية. وأشار الباحثون إلى أن اتجاهات البحث المستقبلية تشمل:
الترميز الخاص بالمجال: يمكّن LLM من التكيف بسرعة مع اللغات الخاصة بالمجال الخاص بالمؤسسة (DSLs) أو الكود الكاذب لتلبية الاحتياجات المحددة للبنية التحتية لبيانات المؤسسة بشكل أفضل.
تصميم متعدد الوكلاء: اكتشف كيفية دمج LLMs المتعددة بشكل فعال في نظام موحد للتعامل مع تعقيد تطبيقات العالم الحقيقي.
معالجة الجداول متعددة الاستخدامات: تحسين قدرة النموذج على التعامل مع الجداول غير المنتظمة، مثل الخلايا المدمجة والهياكل غير المتناسقة الشائعة في Excel وPages، للتعامل بشكل أفضل مع الأشكال المختلفة للبيانات الجدولية في العالم الحقيقي.
يمثل إطلاق TableGPT2 التقدم الكبير الذي حققته LLM في معالجة البيانات الجدولية، مما يوفر إمكانيات جديدة لذكاء الأعمال والتطبيقات الأخرى المستندة إلى البيانات. أعتقد أنه مع استمرار تعميق البحث، سيلعب TableGPT2 دورًا متزايد الأهمية في مجال تحليل البيانات في المستقبل.
عنوان الورقة: https://arxiv.org/pdf/2411.02059v1
لقد أحدث ظهور TableGPT2 فجرًا جديدًا في مجال ذكاء الأعمال، وتشير قدراته الفعالة في معالجة بيانات الجدول وقابلية التوسع القوية إلى أن تحليل البيانات سيكون أكثر ذكاءً وملاءمة في المستقبل. ونحن نتطلع إلى استخدام TableGPT2 على نطاق أوسع في المستقبل وتحقيق المزيد من القيمة لجميع مناحي الحياة.