علم محرر Downcodes أن فريق البحث الصيني نجح في إنشاء أكبر مجموعة بيانات عامة متعددة الوسائط للذكاء الاصطناعي "Infinity-MM" وقام بتدريب نموذج صغير Aquila-VL-2B بأداء ممتاز بناءً على مجموعة البيانات هذه. حقق النموذج نتائج ممتازة في اختبارات مرجعية متعددة، مما يدل على الإمكانات الهائلة للبيانات الاصطناعية في تحسين أداء نماذج الذكاء الاصطناعي. تحتوي مجموعة بيانات Infinity-MM على أنواع مختلفة من البيانات مثل أوصاف الصور وبيانات التعليمات المرئية، وتستخدم عملية إنشائها نماذج الذكاء الاصطناعي مفتوحة المصدر مثل RAM++ وMiniCPM-V، وتخضع لمعالجة متعددة المستويات لضمان جودة البيانات وتنوعها. يعتمد نموذج Aquila-VL-2B على بنية LLaVA-OneVision ويستخدم Qwen-2.5 كنموذج اللغة.
في الآونة الأخيرة، نجحت فرق البحث من العديد من المؤسسات الصينية في إنشاء مجموعة بيانات "Infinity-MM"، والتي تعد حاليًا واحدة من أكبر مجموعات بيانات الذكاء الاصطناعي العامة متعددة الوسائط، وقامت بتدريب نموذج صغير جديد بأداء ممتاز - —Aquila-VL-2B .
تحتوي مجموعة البيانات بشكل أساسي على أربع فئات رئيسية من البيانات: 10 ملايين وصف للصور، و24.4 مليون بيانات تعليمات مرئية عامة، و6 ملايين بيانات تعليمات مختارة عالية الجودة، و3 ملايين بيانات تم إنشاؤها بواسطة GPT-4 ونماذج الذكاء الاصطناعي الأخرى.
ومن ناحية الجيل، استفاد فريق البحث من نماذج الذكاء الاصطناعي الحالية مفتوحة المصدر. أولاً، يقوم نموذج RAM++ بتحليل الصورة واستخراج المعلومات المهمة، ثم توليد الأسئلة والأجوبة ذات الصلة. بالإضافة إلى ذلك، قام الفريق ببناء نظام تصنيف خاص لضمان جودة وتنوع البيانات الناتجة.
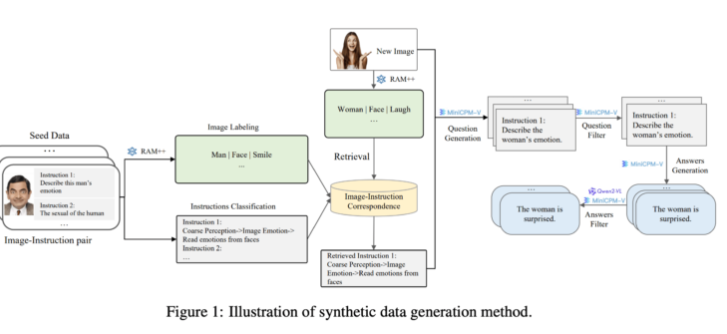
تستخدم طريقة توليد البيانات الاصطناعية هذه طريقة معالجة متعددة المستويات، تجمع بين نماذج RAM++ وMiniCPM-V لتوفير بيانات تدريب دقيقة لنظام الذكاء الاصطناعي من خلال التعرف على الصور وتصنيف التعليمات وتوليد الاستجابة.
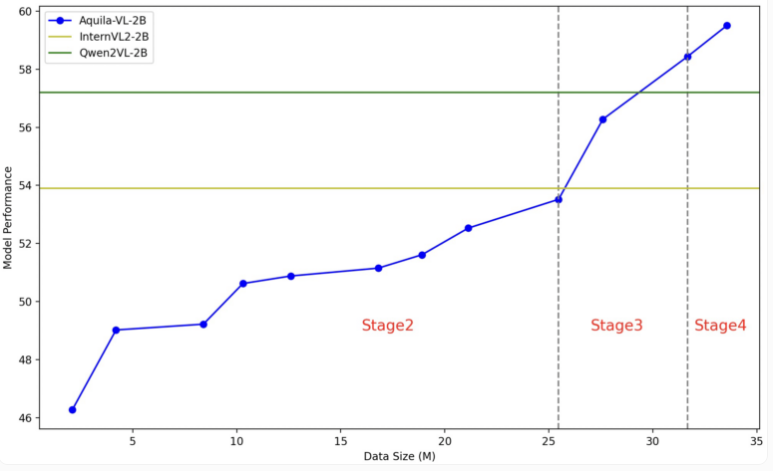
يعتمد نموذج Aquila-VL-2B على بنية LLaVA-OneVision، ويستخدم Qwen-2.5 كنموذج لغة، ويستخدم SigLIP لمعالجة الصور. ينقسم تدريب النموذج إلى أربع مراحل، مما يزيد من التعقيد تدريجيًا. في المرحلة الأولى، يتعلم النموذج الارتباطات الأساسية للصورة والنص؛ وتشمل المراحل اللاحقة مهام الرؤية العامة، وتنفيذ تعليمات محددة، وأخيرًا دمج البيانات المجمعة. يتم أيضًا تحسين دقة الصورة تدريجيًا أثناء التدريب.
وفي الاختبار، حقق Aquila-VL-2B أفضل نتيجة في الاختبار القائم على MMStar متعدد الوسائط بدرجة 54.9%، بحجم 2 مليار معلمة فقط. بالإضافة إلى ذلك، كان أداء النموذج جيدًا بشكل خاص في المهام الرياضية، حيث سجل 59% في اختبار MathVista، وهو ما يتجاوز بكثير الأنظمة المماثلة.
في اختبار فهم الصورة العامة، كان أداء Aquila-VL-2B جيدًا أيضًا، حيث حصل على نتيجة HallusionBench بنسبة 43% ودرجة MMBench التي بلغت 75.2%. وقال الباحثون إن إضافة البيانات المولدة صناعياً أدت إلى تحسين أداء النموذج بشكل كبير، ولولا استخدام هذه البيانات الإضافية لكان متوسط أداء النموذج قد انخفض بنسبة 2.4%.
هذه المرة قرر فريق البحث فتح مجموعة البيانات والنموذج لمجتمع البحث. استخدمت عملية التدريب بشكل أساسي Nvidia A100GPU والرقائق المحلية الصينية. يشير الإطلاق الناجح لـ Aquila-VL-2B إلى أن النماذج مفتوحة المصدر بدأت تلحق تدريجيًا باتجاه الأنظمة التقليدية مغلقة المصدر في أبحاث الذكاء الاصطناعي، مما يظهر بشكل خاص آفاقًا جيدة في استخدام بيانات التدريب الاصطناعية.
مدخل ورق Infinity-MM: https://arxiv.org/abs/2410.18558
مدخل مشروع Aquila-VL-2B: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
إن نجاح Aquila-VL-2B لا يثبت قوة الصين التقنية في مجال الذكاء الاصطناعي فحسب، بل يوفر أيضًا موارد قيمة لمجتمع المصادر المفتوحة. سيؤدي أدائها الفعال واستراتيجيتها المفتوحة إلى تعزيز تطوير تكنولوجيا الذكاء الاصطناعي متعددة الوسائط، ومن الجدير التطلع إلى تطبيقاتها المستقبلية في المزيد من المجالات.