لقد كان فهم الفيديو الطويل جدًا دائمًا مشكلة صعبة بالنسبة لنماذج اللغات الكبيرة متعددة الوسائط (MLLM). يصعب على النماذج الحالية معالجة بيانات الفيديو التي تتجاوز الحد الأقصى لطول السياق، كما يمثل توهين المعلومات والتكاليف الحسابية العالية تحديًا كبيرًا. علم محرر Downcodes أن معهد Zhiyuan للأبحاث والعديد من الجامعات قد اقترحوا نموذجًا للغة مرئية طويلة جدًا يسمى Video-XL، والذي تم تصميمه للتعامل بكفاءة مع مشكلات فهم الفيديو على مستوى الساعة. التكنولوجيا الأساسية لهذا النموذج هي "الملخص الكامن للسياق المرئي"، والذي يستخدم بذكاء إمكانات نمذجة السياق لـ LLM لضغط التمثيلات المرئية الطويلة في شكل أكثر إحكاما، على غرار تكثيف بقرة كاملة في وعاء من جوهر اللحم البقري، مما يجعل النموذج استيعاب المعلومات الأساسية بشكل أكثر كفاءة.
حاليًا، حققت نماذج اللغات الكبيرة متعددة الوسائط (MLLM) تقدمًا كبيرًا في مجال فهم الفيديو، لكن معالجة مقاطع الفيديو الطويلة للغاية لا تزال تمثل تحديًا. وذلك لأن MLLM تكافح عادةً للتعامل مع آلاف الرموز المرئية التي تتجاوز الحد الأقصى لطول السياق وتعاني من تسوس المعلومات الناتج عن تجميع الرموز المميزة. وفي الوقت نفسه، فإن العدد الكبير من علامات الفيديو سيؤدي أيضًا إلى تكاليف حسابية عالية.
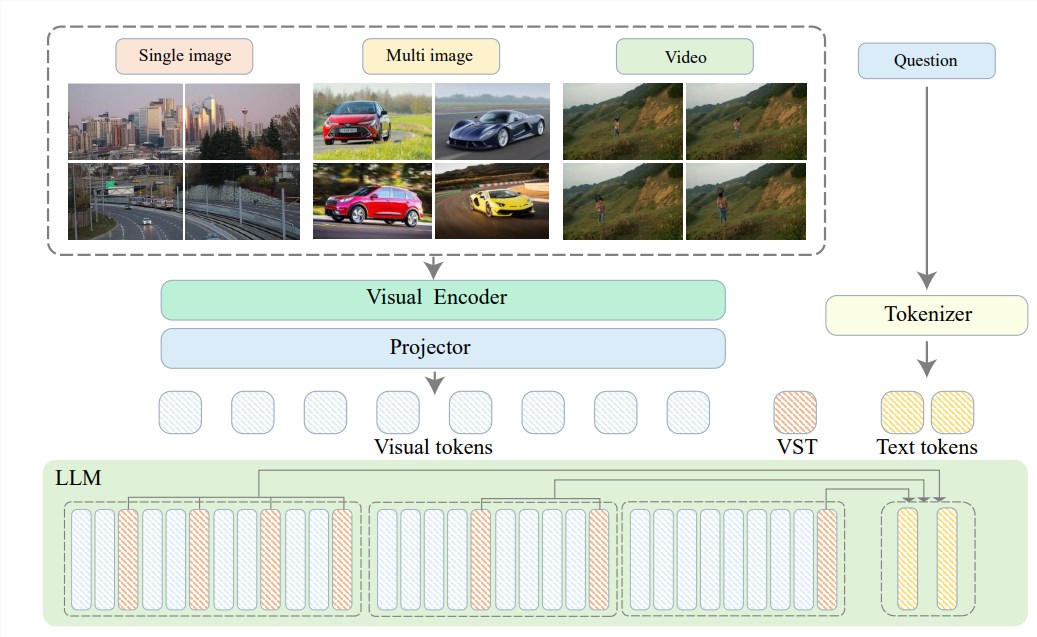
من أجل حل هذه المشاكل، تعاون معهد تشي يوان للأبحاث مع جامعة شنغهاي جياو تونغ، وجامعة رنمين الصينية، وجامعة بكين، وجامعة بكين للبريد والاتصالات السلكية واللاسلكية وجامعات أخرى لاقتراح Video-XL، وهو نظام فائق الوضوح مصمم لـ فهم فيديو فعال على مستوى الساعة. يكمن جوهر Video-XL في تقنية "التلخيص الكامن للسياق المرئي"، والتي تعزز إمكانات نمذجة السياق المتأصلة في LLM لضغط التمثيلات المرئية الطويلة بشكل فعال في شكل أكثر إحكاما.
بكل بساطة، يتم ضغط محتوى الفيديو إلى شكل أكثر انسيابية، تمامًا مثل تكثيف بقرة كاملة في وعاء من خلاصة اللحم البقري، وهو ما يسهل على النموذج هضمه وامتصاصه.
لا تعمل تقنية الضغط هذه على تحسين الكفاءة فحسب، بل تحافظ أيضًا على المعلومات الأساسية للفيديو بشكل فعال. كما تعلمون، غالبًا ما تكون مقاطع الفيديو الطويلة مليئة بالكثير من المعلومات الزائدة عن الحاجة، مثل قطعة قدم سيدة عجوز، طويلة ورائحة كريهة. يمكن لـ Video-XL حذف هذه المعلومات غير المفيدة بدقة والاحتفاظ بالأجزاء الأساسية فقط، مما يضمن أن النموذج لن يضل طريقه عند فهم محتوى الفيديو الطويل.
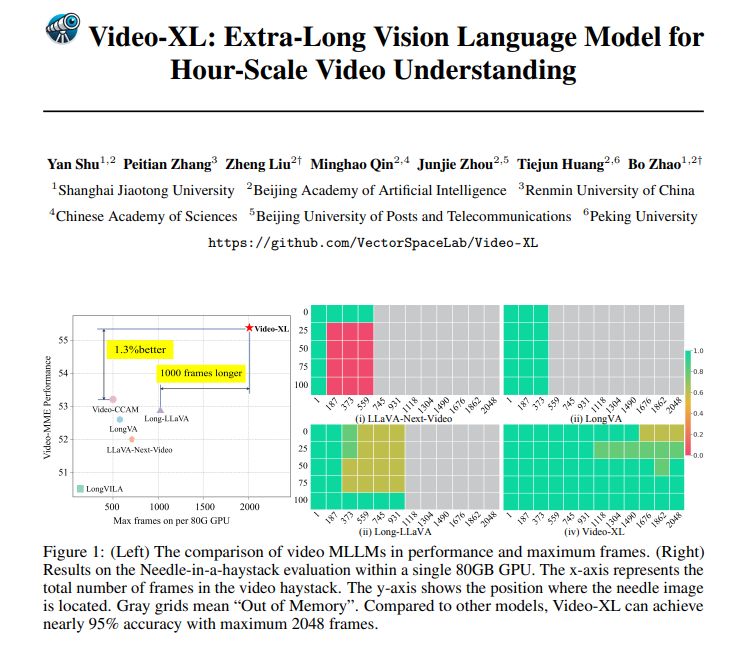
Video-XL ليس رائعًا من الناحية النظرية فحسب، بل إنه قادر أيضًا على الممارسة العملية. حقق Video-XL نتائج رائدة في العديد من معايير فهم الفيديو الطويل، خاصة في اختبار VNBench، حيث تزيد دقته بنسبة 10% تقريبًا عن أفضل الطرق الحالية.
والأكثر إثارة للإعجاب، أن Video-XL يحقق توازنًا مذهلاً بين الكفاءة والفعالية، فهو قادر على معالجة 2048 إطارًا من الفيديو على وحدة معالجة رسومات واحدة بسعة 80 جيجابايت مع الحفاظ على دقة تبلغ 95% تقريبًا في تقييم "الإبرة في كومة القش".
يتمتع Video-XL أيضًا بآفاق تطبيق واسعة. بالإضافة إلى القدرة على فهم مقاطع الفيديو الطويلة العامة، فهو قادر أيضًا على القيام بمهام محددة مثل تلخيص الفيلم واكتشاف شذوذ المراقبة والتعرف على موضع الإعلان.
وهذا يعني أنك لم تعد مضطرًا إلى تحمل حبكات طويلة عند مشاهدة الأفلام في المستقبل. يمكنك استخدام Video-XL مباشرة لإنشاء ملخص مبسط، مما يوفر الوقت والجهد أو يمكنك استخدامه لمراقبة لقطات المراقبة وتحديد الأحداث غير الطبيعية تلقائيًا وهو أكثر كفاءة من التتبع اليدوي.
عنوان المشروع: https://github.com/VectorSpaceLab/Video-XL
الورقة: https://arxiv.org/pdf/2409.14485
حقق Video-XL تقدمًا كبيرًا في مجال فهم الفيديو الطويل جدًا، حيث يوفر مزيجه المثالي من الكفاءة والدقة حلاً جديدًا لمعالجة الفيديو الطويل، وله آفاق تطبيق واسعة في المستقبل ويستحق التطلع إليه.