يستغرق التدريب على النماذج الكبيرة وقتًا طويلاً ويتطلب عمالة مكثفة، وقد أصبحت كيفية تحسين الكفاءة وتقليل استهلاك الطاقة قضية رئيسية في مجال الذكاء الاصطناعي. AdamW، باعتباره المُحسِّن الافتراضي للتدريب المسبق على Transformer، أصبح غير قادر تدريجيًا على التعامل مع النماذج الكبيرة بشكل متزايد. سيأخذك محرر Downcodes للتعرف على مُحسِّن جديد تم تطويره بواسطة فريق صيني - C-AdamW من خلال إستراتيجيته "الحذرة"، فهو يقلل بشكل كبير من استهلاك الطاقة مع ضمان سرعة التدريب واستقراره، ويجلب فوائد كبيرة للتدريب على النماذج الكبيرة. لإحداث ثورة في التغيير .
في عالم الذكاء الاصطناعي، يبدو أن العمل الجاد لتحقيق المعجزات هو القاعدة الذهبية. كلما كان النموذج أكبر، زادت البيانات، وكانت قوة الحوسبة أقوى، ويبدو أنه أقرب إلى الكأس المقدسة للذكاء. ومع ذلك، وراء هذا التطور السريع، هناك أيضًا ضغوط هائلة على التكلفة واستهلاك الطاقة.
من أجل جعل تدريب الذكاء الاصطناعي أكثر كفاءة، كان العلماء يبحثون عن أدوات تحسين أكثر قوة، مثل المدرب، لتوجيه معلمات النموذج للتحسين المستمر والوصول في النهاية إلى أفضل حالة. لقد كان AdamW، باعتباره المُحسِّن الافتراضي للتدريب المسبق على Transformer، بمثابة معيار الصناعة لسنوات عديدة. ومع ذلك، في مواجهة الحجم المتزايد للنموذج، بدأت شركة AdamW أيضًا في الظهور وكأنها غير قادرة على التعامل مع قدراتها.
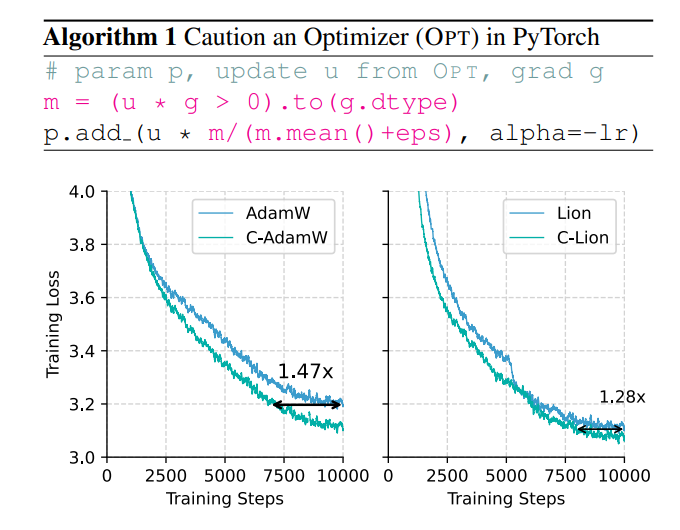
أليس هناك طريقة لزيادة سرعة التدريب مع تقليل استهلاك الطاقة؟ لا تقلق، فريق صيني بالكامل موجود هنا مع سلاحهم السري C-AdamW!
الاسم الكامل لـ C-AdamW هو Cautious AdamW، واسمها الصيني هو Cautious AdamW. ألا يبدو الأمر بوذيًا جدًا؟ نعم، الفكرة الأساسية لـ C-AdamW هي التفكير مرتين قبل التمثيل.

تخيل أن معلمات النموذج تشبه مجموعة من الأطفال النشيطين الذين يرغبون دائمًا في الركض. AdamW يشبه المعلم المتفاني، الذي يحاول توجيههم في الاتجاه الصحيح. لكن في بعض الأحيان، يشعر الأطفال بالحماس الشديد ويركضون في الاتجاه الخاطئ، مما يضيع الوقت والطاقة.
في هذا الوقت، يشبه C-AdamW شيخًا حكيمًا بزوج من العيون الثاقبة، قادر على تحديد ما إذا كان اتجاه التحديث صحيحًا بدقة. إذا كان الاتجاه خاطئًا، فسوف يقوم C-AdamW باستدعاء التوقف بشكل حاسم لمنع النموذج من المضي قدمًا في الطريق الخطأ.
تضمن هذه الإستراتيجية الحذرة أن كل تحديث يمكن أن يقلل بشكل فعال من وظيفة الخسارة، وبالتالي تسريع تقارب النموذج. تظهر النتائج التجريبية أن C-AdamW يزيد من سرعة التدريب إلى 1.47 مرة في تدريب Llama وMAE المسبق!
والأهم من ذلك، أن C-AdamW لا يتطلب أي نفقات حسابية إضافية تقريبًا ويمكن تنفيذه من خلال تعديل بسيط من سطر واحد للكود الموجود. وهذا يعني أنه يمكن للمطورين تطبيق C-AdamW بسهولة على نماذج التدريب المختلفة والاستمتاع بالسرعة والشغف!
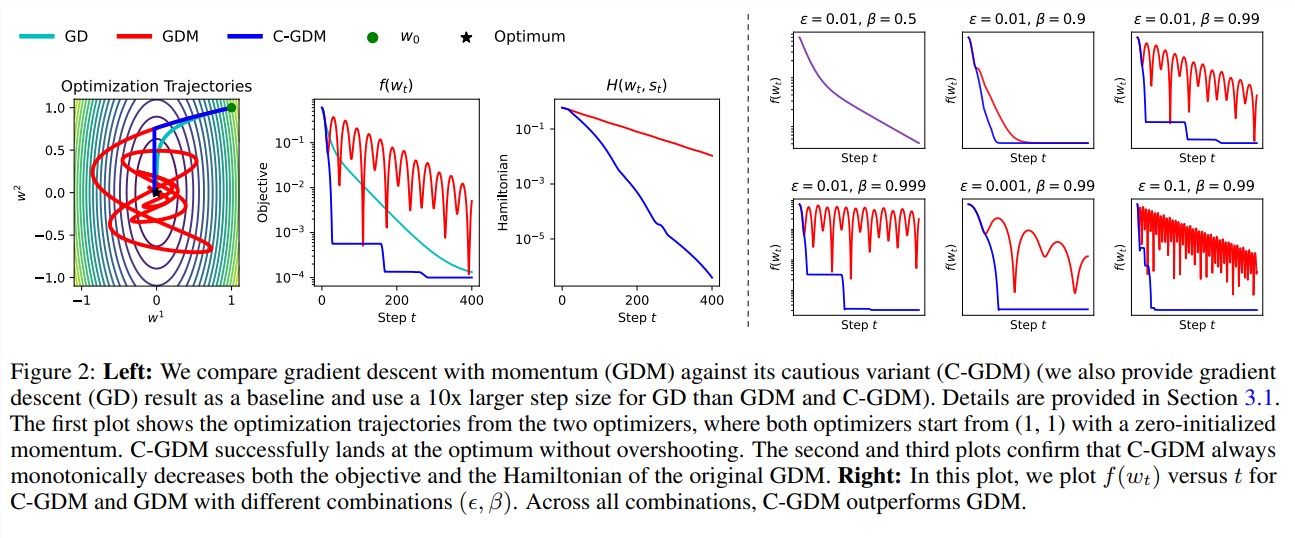
إن الشيء العظيم في C-AdamW هو أنه يحتفظ بوظيفة آدم الهاملتونية ولا يدمر ضمان التقارب في ظل تحليل ليابونوف. وهذا يعني أن C-AdamW ليس أسرع فحسب، بل إن استقراره مضمون أيضًا، ولن تكون هناك مشاكل مثل أعطال التدريب.
بالطبع، كونك بوذيًا لا يعني أنك لست مغامرًا. صرح فريق البحث أنهم سيستمرون في استكشاف وظائف ϕ الأكثر ثراءً وتطبيق الأقنعة في مساحة الميزات بدلاً من مساحة المعلمة لزيادة تحسين أداء C-AdamW.
من المتوقع أن يصبح C-AdamW هو المفضل الجديد في مجال التعلم العميق، مما يؤدي إلى تغييرات ثورية في نماذج التدريب الكبيرة!
عنوان الورقة: https://arxiv.org/abs/2411.16085
جيثب:
https://github.com/kyleliang919/C-Optim
يوفر ظهور C-AdamW أفكارًا جديدة لحل مشكلات كفاءة تدريب النماذج الكبيرة واستهلاك الطاقة، مما يجعلها واعدة جدًا للتطبيق. ومن المتوقع أن يتم تطبيق C-AdamW في المزيد من المجالات في المستقبل وتعزيز التطوير المستمر لتكنولوجيا الذكاء الاصطناعي. سيستمر محرر Downcodes في الاهتمام بالتقدم التكنولوجي ذي الصلة، لذا ترقبوا ذلك!