علم محرر Downcodes أن جامعة بكين وفرق البحث العلمي الأخرى قد أصدرت LLaVA-o1، وهو نموذج مفتوح المصدر ومتعدد الوسائط. تجاوز النموذج منافسين مثل Gemini وGPT-4o-mini وLlama في اختبارات قياس متعددة، كما أتاحت آلية التفكير "البطيء" الخاصة به أداء استدلال أكثر تعقيدًا، مقارنةً بـGPT-o1. سيجلب المصدر المفتوح لـ LLaVA-o1 حيوية جديدة للبحث والتطبيق في مجال الذكاء الاصطناعي متعدد الوسائط.
في الآونة الأخيرة، أعلنت جامعة بكين وفرق بحثية علمية أخرى عن إطلاق نموذج مفتوح المصدر متعدد الوسائط يسمى LLaVA-o1، والذي يقال إنه أول نموذج لغة بصرية قادر على التفكير التلقائي والمنهجي، مقارنة بـ GPT-o1.
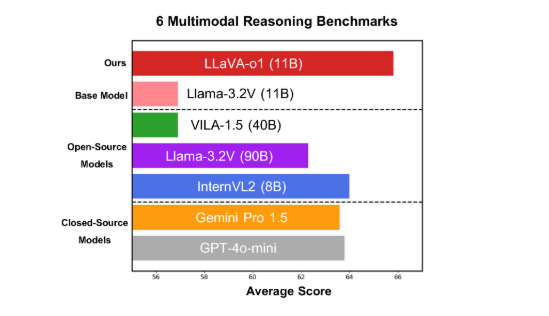
يعمل النموذج بشكل جيد على ستة معايير صعبة متعددة الوسائط، حيث يتفوق إصداره ذو المعلمة 11B على المنافسين الآخرين مثل Gemini-1.5-pro وGPT-4o-mini وLlama-3.2-90B-Vision-Instruct.
يعتمد LLaVA-o1 على نموذج Llama-3.2-Vision ويعتمد آلية تفكير "بطيئة التفكير"، والتي يمكنها إجراء عمليات تفكير أكثر تعقيدًا بشكل مستقل، متجاوزة الطريقة التقليدية لسلسلة التفكير السريعة.
في معيار الاستدلال متعدد الوسائط، تفوق أداء LLaVA-o1 على نموذجه الأساسي بنسبة 8.9%. النموذج فريد من نوعه حيث أن عملية الاستدلال الخاصة به تنقسم إلى أربع مراحل: التلخيص والتفسير البصري والتفكير المنطقي وتوليد الاستنتاجات. في النماذج التقليدية، غالبًا ما تكون عملية الاستدلال بسيطة نسبيًا ويمكن أن تؤدي بسهولة إلى إجابات خاطئة، بينما يضمن LLaVA-o1 إخراجًا أكثر دقة من خلال الاستدلال المنظم متعدد الخطوات.
على سبيل المثال، عند حل المشكلة "كم عدد الكائنات المتبقية بعد طرح جميع الكرات الصغيرة الساطعة والأشياء الأرجوانية؟"، سيلخص LLaVA-o1 المشكلة أولاً، ثم يستخرج المعلومات من الصورة، ثم يقوم بالتفكير خطوة بخطوة ، وأخيرا إعطاء الإجابة. يعمل هذا النهج المرحلي على تحسين قدرات التفكير المنهجي للنموذج، مما يجعله أكثر كفاءة في التعامل مع المشكلات المعقدة.

ومن الجدير بالذكر أن LLaVA-o1 يقدم طريقة بحث شعاع على مستوى المرحلة في عملية الاستدلال. يسمح هذا النهج للنموذج بإنشاء إجابات مرشحة متعددة في كل مرحلة من مراحل الاستدلال واختيار أفضل إجابة للانتقال إلى المرحلة التالية من الاستدلال، وبالتالي تحسين جودة الاستدلال الإجمالية بشكل ملحوظ. من خلال الضبط الدقيق وبيانات التدريب المعقولة الخاضعة للإشراف، يعمل LLaVA-o1 بشكل جيد بالمقارنة مع النماذج الأكبر أو مغلقة المصدر.
لا تعمل نتائج البحث التي أجراها فريق جامعة بكين على تعزيز تطوير الذكاء الاصطناعي متعدد الوسائط فحسب، بل توفر أيضًا أفكارًا وطرقًا جديدة لنماذج فهم اللغة المرئية المستقبلية. وذكر الفريق أن الكود وأوزان التدريب المسبق ومجموعات البيانات الخاصة بـ LLaVA-o1 ستكون مفتوحة المصدر بالكامل، وهم يتطلعون إلى المزيد من الباحثين والمطورين لاستكشاف هذا النموذج المبتكر وتطبيقه بشكل مشترك.
الورقة: https://arxiv.org/abs/2411.10440
جيثب:https://github.com/PKU-YuanGroup/LLaVA-o1
لا شك أن المصدر المفتوح لـ LLaVA-o1 سيعزز التطور التكنولوجي وابتكار التطبيقات في مجال الذكاء الاصطناعي متعدد الوسائط. إن آلية الاستدلال الفعالة والأداء الممتاز تجعلها مرجعًا مهمًا لأبحاث نماذج اللغة المرئية المستقبلية وتستحق الاهتمام والترقب. ونحن نتطلع إلى مشاركة المزيد من المطورين والترويج المشترك للتقدم في تكنولوجيا الذكاء الاصطناعي.