لقد ازدهر مجال الذكاء الاصطناعي مفتوح المصدر في السنوات الأخيرة، ولكن لا تزال هناك فجوة مقارنة بشركات التكنولوجيا الكبيرة. قوة الحوسبة ليست سوى جانب واحد، والجانب الأكثر أهمية هو عدم وجود حلول ما بعد التدريب. أحدث اختراق لـ AI2 (معهد ألين للذكاء الاصطناعي سابقًا) - برنامج Tülu3 لما بعد التدريب، يوفر سلاحًا قويًا لسد هذه الفجوة. سيمنحك محرر Downcodes فهمًا متعمقًا لكيفية تمكين هذه التقنية للذكاء الاصطناعي مفتوح المصدر وجعل نماذج اللغة الكبيرة التي كان من الصعب التحكم فيها في الأصل سهلة الاستخدام والتخصيص.
في مجال الذكاء الاصطناعي مفتوح المصدر، لا تنعكس الفجوة مع شركات التكنولوجيا الكبرى فقط في قوة الحوسبة. يعمل AI2 (المعروف سابقًا باسم معهد Allen للذكاء الاصطناعي) على سد هذه الفجوة من خلال سلسلة من المبادرات الرائدة. إن برنامج ما بعد التدريب Tülu3 الذي تم إصداره حديثًا يجعل من السهل تحويل نماذج اللغة الأصلية الكبيرة إلى أنظمة ذكاء اصطناعي عملية.
على عكس الإدراك الشائع، لا يمكن استخدام نماذج اللغة الأساسية مباشرة بعد التدريب المسبق. وفي الواقع، فإن عملية ما بعد التدريب هي الرابط الرئيسي الذي يحدد القيمة النهائية للنموذج. وفي هذه المرحلة يتحول النموذج من شبكة كلي العلم تفتقر إلى الحكم إلى أداة عملية ذات توجه وظيفي محدد.
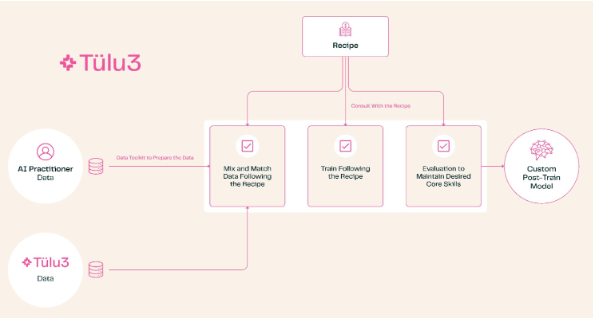
لفترة طويلة، كانت الشركات الكبرى تلتزم السرية بشأن برامج ما بعد التدريب. في حين أنه يمكن لأي شخص بناء نموذج باستخدام أحدث التقنيات، إلا أن تقنيات ما بعد التدريب الفريدة مطلوبة لجعل النموذج مفيدًا في مجالات محددة، مثل الاستشارة النفسية أو تحليل الأبحاث. حتى بالنسبة لمشاريع مثل Meta's Llama، والتي يتم الإعلان عنها على أنها مفتوحة المصدر، فإن مصدر نموذجها الأصلي وطرق التدريب الشائعة لا تزال سرية تمامًا.
ظهور Tülu3 يغير هذا الوضع. تغطي هذه المجموعة الكاملة من حلول ما بعد التدريب نطاقًا كاملاً من العمليات بدءًا من اختيار الموضوع وحتى إدارة البيانات، ومن التعلم المعزز إلى الضبط الدقيق. يمكن للمستخدمين ضبط قدرات النموذج وفقًا لاحتياجاتهم، مثل تعزيز قدرات الرياضيات والبرمجة، أو تقليل أولوية المعالجة متعددة اللغات.
يُظهر اختبار AI2 أن أداء النموذج الذي تم تدريبه بواسطة Tülu3 قد وصل إلى مستوى أعلى النماذج مفتوحة المصدر. يعد هذا الإنجاز مهمًا: فهو يوفر للشركات خيارًا مستقلاً تمامًا ويمكن التحكم فيه. خاصة بالنسبة للمؤسسات التي تتعامل مع البيانات الحساسة، مثل الأبحاث الطبية، فإنها لم تعد بحاجة إلى الاعتماد على واجهات برمجة التطبيقات التابعة لجهات خارجية أو الخدمات المخصصة، حيث يمكنها إكمال عملية التدريب بأكملها محليًا، مما يوفر التكاليف ويحمي الخصوصية.
لم تقم شركة AI2 بإصدار هذا الحل فحسب، بل أخذت أيضًا زمام المبادرة في تطبيقه على منتجاتها الخاصة. على الرغم من أن نتائج الاختبار الحالية تعتمد على نموذج Llama، إلا أن لديهم خططًا لإطلاق نموذج جديد يعتمد على OLMo الخاص بهم ويتم تدريبه بواسطة Tülu3، والذي سيكون حلاً مفتوح المصدر تمامًا من البداية إلى النهاية.
لا تُظهر هذه التقنية مفتوحة المصدر فقط تصميم AI2 على تعزيز إضفاء الطابع الديمقراطي على الذكاء الاصطناعي، ولكنها تضخ أيضًا دفعة في مجتمع الذكاء الاصطناعي مفتوح المصدر بأكمله. إنه يقربنا خطوة واحدة من نظام بيئي للذكاء الاصطناعي مفتوح وشفاف حقًا.
يمثل المصدر المفتوح لـ Tülu3 خطوة كبيرة إلى الأمام في مجال الذكاء الاصطناعي مفتوح المصدر، فهو يخفض عتبة تطبيقات الذكاء الاصطناعي، ويعزز العدالة ومشاركة تكنولوجيا الذكاء الاصطناعي، ويوفر إمكانيات غير محدودة لتطوير الذكاء الاصطناعي في المستقبل. ونحن نتطلع إلى ظهور المزيد من المشاريع المماثلة مفتوحة المصدر لبناء نظام بيئي أكثر ازدهارًا للذكاء الاصطناعي.