هل أنت مهتم بالتكنولوجيا الكامنة وراء منتجات الذكاء الاصطناعي مثل ChatGPT وWenxinyiyan؟ يعتمدون جميعًا على نماذج اللغات الكبيرة (LLM). سيأخذك محرر Downcodes إلى فهم مبدأ تشغيل LLM بطريقة بسيطة وسهلة الفهم، حتى لو كان لديك مستوى رياضيات للصف الثاني فقط، فيمكنك فهمه بسهولة! سنبدأ من المفاهيم الأساسية للشبكات العصبية ونشرح تدريجيًا تدريب النماذج والتقنيات المتقدمة والتقنيات الأساسية مثل GPT وهندسة المحولات، بحيث يكون لديك فهم واضح لماجستير في القانون.
هل سمعت عن الذكاء الاصطناعي المتقدم مثل ChatGPT وWen Xinyiyan؟ التكنولوجيا الأساسية التي تقف وراءها هي "نموذج اللغة الكبير" (LLM). هل تجد الأمر معقدًا وصعب الفهم؟ لا تقلق، حتى لو كان لديك مستوى رياضيات للصف الثاني فقط، فيمكنك بسهولة فهم مبدأ تشغيل LLM بعد قراءة هذه المقالة!
الشبكات العصبية: سحر الأرقام
أولاً، نحتاج إلى معرفة أن الشبكة العصبية تشبه الكمبيوتر العملاق، حيث يمكنها معالجة الأرقام فقط. يجب أن يكون كل من المدخلات والمخرجات أرقامًا. فكيف نجعله يفهم النص؟
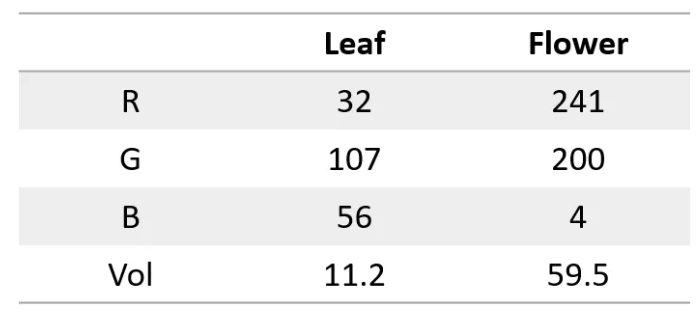
السر هو تحويل الكلمات إلى أرقام، على سبيل المثال، يمكننا تمثيل كل حرف برقم، مثل أ=1، ب=2، وهكذا. بهذه الطريقة، يمكن للشبكة العصبية "قراءة" النص.
تدريب النموذج: دع الشبكة "تتعلم" اللغة
بالنسبة للنص الرقمي، فإن الخطوة التالية هي تدريب النموذج والسماح للشبكة العصبية "بتعلم" قواعد اللغة.
تشبه عملية التدريب ممارسة لعبة التخمين. نعرض على الشبكة بعض النصوص، مثل "هامبتي دمبتي"، ونطلب منها تخمين الحرف التالي. إذا خمن بشكل صحيح، نمنحه مكافأة؛ وإذا خمن بشكل خاطئ، نمنحه عقوبة. من خلال التخمين والتعديل المستمر، يمكن للشبكة التنبؤ بالحرف التالي بدقة متزايدة، وفي النهاية إنتاج جمل كاملة مثل "هامبتي دمبتي جلس على الحائط".
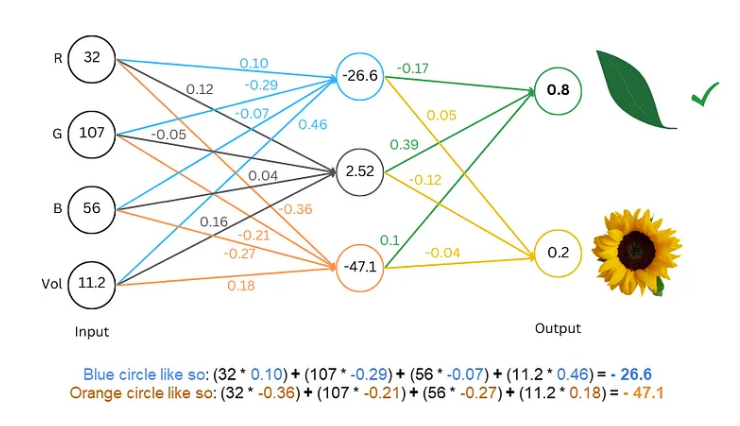
التقنيات المتقدمة: جعل النموذج أكثر "ذكاءً"
ومن أجل جعل النموذج أكثر "ذكاءً"، ابتكر الباحثون العديد من التقنيات المتقدمة، مثل:
تضمين الكلمات: بدلاً من استخدام أرقام بسيطة لتمثيل الحروف، نستخدم مجموعة من الأرقام (المتجهات) لتمثيل كل كلمة، والتي يمكن أن تصف معنى الكلمة بشكل أكمل.
تجزئة الكلمات الفرعية: تقسيم الكلمات إلى وحدات أصغر (كلمات فرعية)، مثل تقسيم "القطط" إلى "قطة" و"س"، مما قد يقلل من المفردات ويحسن الكفاءة.
آلية الانتباه الذاتي: عندما يتنبأ النموذج بالكلمة التالية، فإنه يقوم بضبط وزن التوقع بناءً على جميع الكلمات الموجودة في السياق، تمامًا كما نفهم معنى الكلمة بناءً على السياق عند القراءة.
الاتصال المتبقي: لتجنب صعوبات التدريب الناجمة عن وجود عدد كبير جدًا من طبقات الشبكة، اخترع الباحثون الاتصال المتبقي لتسهيل تعلم الشبكة.
آلية الانتباه متعدد الرؤوس: من خلال تشغيل آليات انتباه متعددة بالتوازي، يمكن للنموذج فهم السياق من وجهات نظر مختلفة وتحسين دقة التنبؤات.
التشفير الموضعي: لكي يتمكن النموذج من فهم ترتيب الكلمات، سيقوم الباحثون بإضافة المعلومات الموضعية إلى تضمينات الكلمات، تمامًا كما ننتبه إلى ترتيب الكلمات عند القراءة.
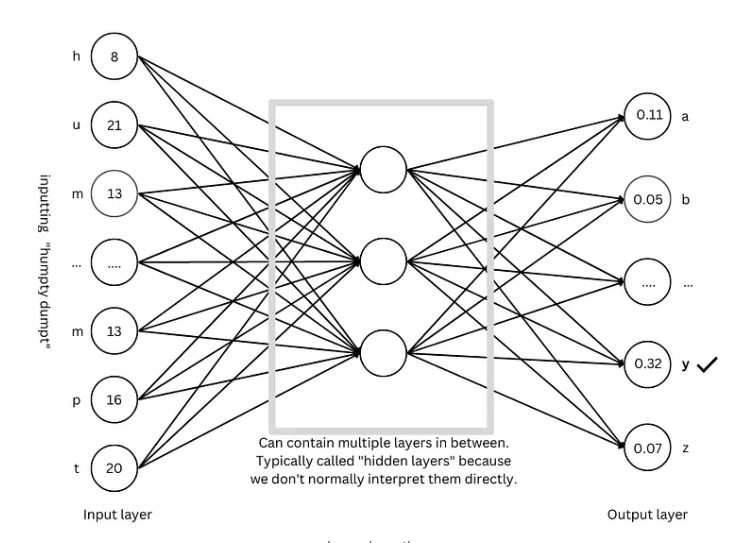
بنية GPT: "المخطط" لنماذج اللغة واسعة النطاق
تعد بنية GPT واحدة من أكثر معماريات نماذج اللغة واسعة النطاق شيوعًا في الوقت الحالي، وهي تشبه "المخطط" الذي يوجه تصميم النموذج وتدريبه. تجمع بنية GPT بذكاء بين التقنيات المتقدمة المذكورة أعلاه لتمكين النموذج من تعلم اللغة وتوليدها بكفاءة.
هندسة المحولات: "ثورة" نماذج اللغة
تعد بنية المحولات إنجازًا كبيرًا في مجال نماذج اللغة في السنوات الأخيرة، فهي لا تعمل على تحسين دقة التنبؤ فحسب، بل تقلل أيضًا من صعوبة التدريب، وتضع الأساس لتطوير نماذج لغوية واسعة النطاق. تطورت بنية GPT أيضًا بناءً على بنية Transformer.
المرجع: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
آمل أن يساعدك الشرح الذي قدمه محرر Downcodes في فهم مبادئ تشغيل نماذج اللغات الكبيرة. بالطبع، لا تزال تكنولوجيا LLM في طور التطوير. هذه المقالة هي مجرد غيض من فيض. المزيد والمزيد من المحتوى المتعمق يتطلب منك مواصلة التعلم والاستكشاف.