علم محرر Downcodes أن Meta أصدرت مؤخرًا أمر حوار متعدد اللغات جديدًا بعد اختبار قياس القدرة Multi-IF، ويغطي المعيار ثماني لغات ويحتوي على 4501 مهمة حوار ثلاثية الجولات، تهدف إلى تقييم أكبر بشكل أكثر شمولاً النماذج اللغوية (LLM) في التطبيقات العملية. على عكس معايير التقييم الحالية التي تركز بشكل أساسي على الحوار أحادي المنعطف والمهام ذات اللغة الواحدة، يركز Multi-IF على فحص قدرة النموذج في سيناريوهات معقدة متعددة المنعطفات ومتعددة اللغات، مما يوفر اتجاهًا أكثر وضوحًا لتحسين LLM.
أصدرت Meta مؤخرًا اختبارًا قياسيًا جديدًا يسمى Multi-IF، والذي تم تصميمه لتقييم التعليمات التالية لقدرة نماذج اللغات الكبيرة (LLM) في المحادثات متعددة الأدوار والبيئات متعددة اللغات. يغطي هذا المعيار ثماني لغات ويحتوي على 4501 مهمة حوار ثلاثية الأدوار، مع التركيز على أداء النماذج الحالية في سيناريوهات معقدة متعددة الأدوار ومتعددة اللغات.
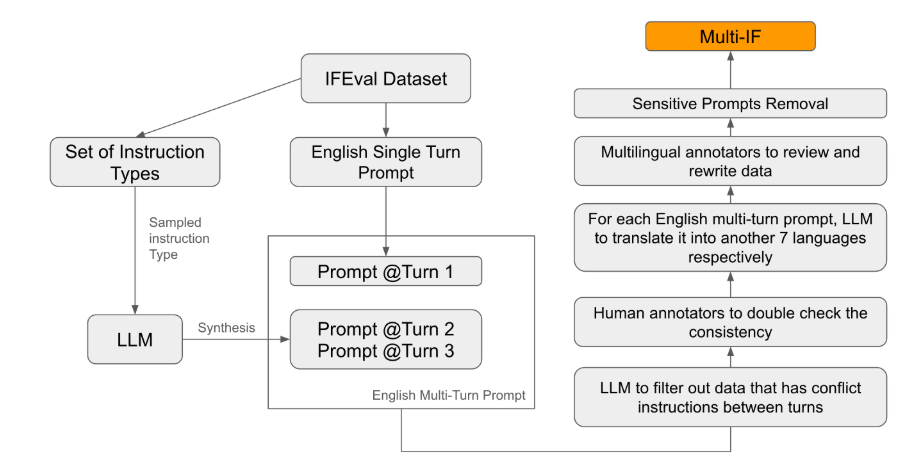
من بين معايير التقييم الحالية، يركز معظمها على الحوار الفردي والمهام ذات اللغة الواحدة، والتي يصعب أن تعكس أداء النموذج بشكل كامل في التطبيقات العملية. إن إطلاق Multi-IF يهدف إلى سد هذه الفجوة. قام فريق البحث بإنشاء سيناريوهات حوار معقدة من خلال توسيع جولة واحدة من التعليمات إلى جولات متعددة من التعليمات، والتأكد من أن كل جولة من التعليمات كانت متماسكة وتقدمية منطقيًا. بالإضافة إلى ذلك، تحقق مجموعة البيانات أيضًا دعمًا متعدد اللغات من خلال خطوات مثل الترجمة الآلية والتدقيق اليدوي.
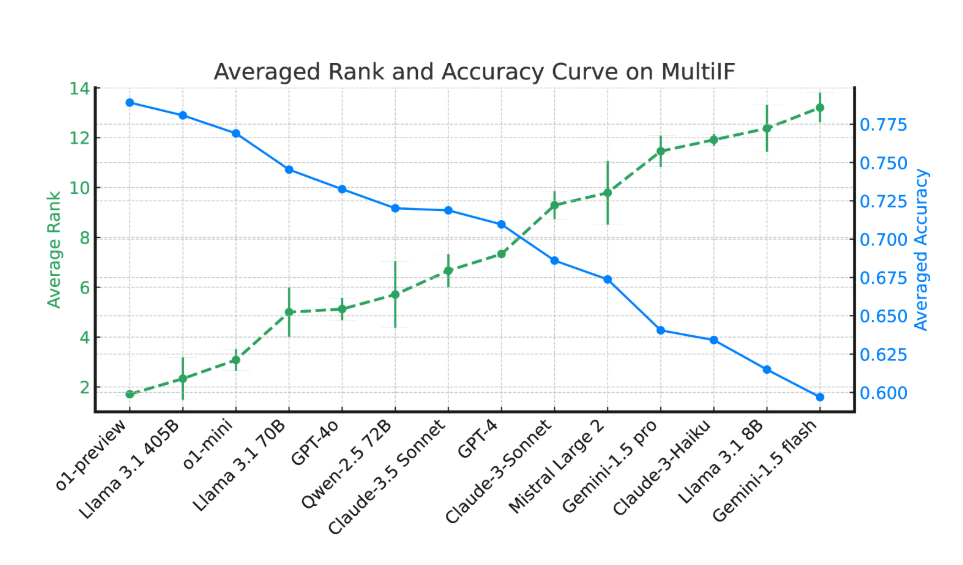
تظهر النتائج التجريبية أن أداء معظم LLMs ينخفض بشكل ملحوظ خلال جولات الحوار المتعددة. وبأخذ نموذج المعاينة o1 كمثال، كان متوسط الدقة في الجولة الأولى 87.7%، لكنه انخفض إلى 70.7% في الجولة الثالثة. خاصة في اللغات التي تحتوي على نصوص غير لاتينية، مثل الهندية والروسية والصينية، يكون أداء النموذج أقل بشكل عام من أداء اللغة الإنجليزية، مما يظهر قيودًا في المهام متعددة اللغات.
في تقييم 14 نموذجًا لغة متطورًا، كان أداء o1-preview وLlama3.1405B هو الأفضل، مع متوسط معدلات دقة تبلغ 78.9% و78.1% في ثلاث جولات من التعليمات على التوالي. ومع ذلك، عبر جولات متعددة من الحوار، أظهرت جميع النماذج انخفاضًا عامًا في قدرتها على اتباع التعليمات، مما يعكس التحديات التي تواجهها النماذج في المهام المعقدة. قدم فريق البحث أيضًا "معدل نسيان التعليمات" (IFR) لقياس ظاهرة نسيان التعليمات الخاصة بالنموذج في جولات متعددة من الحوار. وتظهر النتائج أن النماذج عالية الأداء تؤدي أداءً جيدًا نسبيًا في هذا الصدد.
يوفر إصدار Multi-IF للباحثين معيارًا صعبًا ويعزز تطوير LLM في العولمة والتطبيقات متعددة اللغات. إن إطلاق هذا المعيار لا يكشف فقط عن أوجه القصور في النماذج الحالية في المهام متعددة الجولات ومتعددة اللغات، ولكنه يوفر أيضًا اتجاهًا واضحًا للتحسينات المستقبلية.
الورقة: https://arxiv.org/html/2410.15553v2
يوفر إصدار اختبار قياس Multi-IF مرجعًا مهمًا للبحث في نماذج اللغات الكبيرة في الحوار متعدد المنعطفات والمعالجة متعددة اللغات، كما يشير إلى الطريق لتحسينات النماذج المستقبلية. ومن المتوقع أن يظهر المزيد والمزيد من حاملي شهادات LLM في المستقبل للتعامل بشكل أفضل مع تحديات المهام المعقدة متعددة اللغات.