أصدر فريق Emu3 التابع لمعهد Zhiyuan للأبحاث النموذج الثوري متعدد الوسائط Emu3، الذي يدمر بنية النموذج التقليدية متعددة الوسائط، ويتدرب بناءً على التنبؤ الرمزي التالي فقط، ويحقق أداء SOTA في مهام التوليد والإدراك. يقوم فريق Emu3 برمز الصور والنصوص ومقاطع الفيديو بذكاء إلى مساحات منفصلة ويدرب نموذج محول واحد على تسلسلات مختلطة متعددة الوسائط، مما يحقق توحيد المهام متعددة الوسائط دون الاعتماد على بنيات الانتشار أو التجميع، مما يوفر مجالًا متعدد الوسائط يجلب اختراقات جديدة.
أصدر فريق Emu3 من معهد Zhiyuan للأبحاث نموذجًا جديدًا متعدد الوسائط Emu3. يتم تدريب هذا النموذج فقط بناءً على التنبؤ الرمزي التالي، مما يؤدي إلى تخريب نموذج الانتشار التقليدي وبنية النموذج المركب، وتحقيق النتائج في كل من مهام التوليد والإدراك -من بين الفن الأداء.
لطالما اعتبر التنبؤ بالرمز التالي طريقًا واعدًا نحو الذكاء العام الاصطناعي (AGI)، لكنه كان أداؤه ضعيفًا في المهام متعددة الوسائط. في الوقت الحالي، لا يزال مجال الوسائط المتعددة يهيمن عليه نماذج الانتشار (مثل الانتشار المستقر) والنماذج المركبة (مثل الجمع بين CLIP وLLM). يقوم فريق Emu3 بترميز الصور والنصوص ومقاطع الفيديو في مساحات منفصلة وتدريب نموذج محول واحد من الصفر على تسلسلات مختلطة متعددة الوسائط، وبالتالي توحيد المهام متعددة الوسائط دون الاعتماد على الانتشار أو البنى التوافقية.
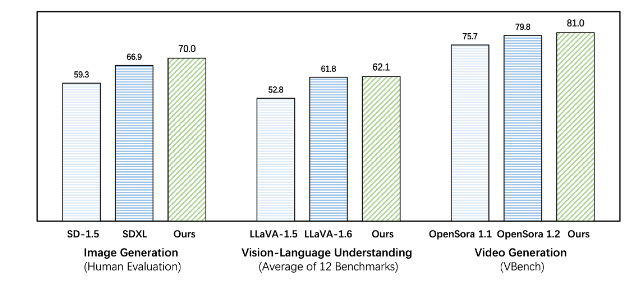
يتفوق Emu3 على النماذج الحالية الخاصة بالمهمة في كل من مهام التوليد والإدراك، حتى أنه يتفوق على النماذج الرئيسية مثل SDXL وLLaVA-1.6. Emu3 قادر أيضًا على إنشاء مقاطع فيديو عالية الدقة من خلال التنبؤ بالرمز المميز التالي في تسلسل الفيديو. على عكس Sora، الذي يستخدم نموذج نشر الفيديو لإنشاء مقاطع فيديو من الضوضاء، يقوم Emu3 بإنشاء مقاطع فيديو بطريقة سببية من خلال التنبؤ بالرمز المميز التالي في تسلسل الفيديو. يمكن للنموذج محاكاة جوانب معينة من بيئات العالم الحقيقي والأشخاص والحيوانات والتنبؤ بما سيحدث بعد ذلك في ضوء سياق الفيديو.
يعمل Emu3 على تبسيط تصميم النماذج المعقدة متعددة الوسائط ويركز التركيز على الرموز المميزة، مما يفتح إمكانات التوسع الهائلة أثناء التدريب والاستدلال. تظهر نتائج البحث أن التنبؤ بالرمز التالي هو وسيلة فعالة لبناء ذكاء عام متعدد الوسائط يتجاوز اللغة. لدعم المزيد من الأبحاث في هذا المجال، يمتلك فريق Emu3 تقنيات ونماذج رئيسية مفتوحة المصدر، بما في ذلك أداة رمزية مرئية قوية يمكنها تحويل مقاطع الفيديو والصور إلى رموز منفصلة، والتي لم تكن متاحة للعامة من قبل.
يشير نجاح Emu3 إلى الاتجاه نحو التطوير المستقبلي للنماذج متعددة الوسائط ويجلب أملًا جديدًا لتحقيق الذكاء الاصطناعي العام.
عنوان المشروع: https://github.com/baaivision/Emu3
يلخص محرر Downcodes ما يلي: يمثل ظهور نموذج Emu3 علامة فارقة جديدة في مجال الوسائط المتعددة. توفر هندسته البسيطة وأدائه القوي أفكارًا واتجاهات جديدة لأبحاث الذكاء الاصطناعي العام المستقبلية. تعمل إستراتيجية المصدر المفتوح أيضًا على تعزيز التطوير المشترك للأوساط الأكاديمية والصناعية، ومن الجدير التطلع إلى المزيد من الإنجازات في المستقبل.