في السنوات الأخيرة، حقق الذكاء الاصطناعي تقدمًا كبيرًا في مختلف المجالات، لكن قدرته على التفكير الرياضي كانت دائمًا بمثابة عنق الزجاجة. واليوم، يوفر ظهور معيار جديد يسمى FrontierMath مقياسًا جديدًا لتقييم القدرات الرياضية للذكاء الاصطناعي. فهو يدفع بقدرات التفكير الرياضي للذكاء الاصطناعي إلى حدود غير مسبوقة ويفرض تحديات شديدة على نماذج الذكاء الاصطناعي الحالية. سيأخذك محرر Downcodes إلى فهم متعمق لـ FrontierMath ومعرفة كيف يفسد فهمنا لقدرات الذكاء الاصطناعي الرياضية.
في عالم الذكاء الاصطناعي الفسيح، كانت الرياضيات تعتبر ذات يوم المعقل الأخير للذكاء الآلي. اليوم، ظهر اختبار قياسي جديد يسمى FrontierMath، مما دفع قدرات الذكاء الاصطناعي في التفكير الرياضي إلى حدود غير مسبوقة.
لقد تعاونت Epoch AI مع أكثر من 60 من أفضل العقول في عالم الرياضيات لإنشاء مجال تحدي الذكاء الاصطناعي هذا والذي يمكن أن يطلق عليه أولمبياد الرياضيات. هذا ليس اختبارًا تقنيًا فحسب، بل هو أيضًا الاختبار النهائي للحكمة الرياضية للذكاء الاصطناعي.
تخيل معملًا مليئًا بكبار علماء الرياضيات في العالم، الذين قاموا بصياغة مئات من الألغاز الرياضية التي تفوق خيال الناس العاديين. تشمل هذه المسائل أحدث المجالات الرياضية مثل نظرية الأعداد، والتحليل الحقيقي، والهندسة الجبرية، ونظرية الفئات، وهي ذات تعقيد مذهل. حتى عبقري الرياضيات الحائز على الميدالية الذهبية في أولمبياد الرياضيات الدولي يحتاج إلى ساعات أو حتى أيام لحل مسألة ما.
ومن المثير للصدمة أن أداء نماذج الذكاء الاصطناعي الحديثة الحالية كان مخيبا للآمال على هذا المعيار: فلم يتمكن أي نموذج من حل أكثر من 2% من المشاكل. وكانت هذه النتيجة بمثابة دعوة للاستيقاظ وصفعة للذكاء الاصطناعي على وجهه.
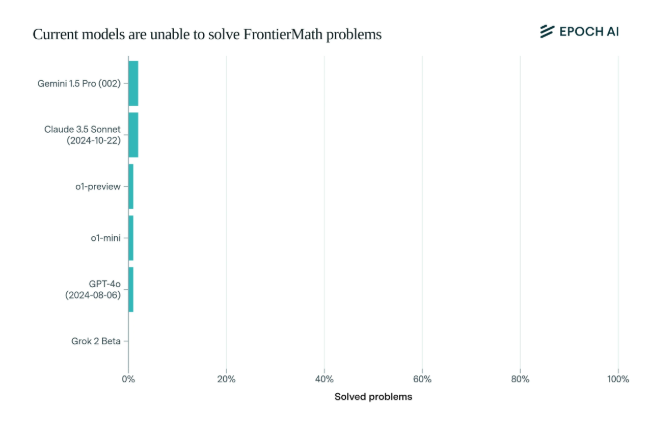
ما يجعل FrontierMath فريدًا هو آلية التقييم الصارمة. لقد وصل الذكاء الاصطناعي إلى الحد الأقصى لمعايير الاختبارات الرياضية التقليدية مثل MATH وGSM8K، ويستخدم هذا المعيار الجديد أسئلة جديدة غير منشورة ونظام تحقق آلي لتجنب تلوث البيانات بشكل فعال واختبار قدرات التفكير الرياضي للذكاء الاصطناعي.
النماذج الرئيسية لأفضل شركات الذكاء الاصطناعي، مثل OpenAI، وAnthropic، وGoogle DeepMind، والتي اجتذبت الكثير من الاهتمام، انقلبت بشكل جماعي في هذا الاختبار. ويعكس هذا فلسفة تقنية عميقة: بالنسبة لأجهزة الكمبيوتر، قد تكون المشكلات الرياضية التي تبدو معقدة سهلة، ولكن المهام التي يجدها البشر بسيطة قد تجعل الذكاء الاصطناعي عاجزًا.
وكما قال أندريه كارباثي، فإن هذا يؤكد مفارقة مورافيك: إن صعوبة المهام الذكية بين البشر والآلات غالبًا ما تكون غير بديهية. لا يعد هذا الاختبار المعياري مجرد اختبار صارم لقدرات الذكاء الاصطناعي، ولكنه أيضًا حافز لتطور الذكاء الاصطناعي إلى أبعاد أعلى.
بالنسبة لمجتمع الرياضيات والباحثين في مجال الذكاء الاصطناعي، فإن FrontierMath يشبه جبل إيفرست الذي لم يتم غزوه. فهو لا يختبر المعرفة والمهارات فحسب، بل يختبر أيضًا البصيرة والتفكير الإبداعي. وفي المستقبل، من يستطيع أن يأخذ زمام المبادرة في تسلق هذه الذروة من الذكاء سيتم تسجيله في تاريخ تطور الذكاء الاصطناعي.
إن ظهور اختبار FrontierMath المعياري ليس فقط اختبارًا صارمًا لمستوى تكنولوجيا الذكاء الاصطناعي الحالي، ولكنه يشير أيضًا إلى اتجاه تطوير الذكاء الاصطناعي في المستقبل، ويشير إلى أن الذكاء الاصطناعي لا يزال أمامه طريق طويل ليقطعه في مجال الاستدلال الرياضي كما أنه يحفز البحث ويواصل الباحثون الاستكشاف والابتكار لاختراق اختناقات التقنيات الحالية.