اليوم، مع التفاعل المتكرر بين الإنسان والحاسوب، لا تزال تجربة المحادثة السلسة والطبيعية تمثل تحديًا. سيقدم لكم محرر Downcodes اليوم تقنية متقدمة - Moshi، وهو نظام حوار صوتي مزدوج الاتجاه تم تطويره بواسطة Kyutai Labs. وهي ملتزمة بإنشاء محادثة أكثر طبيعية وسلاسة بين الإنسان والآلة، مما يجعل التواصل مع الآلات سهلاً مثل التحدث مع الأصدقاء. يكمن الابتكار الأساسي لـ Moshi في أسلوبها الفريد في تحويل الكلام إلى كلام وتقنيتها المتقدمة التي يمكنها معالجة تدفقات صوتية متعددة في وقت واحد، دعونا نلقي نظرة فاحصة على العديد من النقاط البارزة في Moshi.
في هذا العصر الرقمي، أصبحت محادثاتنا مع الآلات جزءًا من حياتنا اليومية. ومع ذلك، غالبًا ما تفتقر هذه الحوارات إلى الطبيعة والتدفق، مما يجعلها تبدو أقل إنسانية. ومع ذلك، قد يكون ذلك على وشك التغيير. يعد Moshi، وهو نظام حوار صوتي مزدوج الاتجاه تم تطويره بواسطة Kyutai Labs، إيذانًا بعصر جديد من الحوار الطبيعي والأكثر سلاسة بين الإنسان والكمبيوتر.
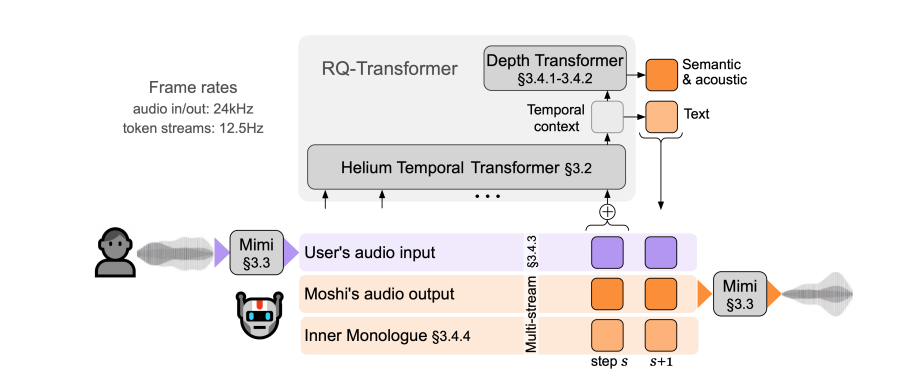
موشي هو نموذج حوار يعتمد على الكلام والنص، ويكمن ابتكاره الأساسي في التعامل مع الحوار باعتباره عملية تحويل الكلام إلى كلام. تعمل هذه الطريقة على حل العديد من المشكلات الموجودة في أنظمة الحوار الصوتي التقليدية بذكاء، مثل التأخير وفقدان المعلومات والقيود المفروضة على تبادل الأدوار. يعتبر Moshi فريدًا من حيث أنه يمكنه الاستماع والتحدث في نفس الوقت، تمامًا مثلنا نحن البشر، ويمكنه التعامل مع التداخلات والمقاطعات والمداخلات في المحادثات بسهولة.
تنبع وظائف Moshi القوية من ثلاث تقنيات أساسية. الأول هو نموذج لغة النص الهيليوم، وهو عقل موشي، ويحتوي على 7 مليارات معلمة ويتمتع بقدرات قوية على فهم اللغة وتوليدها من خلال تعلم بيانات إنجليزية ضخمة. التالي هو برنامج Mimi Neural Audio Codec، الذي يعمل بمثابة فم وأذني موشي، حيث يقوم بالتحويل بين إشارات الكلام والوحدات المنفصلة التي يمكن للنموذج فهمها. وأخيرًا، يعد نموذج اللغة الصوتية متعددة البث هو ابتكار موشي، مما يمكّنه من معالجة تدفقات صوتية متعددة في وقت واحد، مما يتيح الفهم المتزامن لأصوات المتحدثين المتعددين.
يتمتع موشي أيضًا بوظيفة مونولوج داخلي فريدة من نوعها. قبل إنشاء الكلام، فإنه يتنبأ مسبقًا برموز النص المحاذية للوقت والمتزامنة مع الرموز الصوتية. وهذا لا يعمل على تحسين الجودة اللغوية للكلام الذي يتم إنشاؤه فحسب، بل يوفر أيضًا التعرف على الكلام المتدفق وخدمات تحويل النص إلى كلام، مما يزيد من تعزيز قدرات المحادثة.
في اختبارات الأداء المختلفة، أظهر موشي أداءً ممتازًا. سواء كان الأمر يتعلق بفهم النص، أو وضوح الكلام، أو جودة الصوت، أو الأسئلة والأجوبة المنطوقة، فقد وصل Moshi إلى المستوى الرائد بين نماذج نص الكلام الموجودة. وهذا يعني أننا نقترب خطوة واحدة من الحوار الطبيعي والسلس بين الإنسان والحاسوب.
ومع ذلك، مع تطور تكنولوجيا الذكاء الاصطناعي، أصبحت القضايا الأمنية بارزة بشكل متزايد. ومن الجدير بالذكر أن فريق تطوير Moshi أخذ ذلك بعين الاعتبار منذ البداية. يتخذون عدة إجراءات لضمان أمان النظام، بما في ذلك تجنب إنشاء محتوى ضار، وحماية خصوصية المستخدم، وضمان اتساق الصوت. يستطيع Moshi التعرف على الأسئلة غير المناسبة ورفض الإجابة عليها مع الحفاظ على تناسق صوته وعدم تقليد صوت المستخدم، مما يوفر للمستخدمين أمانًا إضافيًا.
إن ظهور موشي لا يمثل طفرة في التكنولوجيا فحسب، بل يبشر أيضًا بابتكار كبير في طريق التفاعل بين الإنسان والحاسوب. إنه يوضح لنا الإمكانيات اللانهائية لأنظمة الحوار المستقبلية ويسمح لنا برؤية الآفاق المشرقة لحوار طبيعي وسلس وإنساني بين البشر والآلات. ومع استمرار هذه التكنولوجيا في التطور والتحسن، قد نتمكن قريبًا من تحقيق اتصال خالٍ من العوائق وعالي الجودة مع الآلات، مما يسمح بعرض مشاهد أفلام الخيال العلمي في الحياة الواقعية.
عنوان النموذج: https://huggingface.co/kyutai/moshiko-pytorch-bf16
عنوان الورقة: https://kyutai.org/Moshi.pdf
يشير ظهور Moshi إلى الطريق للتفاعل المستقبلي بين الإنسان والحاسوب، كما أن تجربة المحادثة السلسة والطبيعية التي يتمتع بها مثيرة. من المعتقد أنه مع التقدم التكنولوجي المستمر، سيصبح التواصل بين البشر والآلات أكثر ملاءمة وطبيعية، مما يؤدي في النهاية إلى تحقيق تواصل خالٍ من العوائق حقًا. دعونا ننتظر ونرى!