علم محرر موقع Downcodes أن علماء من جامعة ميتا وجامعة كاليفورنيا وبيركلي وجامعة نيويورك طوروا بشكل مشترك تقنية جديدة تسمى "تحسين تفضيلات التفكير" (TPO)، بهدف تحسين أداء نماذج اللغات الكبيرة (LLMs). تعمل هذه التقنية على تحسين قدرة الذكاء الاصطناعي على "التفكير" من خلال السماح للنموذج بتوليد سلسلة من خطوات التفكير قبل الإجابة على السؤال، واستخدام نموذج التقييم لتحسين جودة الإجابة النهائية، مما يسمح له بأداء أفضل في المهام المختلفة. يختلف TPO عن تقنية "التفكير المتسلسل" التقليدية، حيث يمتلك نطاقًا أوسع من التطبيقات، ولا سيما إظهار مزايا كبيرة في الكتابة الإبداعية والتفكير المنطقي وما إلى ذلك.
في الآونة الأخيرة، تعاون علماء من ميتا، وجامعة كاليفورنيا، بيركلي، وجامعة نيويورك لتطوير تقنية جديدة تسمى تحسين تفضيلات الفكر (TPO). الهدف من هذه التقنية هو تحسين أداء نماذج اللغات الكبيرة (LLMs) عند أداء مهام مختلفة، مما يسمح للذكاء الاصطناعي بدراسة استجاباته بعناية أكبر قبل الإجابة.
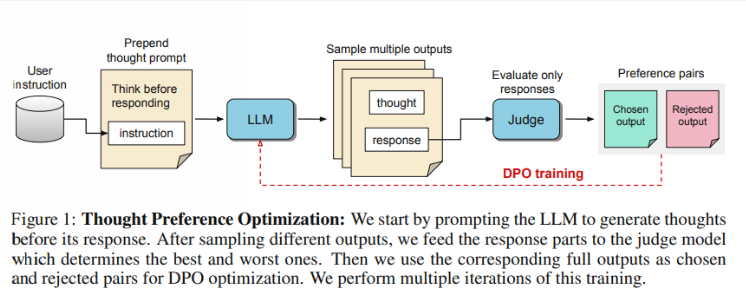
يقول الباحثون إن التفكير يجب أن يكون له فائدة واسعة النطاق. على سبيل المثال، في مهام الكتابة الإبداعية، يمكن للذكاء الاصطناعي استخدام عمليات التفكير الداخلية لتخطيط الهيكل العام وتطوير الشخصية. تختلف هذه الطريقة بشكل كبير عن تقنية "سلسلة الأفكار" (CoT) السابقة. يُستخدم الأخير بشكل أساسي في المهام الرياضية والمنطقية، بينما يمتلك TPO نطاقًا أوسع من التطبيقات. ذكر الباحثون نموذج o1 الجديد لـ OpenAI ويعتقدون أن عملية التفكير مفيدة أيضًا لمجموعة واسعة من المهام.
إذًا، كيف يعمل TPO؟ أولاً، يقوم النموذج بإنشاء سلسلة من خطوات التفكير قبل الإجابة على السؤال. بعد ذلك، يقوم بإنشاء مخرجات متعددة، والتي يتم تقييمها بعد ذلك بواسطة نموذج تقييم فقط على الإجابة النهائية، وليس على خطوات التفكير نفسها. وأخيرا، يتم تدريب النموذج من خلال تحسين التفضيل لنتائج التقييم هذه. ويأمل الباحثون أن يتم تحسين جودة الإجابات من خلال تحسين عملية التفكير، بحيث يكتسب النموذج قدرات تفكير أكثر فعالية في التعلم الضمني.
في الاختبار، كان أداء نموذج Llama38B الذي يستخدم TPO أفضل بناءً على تعليمات عامة تتبع المعيار مقارنة بالإصدار الذي لا يحتوي على استدلال صريح. في معايير AlpacaEval وArena-Hard، وصلت معدلات فوز TPO إلى 52.5% و37.3% على التوالي. والأمر الأكثر إثارة هو أن TPO تحرز أيضًا تقدمًا في المجالات التي لا تتطلب عادةً تفكيرًا واضحًا، مثل المنطق السليم والتسويق والصحة.
ومع ذلك، لاحظ فريق البحث أن الإعداد الحالي غير مناسب للمسائل الرياضية، حيث أن أداء TPO في الواقع أسوأ من النموذج الأساسي في هذه المهام. ويشير هذا إلى أنه قد تكون هناك حاجة إلى نهج مختلف للمهام المتخصصة للغاية. قد تركز الأبحاث المستقبلية على جوانب مثل التحكم في طول عمليات التفكير وتأثير التفكير على النماذج الأكبر.
تسليط الضوء على:
أطلق فريق البحث برنامج "Thinking Preference Optimization" (TPO)، الذي يهدف إلى تحسين قدرة الذكاء الاصطناعي على التفكير في تنفيذ المهام.
يستخدم TPO نماذج التقييم لتحسين جودة الإجابة من خلال السماح للنموذج بإنشاء خطوات فكرية قبل الإجابة.
أظهرت الاختبارات أن TPOs تؤدي أداءً جيدًا في مجالات مثل المعرفة العامة والتسويق، ولكنها تؤدي أداءً سيئًا في مهام الرياضيات.
بشكل عام، توفر تقنية TPO اتجاهًا جديدًا لتحسين نماذج اللغات الكبيرة، وإمكاناتها في تحسين قدرات التفكير في الذكاء الاصطناعي تستحق التطلع إليها. ومع ذلك، فإن لهذه التكنولوجيا أيضًا قيودًا، وتحتاج الأبحاث المستقبلية إلى زيادة تحسين وتوسيع نطاق تطبيقها. سيستمر محرر Downcodes في الاهتمام بأحدث التطورات في هذا المجال وتقديم المزيد من التقارير المثيرة للقراء.