أصدرت OpenAI نموذجًا جديدًا ملفتًا للنظر gpt-4o-audio-preview، والذي حقق اختراقات كبيرة في مجال توليد الكلام وتحليله، مما يوفر للمستخدمين تجربة تفاعل صوتي أكثر طبيعية وذكاءً. سيأخذك محرر Downcodes إلى فهم متعمق للوظائف الأساسية وسيناريوهات التطبيق واستراتيجيات التسعير لهذا النموذج، وتحليل تأثيره المحتمل على مختلف الصناعات.
تقود OpenAI مرة أخرى اتجاه تكنولوجيا الذكاء الاصطناعي وتطلق نموذجًا جديدًا لمعاينة الصوت gpt-4o. لا يُظهر هذا النموذج قدرات مذهلة في توليد الكلام وتحليله فحسب، بل يفتح أيضًا إمكانيات جديدة للتفاعل بين الإنسان والحاسوب. دعونا نلقي نظرة فاحصة على ميزات هذا النموذج المبتكر وتطبيقاته المحتملة.
تتضمن الوظائف الأساسية لـ gpt-4o-audio-preview ثلاثة جوانب رئيسية: أولاً، يمكنها إنشاء استجابات صوتية طبيعية وسلسة بناءً على النص، مما يوفر دعمًا قويًا لتطبيقات مثل المساعدين الصوتيين وخدمة العملاء الافتراضية. ثانيًا، يتمتع النموذج بالقدرة على تحليل المشاعر والتنغيم ودرجة الصوت للإدخال الصوتي، وهو ما له آفاق تطبيق واسعة في مجالات الحوسبة العاطفية وتحليل تجربة المستخدم. وأخيرًا، فهو يدعم التفاعل الصوتي، حيث يمكن استخدام الصوت كمدخل ومخرج، مما يضع الأساس لمجموعة كاملة من أنظمة التفاعل الصوتي.
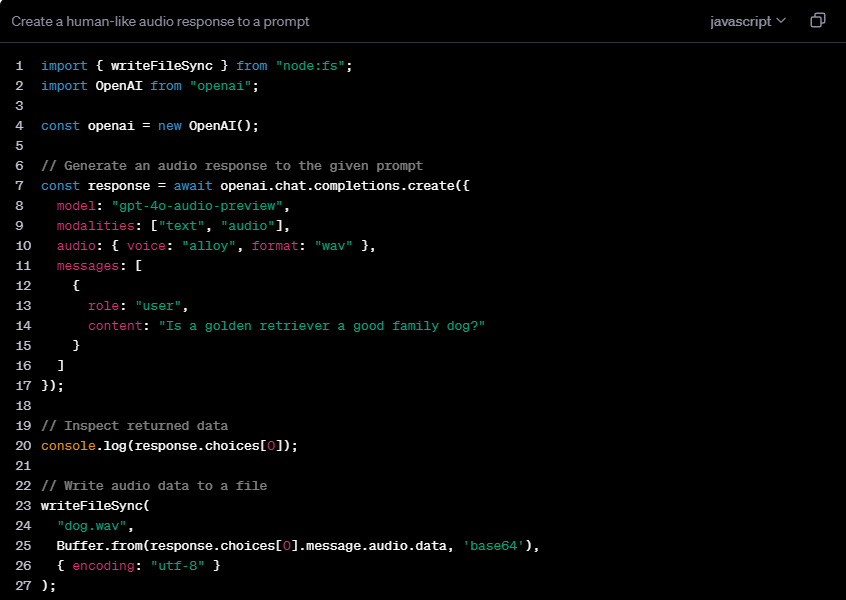
بالمقارنة مع Realtime API الموجودة في OpenAI، يركز gpt-4o-audio-preview بشكل أكبر على تفاصيل معالجة الكلام. فهو يتفوق في توليد الكلام، وتحليل المشاعر، والتفاعل مع الكلام، مع التركيز بشكل خاص على معالجة السمات الدقيقة مثل نغمة الصوت والعاطفة. في المقابل، تركز Realtime API بشكل أكبر على معالجة البيانات في الوقت الفعلي وهي مناسبة للسيناريوهات التي تتطلب تعليقات فورية، مثل تحويل الكلام إلى نص في الوقت الفعلي أو الترجمة في الوقت الفعلي وغيرها من التطبيقات التفاعلية المستمرة.
تنعكس مرونة gpt-4o-audio-preview في دعمها لمجموعات الأوضاع المتعددة. يمكن للمستخدمين تحديد إدخال النص لإنشاء إخراج النص والصوت، أو استخدام إدخال الصوت للحصول على إخراج النص والكلام. بالإضافة إلى ذلك، فهو يدعم أيضًا تحويل الصوت إلى نص وأوضاع الإدخال المختلطة، مما يوفر للمطورين خيارات غنية.
فيما يتعلق بالتسعير، تتبنى OpenAI نموذج فوترة قائم على الرمز المميز. سعر إدخال النص منخفض نسبيًا عند حوالي 5 دولارات لكل مليون رمز. يعد إخراج النص أعلى قليلاً بحوالي 15 دولارًا لكل مليون رمز. تكلفة معالجة الصوت مرتفعة نسبيًا، حيث تبلغ تكلفة الإدخال 100 دولار لكل مليون رمز (حوالي 0.06 دولار في الدقيقة)، بينما يصل إخراج الصوت إلى 200 دولار لكل مليون رمز (حوالي 0.24 دولار في الدقيقة). تعكس استراتيجية التسعير هذه التعقيد ومتطلبات موارد الحوسبة لمعالجة الصوت.
لا شك أن إطلاق gpt-4o-audio-preview سيكون له تأثير تحويلي على العديد من الصناعات. وفي مجال خدمة العملاء، يمكن أن يوفر تجربة تفاعل صوتي أكثر طبيعية وعاطفية. وفي صناعة التعليم، يمكن استخدام هذه التكنولوجيا لتطوير مساعدين أذكياء لتعلم اللغة لمساعدة الطلاب على تحسين النطق والتنغيم. وفي صناعة الترفيه، من المتوقع أن يؤدي هذا إلى مزيد من الواقعية في تركيب الكلام والتفاعل مع الشخصيات الافتراضية. بالإضافة إلى ذلك، فيما يتعلق بالتكنولوجيا المساعدة، قد يوفر gpt-4o-audio-preview خدمات أكثر دقة لتحويل الكلام إلى نص لضعاف السمع، أو توفير أوصاف صوتية أكثر ثراءً لضعاف البصر.
التفاصيل: https://platform.openai.com/docs/guides/audio/quickstart
بشكل عام، يمثل ظهور نموذج gpt-4o-audio-preview مرحلة جديدة في تكنولوجيا الذكاء الاصطناعي الصوتي. ستؤدي وظائفه القوية وآفاق تطبيقه الواسعة إلى إحداث تغييرات ثورية في أساليب التفاعل بين الإنسان والحاسوب في المستقبل. يتطلع محرر Downcodes إلى رؤية المزيد من التطبيقات المبتكرة بناءً على هذا النموذج.