تقرير محرر Downcodes: ظهر نموذج مفتوح المصدر لتوليد صور الذكاء الاصطناعي يسمى Meissonic يمكنه إنشاء صور عالية الجودة باستخدام مليار معلمة فقط، ويمكن تسميته بعملاق خفيف الوزن في مجال توليد صور الذكاء الاصطناعي! ويرجع ذلك إلى بنية المحول الفريدة وطرق التدريب الجديدة التي اعتمدها فريق البحث والتطوير (باحثون من Alibaba وSkywork AI وجامعات متعددة). لا يمكن تشغيل Meissonic على أجهزة الكمبيوتر العادية المخصصة للألعاب فحسب، بل من المتوقع أيضًا أن تقوم بتنفيذ تطبيقات محلية لتحويل النص إلى صورة على الهواتف المحمولة في المستقبل، مما سيقلل بشكل كبير من عتبة الدخول لتوليد صور الذكاء الاصطناعي.
في الآونة الأخيرة، أطلق فريق البحث العلمي بشكل مشترك نموذجًا مفتوح المصدر لتوليد صور الذكاء الاصطناعي يسمى Meissonic. والمثير للدهشة أن هذا النموذج يمكنه إنشاء صور عالية الجودة باستخدام مليار معلمة فقط. يمنح هذا التصميم المدمج شركة Meissonic القدرة على ترجمة تطبيقات تحويل النص إلى صورة على الأجهزة المحمولة.

يضم فريق البحث والتطوير الذي يقف وراء هذه التقنية باحثين من Alibaba وSkywork AI وجامعات متعددة. لقد استخدموا بنية تحويل فريدة وطرق تدريب جديدة لتمكين Meissonic من العمل على أجهزة الكمبيوتر العادية المخصصة للألعاب وربما حتى الهواتف المحمولة في المستقبل.
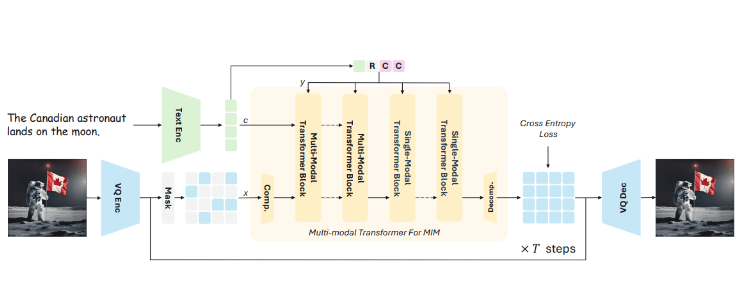
تستخدم طريقة تدريب Meissonic تقنية تسمى "نمذجة الصورة المقنعة"، والتي تعني ببساطة إخفاء جزء من الصورة أثناء عملية التدريب. يتعلم النموذج كيفية إعادة بناء الأجزاء المفقودة بناءً على المناطق المرئية والأوصاف النصية. يساعد هذا الأسلوب النموذج على فهم العلاقة بين عناصر الصورة والنص.
تسمح بنية Meissonic بتوليد صور عالية الدقة تبلغ 1024 × 1024 بكسل، سواء كانت مشاهد واقعية أو نصًا منمقًا أو رموزًا تعبيرية أو حتى ملصقات كرتونية.
على عكس نماذج الانحدار الذاتي التقليدية التي تولد الصور تدريجيًا، تتنبأ Meissonic بجميع معلومات الصورة في نفس الوقت من خلال التحسين التكراري المتوازي، مما يقلل بشكل كبير من خطوات فك التشفير، مما يقلل الوقت بنسبة 99% تقريبًا، ويحسن سرعة إنشاء الصورة بشكل كبير.
وفي عملية بناء النموذج مر الباحثون بأربع خطوات:
أولاً، استخدموا 200 مليون صورة مقاس 256 × 256 بكسل لتعليم المفاهيم الأساسية للنموذج؛ ثم استخدموا 10 ملايين زوج من الصور والنصوص التي تم فحصها بدقة لتحسين قدرات فهم النص، ومن خلال إضافة طبقة ضغط خاصة، تمكن النموذج من الإخراج وأخيرًا، قاموا بإجراء ضبط دقيق يتضمن بيانات عن التفضيلات البشرية لتحسين أداء النموذج.

ومن المثير للاهتمام، على الرغم من وجود عدد أقل من المعلمات، تفوقت Meissonic على بعض النماذج الأكبر مثل SDXL وDeepFloyd-XL في معايير متعددة، وحققت "درجة تفضيل بشري" عالية تبلغ 28.83. بالإضافة إلى ذلك، فإن Meissonic قادرة على تصحيح الصور وتوسيعها دون تدريب إضافي، مما يسمح للمستخدمين بإضافة أجزاء الصورة المفقودة بسهولة أو تحسين الصور الموجودة بشكل إبداعي.
ويعتقد فريق البحث أن هذه الطريقة قد تعزز التطوير السريع ومنخفض التكلفة لمولدات صور الذكاء الاصطناعي المخصصة، ومن المتوقع أيضًا أن تعزز تطوير تطبيقات تحويل النص إلى صورة على الأجهزة المحمولة. يمكن للأصدقاء المهتمين العثور على الإصدار التجريبي على Hugging Face وعرض كود النموذج على GitHub، والذي يمكن تشغيله بسهولة على وحدة معالجة الرسومات للمستهلك مع ذاكرة فيديو عادية تبلغ 8 جيجابايت.
العرض التوضيحي: https://huggingface.co/spaces/MeissonFlow/meissonic
المشروع: https://github.com/viiika/Meissonic
تسليط الضوء على:
Meissonic هو نموذج مفتوح المصدر للذكاء الاصطناعي يمكنه إنشاء صور عالية الجودة بمليار معلمة فقط، وهو مناسب للاستخدام على أجهزة الكمبيوتر العادية المخصصة للألعاب والأجهزة المحمولة المستقبلية.
وباستخدام أسلوب تدريب متوازي للتحسين التكراري، تستطيع Meissonic إنشاء صور أسرع بنسبة 99% من النماذج التقليدية.
على الرغم من صغر حجم المعلمة، تتفوق Meissonic على النماذج الأكبر حجمًا في اختبارات متعددة وتتيح إمكانية رسم الصور وتوسيعها بدون تدريب.
بشكل عام، جلب ظهور Meissonic إمكانيات جديدة في مجال توليد الصور بالذكاء الاصطناعي، كما أن تصميمها خفيف الوزن وأدائها الفعال يستحق التطلع إليه! يوصي محرر Downcodes بأن يذهب الجميع إلى Hugging Face وGitHub لتجربة واستكشاف نموذج الذكاء الاصطناعي القوي هذا.