علم محرر Downcodes أن أكاديمية Alibaba Damo وجامعة Renmin الصينية قامتا بالاشتراك في فتح نموذج لمعالجة المستندات يسمى mPLUG-DocOwl1.5. يمكن للنموذج فهم محتوى المستند دون التعرف على الحروف (OCR) ويؤدي أداءً جيدًا في اختبارات قياس الأداء المتعددة. ويكمن جوهره في طريقة "تعلم البنية الموحدة"، التي تعمل على تحسين الفهم الهيكلي لنموذج اللغة الكبيرة متعدد الوسائط (MLLM) للصور النصية الغنية. . أصدر النموذج تعليمات برمجية ونماذج ومجموعات بيانات علنية على GitHub، مما يوفر موارد قيمة للبحث في المجالات ذات الصلة.
قامت أكاديمية Alibaba Damo وجامعة Renmin الصينية مؤخرًا بفتح نموذج لمعالجة المستندات يسمى mPLUG-DocOwl1.5. ويركز هذا النموذج على فهم محتوى المستند دون التعرف الضوئي على الحروف، وقد حقق نتائج في العديد من الاختبارات القياسية لفهم المستندات المرئية.
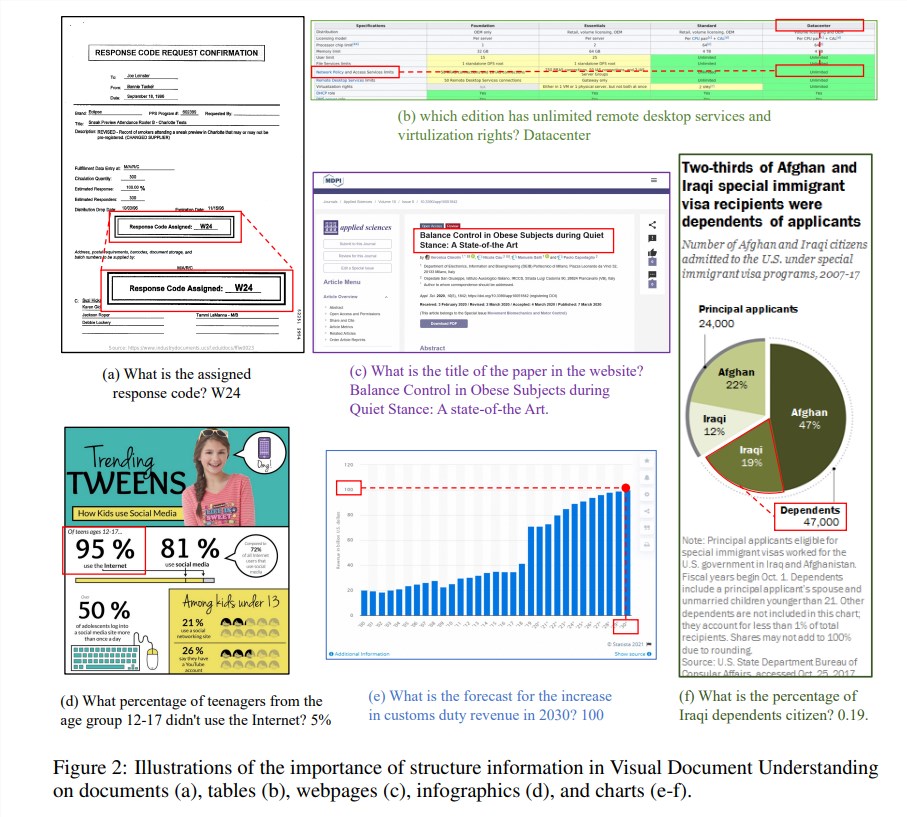
تعد المعلومات الهيكلية أمرًا بالغ الأهمية لفهم دلالات الصور الغنية بالنصوص مثل المستندات والجداول والرسوم البيانية. على الرغم من أن نماذج اللغات الكبيرة متعددة الوسائط (MLLM) الحالية تتمتع بقدرات التعرف على النص، إلا أنها تفتقر إلى القدرة على فهم البنية العامة لصور المستندات النصية الغنية. من أجل حل هذه المشكلة، يؤكد mPLUG-DocOwl1.5 على أهمية المعلومات الهيكلية في فهم المستندات المرئية، ويقترح "تعلم الهيكل الموحد" لتحسين أداء MLLM.
يغطي "التعلم الهيكلي الموحد" للنموذج 5 مجالات: المستندات وصفحات الويب والجداول والرسوم البيانية والصور الطبيعية، بما في ذلك مهام التحليل المدركة للبنية ومهام تحديد موضع النص متعدد التفاصيل. من أجل تشفير المعلومات الهيكلية بشكل أفضل، صمم الباحثون وحدة تحويل مرئية إلى نص بسيطة وفعالة H-Reducer، والتي لا تحافظ على معلومات التخطيط فحسب، بل تقلل أيضًا من طول الميزات المرئية عن طريق دمج تصحيحات الصور المتجاورة أفقيًا من خلال الالتفاف، وتمكين نماذج لغوية كبيرة لفهم الصور عالية الدقة بشكل أكثر كفاءة.
بالإضافة إلى ذلك، ولدعم التعلم الهيكلي، قام فريق البحث ببناء DocStruct4M، وهي مجموعة تدريب شاملة تحتوي على 4 ملايين عينة تعتمد على مجموعات البيانات المتاحة للجمهور، والتي تحتوي على تسلسلات نصية مدركة للبنية وأزواج مربعات محيطة بالنص متعددة التفاصيل. من أجل زيادة تحفيز القدرات الاستدلالية لـ MLLM في مجال المستندات، قاموا أيضًا ببناء مجموعة بيانات الضبط المنطقي DocReason25K التي تحتوي على 25000 عينة عالية الجودة.
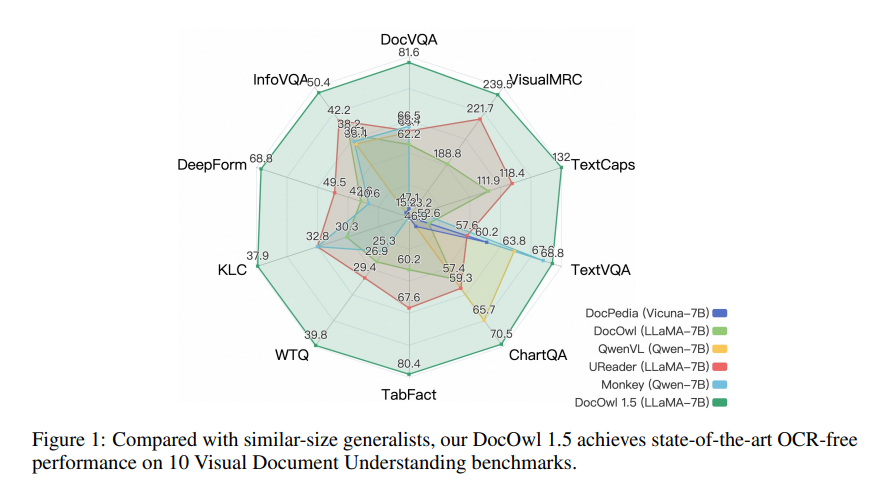
يعتمد mPLUG-DocOwl1.5 إطارًا تدريبيًا من مرحلتين، والذي يقوم أولاً بإجراء تعلم هيكلي موحد ثم يقوم بعد ذلك بإجراء الضبط الدقيق للمهام المتعددة في مهام متعددة. من خلال طريقة التدريب هذه، حقق mPLUG-DocOwl1.5 أداءً متطورًا في 10 معايير لفهم المستندات المرئية، مما أدى إلى تحسين أداء SOTA لـ 7B LLM بأكثر من 10 نقاط مئوية في 5 معايير.
حاليًا، تم إصدار التعليمات البرمجية والنموذج ومجموعة البيانات الخاصة بـ mPLUG-DocOwl1.5 للعامة على GitHub.
عنوان المشروع: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
عنوان الورقة: https://arxiv.org/pdf/2403.12895
يوفر المصدر المفتوح لـ mPLUG-DocOwl1.5 إمكانيات جديدة للبحث والتطبيق في مجال فهم المستندات المرئية، ويستحق أدائه الفعال وطرق الوصول المريحة اهتمام المطورين واستخدامهم. ومن المتوقع أن يتم استخدام هذا النموذج في سيناريوهات أكثر عملية في المستقبل.