يتم استخدام نماذج اللغات الكبيرة (LLMs) على نطاق واسع بشكل متزايد، ولكن العدد الهائل من المعلمات الخاصة بها يتطلب متطلبات هائلة من موارد الحوسبة. ومن أجل حل هذه المشكلة وتحسين كفاءة ودقة النموذج في بيئات الموارد المختلفة، يواصل الباحثون استكشاف أساليب جديدة. ستقدم هذه المقالة إطار عمل Flextron الذي تم تطويره بشكل مشترك من قبل باحثين من NVIDIA وجامعة تكساس في أوستن. تم تصميم هذا الإطار لتحقيق النشر المرن لنماذج الذكاء الاصطناعي دون ضبط إضافي وحل مشكلات عدم كفاءة الأساليب التقليدية بشكل فعال. سيشرح محرر Downcodes بالتفصيل ابتكارات إطار عمل Flextron ومزاياه في البيئات المحدودة الموارد.
في مجال الذكاء الاصطناعي، حققت نماذج اللغات الكبيرة (LLMs) مثل GPT-3 وLlama-2 تقدمًا كبيرًا ويمكنها فهم اللغة البشرية وتوليدها بدقة. ومع ذلك، فإن العدد الكبير من معلمات هذه النماذج يجعلها تتطلب قدرًا كبيرًا من موارد الحوسبة أثناء التدريب والنشر، مما يشكل تحديًا في البيئات المحدودة الموارد.
المدخل الورقي: https://arxiv.org/html/2406.10260v1
تقليديًا، من أجل تحقيق توازن بين الكفاءة والدقة في ظل قيود موارد الحوسبة المختلفة، يحتاج الباحثون إلى تدريب إصدارات مختلفة متعددة من النموذج. على سبيل المثال، تشتمل عائلة طراز Llama-2 على متغيرات مختلفة تحتوي على 7 مليارات و1.3 مليار و700 مليون معلمة. ومع ذلك، تتطلب هذه الطريقة كمية كبيرة من البيانات وموارد الحوسبة وليست فعالة للغاية.
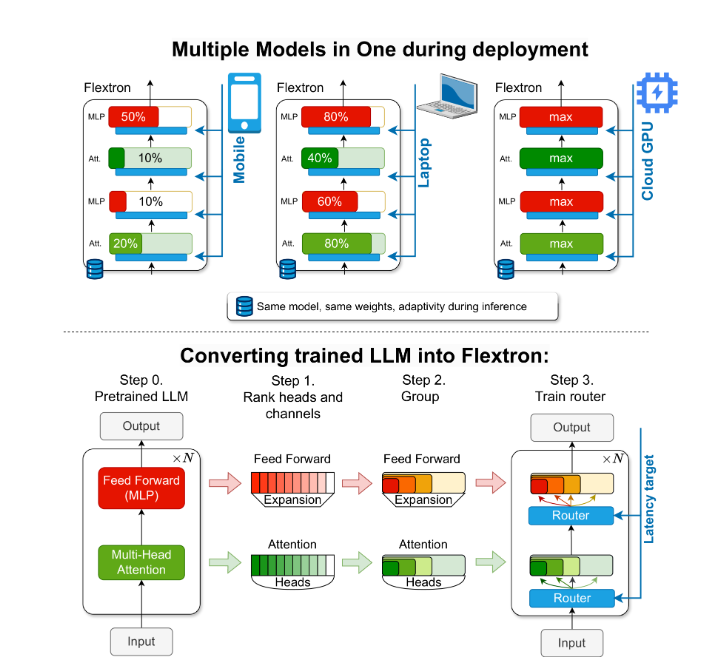
لحل هذه المشكلة، قدم باحثون من NVIDIA وجامعة تكساس في أوستن إطار عمل Flextron. Flextron عبارة عن بنية نموذجية مرنة جديدة وإطار عمل لتحسين ما بعد التدريب يدعم النشر التكيفي للنماذج دون الحاجة إلى ضبط إضافي، وبالتالي حل مشكلات عدم كفاءة الأساليب التقليدية.
تعمل شركة Flextron على تحويل LLM المدربة مسبقًا إلى نماذج مرنة من خلال أساليب التدريب الفعالة على أخذ العينات وخوارزميات التوجيه المتقدمة. تتميز هذه البنية بتصميم مرن متداخل يسمح بإجراء تعديلات ديناميكية أثناء الاستدلال لتلبية أهداف زمن الوصول والدقة المحددة. تتيح هذه القدرة على التكيف إمكانية استخدام نموذج واحد تم تدريبه مسبقًا في مجموعة متنوعة من سيناريوهات النشر، مما يقلل بشكل كبير من الحاجة إلى متغيرات نماذج متعددة.
يوضح تقييم أداء Flextron أنه يتفوق في الكفاءة والدقة مقارنة بالنماذج المدربة المتعددة والشبكات المرنة الأخرى. على سبيل المثال، يعمل Flextron جيدًا على معايير متعددة مثل ARC-easy وLAMBADA وPIQA وWinoGrande وMMLU وHellaSwag، وذلك باستخدام 7.63% فقط من علامات التدريب في التدريب المسبق الأصلي، وبالتالي توفير الكثير من موارد الحوسبة والوقت. .
يشتمل إطار عمل Flextron أيضًا على طبقات إدراكية مرنة متعددة الطبقات (MLP) وطبقات مرنة متعددة الرؤوس (MHA)، مما يزيد من قدرته على التكيف. تستخدم طبقة MHA المرنة الذاكرة المتاحة وقوة المعالجة بشكل فعال عن طريق تحديد مجموعة فرعية من رؤوس الانتباه بناءً على بيانات الإدخال، وهي مناسبة بشكل خاص للسيناريوهات ذات موارد الحوسبة المحدودة.
تسليط الضوء على:
- يدعم إطار عمل Flextron النشر المرن لنموذج الذكاء الاصطناعي دون ضبط إضافي.
من خلال التدريب الفعال على العينات وخوارزميات التوجيه المتقدمة، يتم تحسين كفاءة النموذج ودقته.
تعمل طبقة الانتباه المرنة متعددة الرؤوس على تحسين استخدام الموارد وهي مناسبة بشكل خاص للبيئات ذات موارد الحوسبة المحدودة.
يأمل هذا التقرير في تقديم أهمية وابتكار إطار عمل Flextron لطلاب المدارس الثانوية بطريقة سهلة الفهم.
بشكل عام، يوفر إطار عمل Flextron حلاً فعالاً ومبتكرًا لمشكلة نشر نماذج لغوية كبيرة في بيئات محدودة الموارد. إن هندستها المرنة وطريقة التدريب الفعالة للعينات تمنحها مزايا كبيرة في التطبيقات العملية وتوفر اتجاهًا جديدًا لمزيد من التطوير لتكنولوجيا الذكاء الاصطناعي. يأمل محرر Downcodes أن تساعد هذه المقالة الجميع على فهم الأفكار الأساسية والمساهمات الفنية لإطار عمل Flextron بشكل أفضل.