سيأخذك محرر Downcodes للتعرف على تقنية مبتكرة تعمل على تحسين كفاءة نماذج اللغات الكبيرة (LLMs) - Q-Sparse. لقد اجتذبت قدرات معالجة اللغة الطبيعية القوية التي يتمتع بها طلاب LLM الكثير من الاهتمام، لكن تكلفتها الحسابية العالية وبصمة الذاكرة كانت دائمًا بمثابة اختناقات في التطبيقات العملية. يستخدم Q-Sparse طريقة تشتت ذكية لتحسين كفاءة الاستدلال بشكل كبير مع ضمان أداء النموذج، مما يمهد الطريق لتطبيق واسع النطاق لمجالات LLM. سوف تستكشف هذه المقالة بعمق التكنولوجيا الأساسية والمزايا ونتائج التحقق التجريبية لـ Q-Sparse، مما يوضح إمكاناتها الهائلة في تحسين كفاءة LLMs.
في عالم الذكاء الاصطناعي، تُعرف نماذج اللغات الكبيرة (LLM) بقدراتها الفائقة على معالجة اللغة الطبيعية. ومع ذلك، فإن نشر هذه النماذج في التطبيقات العملية يواجه تحديات كبيرة، ويرجع ذلك أساسًا إلى تكلفتها الحسابية العالية وبصمة الذاكرة خلال مرحلة الاستدلال. ولحل هذه المشكلة، قام الباحثون باستكشاف كيفية تحسين كفاءة ماجستير إدارة الأعمال. في الآونة الأخيرة، جذبت طريقة تسمى Q-Sparse اهتمامًا واسع النطاق.
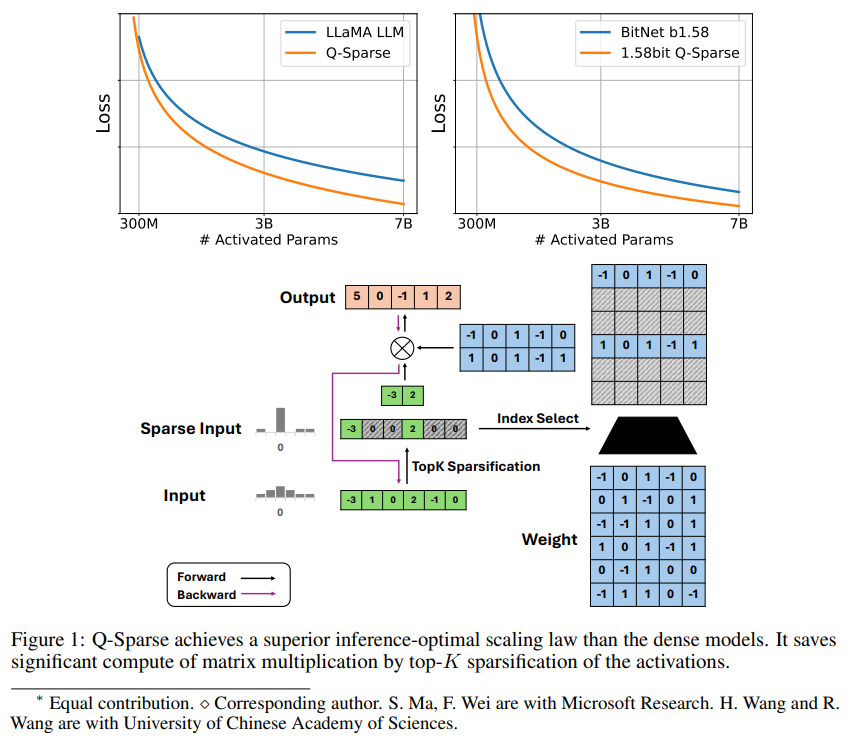
Q-Sparse هي طريقة بسيطة ولكنها فعالة تحقق التنشيط المتناثر بالكامل لـ LLMs من خلال تطبيق تناثر top-K في التنشيطات ومقدر التمريري في التدريب. وهذا يعني تحسينات كبيرة في الكفاءة عند الاستدلال. وتشمل نتائج البحوث الرئيسية ما يلي:
يحقق Q-Sparse كفاءة استدلال أعلى مع الحفاظ على نتائج قابلة للمقارنة مع LLMs الأساسية.
تم اقتراح قاعدة توسيع مثالية استنتاجية مناسبة لـ LLMs ذات التنشيط المتناثر.
يعمل Q-Sparse في بيئات مختلفة، بما في ذلك التدريب من الصفر، والتدريب المستمر لخريجي LLM الجاهزين، والضبط الدقيق.
يعمل Q-Sparse بدقة كاملة وLLMs ذات 1 بت (مثل BitNet b1.58).
مزايا التنشيط المتفرق
يعمل Spassity على تحسين كفاءة LLMs بطريقتين: أولاً، يمكن أن يقلل Spassity من مقدار حساب ضرب المصفوفة، لأنه لن يتم حساب العناصر الصفرية؛ هذا هو عنق الزجاجة الرئيسي في مرحلة الاستدلال للماجستير في القانون.
يحقق Q-Sparse تناثرًا كاملاً في عمليات التنشيط من خلال تطبيق وظيفة تناثر top-K في كل إسقاط خطي. بالنسبة للانتشار العكسي، يتم حساب تدرج التنشيط باستخدام مقدر التمريري. بالإضافة إلى ذلك، تم تقديم وظيفة ReLU المربعة لزيادة تحسين تناثر التنشيط.
التحقق التجريبي
درس الباحثون قانون التوسع في LLMs قليلة النشاط من خلال سلسلة من تجارب التوسع وتوصلوا إلى بعض النتائج المثيرة للاهتمام:
يتحسن أداء نماذج التنشيط المتفرق مع زيادة حجم النموذج ونسبة التشتت.
نظرًا لنسبة التناثر الثابتة S، فإن أداء نموذج التنشيط المتناثر يتدرج مع حجم النموذج N بطريقة قانون الطاقة.
بالنظر إلى المعلمة الثابتة N، فإن أداء نموذج التنشيط المتناثر يتدرج بشكل كبير مع نسبة التفرق S.
يمكن استخدام Q-Sparse ليس فقط للتدريب من الصفر، ولكن أيضًا للتدريب المستمر والضبط الدقيق لبرامج LLM الجاهزة. في التدريب المستمر وإعدادات الضبط الدقيق، استخدم الباحثون نفس البنية وعملية التدريب مثل التدريب من الصفر، وكان الاختلاف الوحيد هو تهيئة النموذج بأوزان مدربة مسبقًا وتمكين الوظائف المتفرقة من مواصلة التدريب.
يستكشف الباحثون استخدام Q-Sparse مع LLMs ذات 1 بت (مثل BitNet b1.58) والخبراء المختلطين (MoE) لزيادة تحسين كفاءة LLMs. بالإضافة إلى ذلك، فهم يعملون على جعل Q-Sparse متوافقًا مع الوضع الدفعي، مما سيوفر المزيد من المرونة للتدريب والاستدلال على LLMs.
يوفر ظهور تقنية Q-Sparse أفكارًا جديدة لحل مشكلة كفاءة LLMs، فهي تتمتع بإمكانات كبيرة في تقليل تكاليف الحوسبة واستخدام الذاكرة، ومن المتوقع أن تعزز تطبيق LLMs في المزيد من المجالات. من المعتقد أن المزيد من نتائج الأبحاث المستندة إلى Q-Sparse ستظهر في المستقبل لزيادة تحسين أداء وكفاءة LLMs.