علم محرر Downcodes أن Alibaba Cloud أطلقت نموذج لغة صوتية جديد واسع النطاق Qwen2-Audio، والذي حقق طفرة كبيرة في مجال التفاعل الصوتي. يمكنه قبول مجموعة متنوعة من مدخلات الإشارات الصوتية وإجراء تحليل صوتي أو الرد مباشرة على الأوامر الصوتية، مما يحسن تجربة المستخدم بشكل كبير. بالمقارنة مع طراز Qwen-Audio السابق، يُظهر Qwen2-Audio أداءً أكثر قوة في تتبع التعليمات وقد حقق مكانة رائدة في اختبارات قياس الأداء المتعددة. ويمثل هذا خطوة قوية أخرى اتخذتها Alibaba Cloud في مجال الذكاء الاصطناعي، مما يوفر تكنولوجيا تفاعل صوتي أكثر تقدمًا وملاءمة للمستخدمين.
أصدرت Alibaba Cloud مؤخرًا نموذج لغة صوتية واسع النطاق يسمى Qwen-Audio، ويمكن لهذا النموذج قبول مجموعة متنوعة من مدخلات الإشارات الصوتية ويمكنه إجراء تحليل صوتي أو الرد مباشرة على الأوامر الصوتية، مما يحسن تجربة التفاعل الصوتي بشكل كبير.
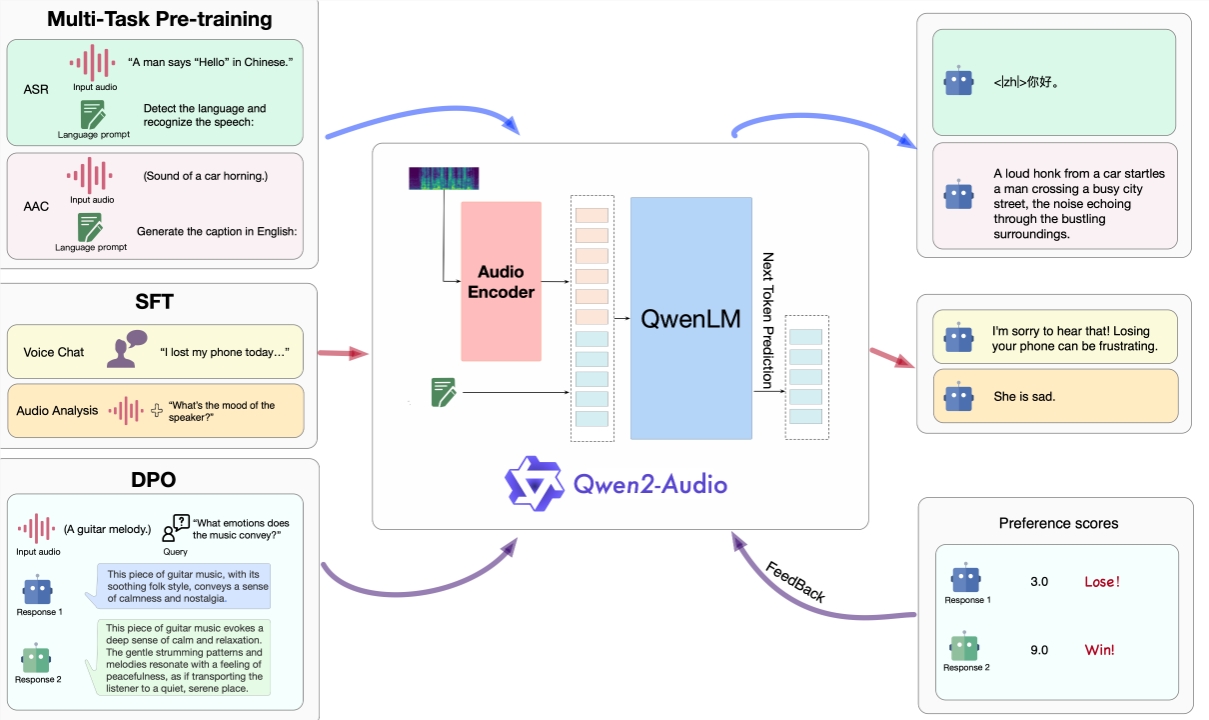
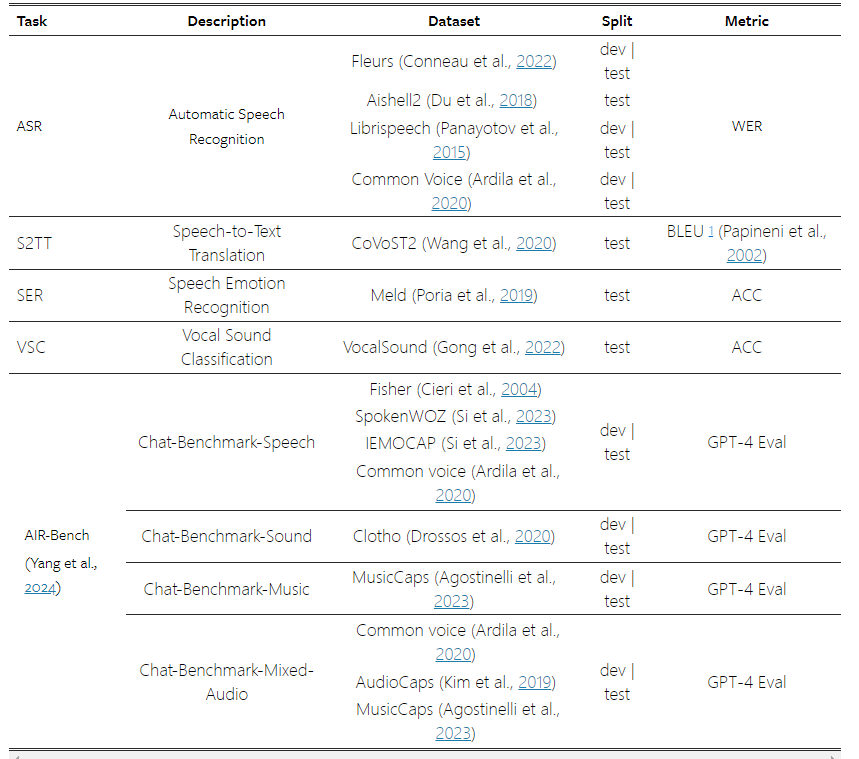
فيما يتعلق بقدرات الدردشة في Qwen2-Audio، قام الباحثون بقياس أدائها على معيار الدردشة AIR-Bench (يانغ وآخرون، 2024). أظهر Qwen2-Audio أداءً متطورًا عبر الكلام والموسيقى الصوتية والصوت المختلط وظيفة تتبع التعليمات للمجموعات الفرعية (SOTA). يُظهر تحسينات كبيرة مقارنة بـ Qwen-Audio ويتفوق بشكل كبير على LALMs الأخرى.
تسليط الضوء على:
تطلق Alibaba Cloud نموذج Qwen2-Audio، وهو نموذج لغة مبتكر واسع النطاق يعمل على تحسين تجربة التفاعل الصوتي؛
يمكن لـ Qwen2-Audio قبول مجموعة متنوعة من مدخلات الإشارة الصوتية لتحليل الصوت أو الإجابة مباشرة على الأوامر الصوتية، مما يوسع وظيفة التفاعل الصوتي بشكل كبير؛
من خلال عملية التدريب المكونة من ثلاث مراحل، تم عرض طريقة التدريب والأداء على هيكل نموذج Qwen2-Audio بشكل كامل، مما يوفر للمستخدمين تجربة تفاعل صوتي أفضل.
وبشكل عام، فإن ظهور Qwen2-Audio يجلب إمكانيات جديدة لتكنولوجيا التفاعل الصوتي، كما أن أدائها القوي وتعدد استخداماتها يجعلها تتمتع بآفاق واسعة في التطبيقات المستقبلية. سيواصل محرر Downcodes الاهتمام بأحدث التطورات التي حققتها Alibaba Cloud في مجال الذكاء الاصطناعي وتقديم المزيد من التقارير المثيرة للقراء.