في السنوات الأخيرة، تطورت النماذج الكبيرة متعددة الوسائط بسرعة، وظهرت العديد من النماذج الممتازة. ومع ذلك، تعتمد معظم النماذج الحالية على أجهزة التشفير المرئية، التي تعاني من مشاكل انحياز الحث البصري الناتجة عن فصل التدريب، مما يحد من الكفاءة والأداء. يقدم لك محرر Downcodes نموذجًا جديدًا للغة المرئية EVE أطلقه معهد Zhiyuan للأبحاث بالتعاون مع الجامعات، وهو يعتمد على بنية خالية من المبرمجين وقد حقق نتائج ممتازة في اختبارات قياس الأداء المتعددة، مما يوفر فرصًا جديدة لتطوير نماذج متعددة الوسائط. أفكار.
في الآونة الأخيرة، تم إحراز تقدم كبير في البحث وتطبيق النماذج الكبيرة متعددة الوسائط. أطلقت الشركات الأجنبية مثل OpenAI وGoogle وMicrosoft وغيرها سلسلة من النماذج المتقدمة، وحققت المؤسسات المحلية مثل Zhipu AI وStep Star اختراقات في هذا المجال. تعتمد هذه النماذج عادةً على أجهزة التشفير المرئية لاستخراج الميزات المرئية ودمجها مع نماذج لغوية كبيرة، ولكن هناك مشكلة تحيز الحث البصري الناتجة عن فصل التدريب، مما يحد من كفاءة النشر وأداء النماذج الكبيرة متعددة الوسائط.
من أجل حل هذه المشكلات، أطلق معهد Zhiyuan للأبحاث، بالتعاون مع جامعة داليان للتكنولوجيا وجامعة بكين وجامعات أخرى، جيلًا جديدًا من نموذج اللغة المرئية الخالي من المبرمج EVE. تقوم EVE بدمج التمثيل البصري اللغوي والمحاذاة والاستدلال في بنية وحدة فك التشفير النقية الموحدة من خلال استراتيجيات التدريب المحسنة والإشراف البصري الإضافي. باستخدام البيانات العامة، تحقق EVE أداءً جيدًا في العديد من المعايير اللغوية المرئية، حيث تقترب أو حتى تتفوق على الأساليب متعددة الوسائط السائدة القائمة على التشفير.
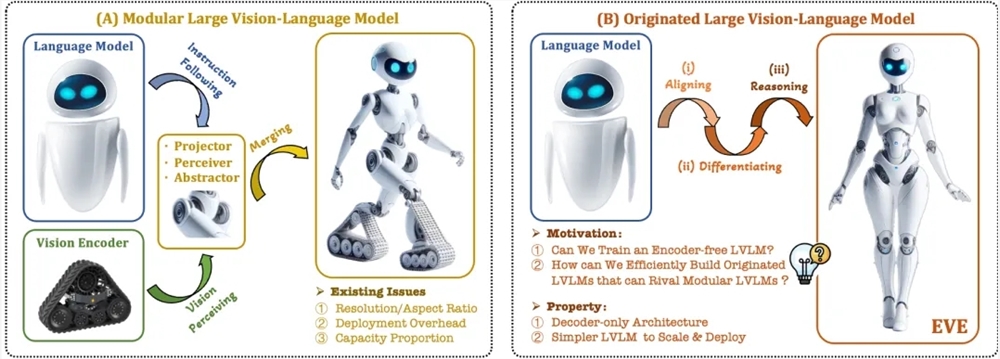
تشمل الميزات الرئيسية لـ EVE ما يلي:
نموذج اللغة المرئية الأصلية: يزيل برنامج التشفير المرئي ويتعامل مع أي نسبة عرض إلى ارتفاع للصورة، وهو أفضل بكثير من نفس النوع من طراز Fuyu-8B.
انخفاض تكاليف البيانات والتدريب: يستخدم التدريب المسبق البيانات العامة مثل OpenImages وSAM وLAION، كما أن وقت التدريب قصير.
استكشاف شفاف وفعال: يوفر مسار تطوير فعال وشفاف للبنى الأصلية متعددة الوسائط لأجهزة فك التشفير النقية.
هيكل النموذج:
طبقة تضمين التصحيح: احصل على خريطة المعالم ثنائية الأبعاد للصورة من خلال طبقة تلافيفية واحدة وطبقة تجميع متوسطة لتعزيز الميزات المحلية والمعلومات العالمية.
طبقة محاذاة التصحيح: دمج الميزات المرئية للشبكة متعددة الطبقات لتحقيق محاذاة دقيقة مع مخرجات التشفير المرئي.
استراتيجية التدريب:
مرحلة ما قبل التدريب مسترشدة بنماذج لغوية كبيرة: إنشاء الاتصال الأولي بين الرؤية واللغة.
مرحلة ما قبل التدريب التوليدي: تحسين قدرة النموذج على فهم المحتوى البصري اللغوي.
مرحلة الضبط الدقيق الخاضعة للإشراف: تنظم قدرة النموذج على اتباع تعليمات اللغة وتعلم أنماط المحادثة.
التحليل الكمي: أداء EVE جيدًا في معايير اللغة المرئية المتعددة ويمكن مقارنته بمجموعة متنوعة من نماذج اللغة المرئية السائدة القائمة على التشفير. على الرغم من التحديات في الاستجابة بدقة لتعليمات محددة، من خلال استراتيجية تدريب فعالة، تحقق EVE أداءً مشابهًا لنماذج اللغة المرئية مع قواعد التشفير.
لقد أثبتت EVE إمكانات نماذج اللغة المرئية الأصلية التي لا تحتوي على تشفير، وفي المستقبل، قد تستمر في تعزيز تطوير النماذج متعددة الوسائط من خلال المزيد من تحسينات الأداء، وتحسين البنى التي لا تحتوي على تشفير، وإنشاء نماذج أصلية متعددة الوسائط. نماذج.
عنوان الورقة: https://arxiv.org/abs/2406.11832
رمز المشروع: https://github.com/baaivision/EVE
عنوان النموذج: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
وبشكل عام، فإن ظهور نموذج EVE يوفر اتجاهات وإمكانيات جديدة لتطوير نماذج كبيرة متعددة الوسائط، وتستحق إستراتيجيته التدريبية الفعالة وأدائه الممتاز الاهتمام. ونحن نتطلع إلى أن يتمكن نموذج EVE المستقبلي من إظهار قدراته القوية في المزيد من المجالات.