في الاتصالات الصوتية في الوقت الفعلي، كان تغيير نغمة المتحدث دون التأثير على الدلالات والعروض مشكلة فنية دائمًا. سيقدم محرر Downcodes تقنية متقدمة اليوم - StreamVC، والتي يمكنها تغيير نغمة صوت المتحدث في الوقت الفعلي مع الحفاظ على محتوى الصوت والإيقاع، وهي مناسبة لمنصات الهاتف المحمول وتوفر إمكانية الاتصال في الوقت الفعلي وإخفاء الهوية الصوتية. إن زمن الاستجابة المنخفض لـ StreamVC، وتركيب الكلام عالي الجودة، واستقرار طبقة الصوت يمنحها مزايا كبيرة في مجال الاتصالات في الوقت الفعلي.
في عالم الاتصالات في الوقت الفعلي، سواء كان ذلك عبر مكالمة هاتفية أو مؤتمر عبر الفيديو، يعد الصوت أداة مهمة بالنسبة لنا للتعبير عن أنفسنا. ولكن هل فكرت يومًا فيما يمكن أن يحدث إذا تمكنا من تغيير نغمة صوت المتحدث في الوقت الفعلي دون التأثير على محتوى اللغة وإيقاعها؟ إن ظهور تقنية StreamVC يسمح لنا بالقيام بذلك.
يعد StreamVC حلاً مبتكرًا لتحويل الصوت يطابق نغمة الصوت المستهدف مع الحفاظ على محتوى ونبرة الصوت المصدر. على عكس الطرق التقليدية، ينتج StreamVC الشكل الموجي الناتج مع زمن وصول منخفض لإشارة الإدخال، حتى على الأنظمة الأساسية المحمولة، مما يجعله مناسبًا لسيناريوهات الاتصال في الوقت الفعلي مثل المكالمات الهاتفية ومؤتمرات الفيديو، بالإضافة إلى إخفاء الهوية الصوتية في هذه السيناريوهات.
أبرز النقاط الفنية:
في الوقت الفعلي: StreamVC قادر على 70.8 مللي ثانية من الاستدلال بزمن وصول منخفض على الأجهزة المحمولة.
تركيب كلام عالي الجودة: استخدم البنية واستراتيجية التدريب الخاصة ببرنامج ترميز الصوت العصبي SoundStream لتحقيق تركيب كلام خفيف الوزن وعالي الجودة.
استقرار طبقة الصوت: من خلال تقديم معلومات التردد الأساسي الأبيض (f0)، يتم تحسين اتساق طبقة الصوت دون تسريب معلومات جرس المتحدث المصدر.
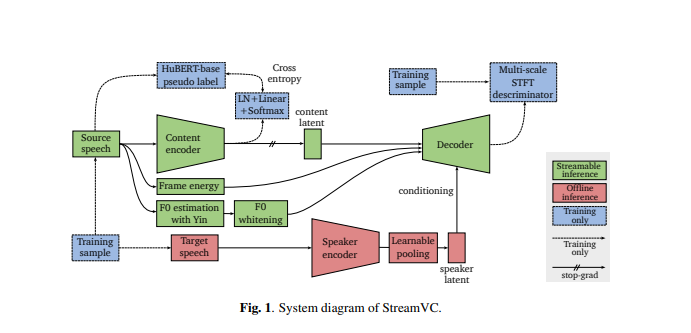
تصميم StreamVC مستوحى من Soft-VC وSoundStream. ويستخدم وحدات الكلام المنفصلة المستخرجة بواسطة نموذج HuBERT كأهداف تنبؤية لشبكة تشفير المحتوى. تم تصميم بنية تشفير المحتوى ووحدة فك التشفير واستراتيجية التدريب من برنامج ترميز الصوت العصبي SoundStream لتحقيق تركيب صوتي سببي عالي الجودة.
تمت مقارنة StreamVC بالتقنيات الحالية وفقًا لمعايير متعددة، بما في ذلك الطبيعة وسهولة الفهم وتشابه المتحدثين واتساق طبقة الصوت. تظهر النتائج التجريبية أن StreamVC يؤدي أداءً جيدًا في الحفاظ على طبقة صوت اللغة المصدر ويمكن مقارنته بالنموذج المضبوط بدقة من حيث تشابه المتحدث.
يثبت StreamVC أن تحويل الصوت بكفاءة مع زمن انتقال منخفض على الأجهزة المحمولة أمر ممكن تمامًا. يمكن تعلم وحدات الكلام الناعمة المشتقة من HuBERT من خلال بنية شبكة عصبية تلافيفية سببية قابلة للتدفق، ويعد حقن معلومات f0 البيضاء في وحدة فك التشفير أمرًا بالغ الأهمية لتوفير مخرجات عالية الجودة.
عنوان الورقة: https://arxiv.org/pdf/2401.03078
لقد أدى ظهور تقنية StreamVC إلى توفير إمكانيات جديدة للاتصالات الصوتية في الوقت الفعلي، وستعمل إمكانات التحويل الصوتي ذات زمن الوصول المنخفض وعالية الجودة على تعزيز تطبيق التكنولوجيا الصوتية في المزيد من المجالات. أعتقد أنه في المستقبل، سيلعب StreamVC دورًا أكبر في إخفاء الهوية الصوتية والمؤثرات الصوتية الخاصة وما إلى ذلك. نتطلع إلى المزيد من التطبيقات المبتكرة المعتمدة على StreamVC!