أطلق مختبر Tencent للذكاء الاصطناعي مؤخرًا نموذجًا جديدًا يسمى VTA-LDM، والذي تم تصميمه لتحويل محتوى الفيديو بكفاءة إلى صوت متسق لغويًا ومؤقتًا. تكمن التقنية الأساسية لهذا النموذج في "المحاذاة الضمنية"، التي تتطابق تمامًا مع محتوى الصوت والفيديو الذي تم إنشاؤه، مما يحسن بشكل كبير سيناريوهات الجودة والتطبيق لتوليد الصوت. سيأخذك محرر Downcodes إلى فهم متعمق للابتكارات وآفاق التطبيق لنموذج VTA-LDM.
مع التقدم الكبير في تكنولوجيا تحويل النص إلى فيديو، أصبحت كيفية إنشاء محتوى صوتي متسق دلاليًا وزمنيًا من إدخال الفيديو موضوعًا ساخنًا بين الباحثين. في الآونة الأخيرة، أطلق فريق البحث في مختبر Tencent للذكاء الاصطناعي نموذجًا جديدًا يسمى "إنشاء الفيديو المتوافق ضمنيًا مع الصوت" - VTA-LDM، والذي يهدف إلى توفير حلول فعالة لتوليد الصوت.
مدخل المشروع: https://top.aibase.com/tool/vta-ldm
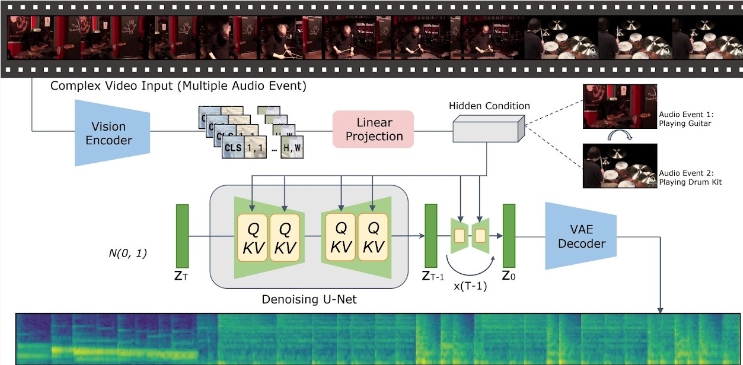
الفكرة الأساسية لنموذج VTA-LDM هي مطابقة محتوى الصوت والفيديو الذي تم إنشاؤه دلاليًا ومؤقتًا من خلال تقنية المحاذاة الضمنية. لا تعمل هذه الطريقة على تحسين جودة توليد الصوت فحسب، بل تعمل أيضًا على توسيع سيناريوهات تطبيق تقنية إنشاء الفيديو. أجرى فريق البحث استكشافًا متعمقًا لتصميم النموذج وقام بدمج مجموعة متنوعة من الوسائل التقنية لضمان دقة واتساق الصوت الناتج.
يركز البحث على ثلاثة جوانب رئيسية: التشفير المرئي، والتضمين المساعد، وتقنيات زيادة البيانات. قام فريق البحث أولاً بإنشاء نموذج أساسي وأجرى عددًا كبيرًا من تجارب الاستئصال على هذا الأساس لتقييم تأثير أجهزة التشفير المرئية المختلفة والتضمينات المساعدة على تأثير التوليد. وتظهر نتائج هذه التجارب أن النموذج يؤدي أداءً جيدًا من حيث جودة التوليد والمحاذاة المتزامنة للفيديو والصوت، ليصل إلى طليعة التكنولوجيا الحالية.
فيما يتعلق بالاستدلال، يحتاج المستخدمون فقط إلى وضع مقاطع الفيديو في دليل البيانات المحدد وتشغيل البرنامج النصي للاستدلال المقدم لإنشاء محتوى الصوت المقابل. يوفر فريق البحث أيضًا مجموعة من الأدوات لمساعدة المستخدمين على دمج الصوت الناتج مع الفيديو الأصلي، مما يزيد من راحة التطبيق.
يوفر نموذج VTA-LDM حاليًا إصدارات متعددة ومختلفة من النماذج لتلبية الاحتياجات البحثية المختلفة. تغطي هذه النماذج النماذج الأساسية ومجموعة متنوعة من النماذج المحسنة، بهدف تزويد المستخدمين بخيارات مرنة للتكيف مع مختلف التجارب وسيناريوهات التطبيق.
يمثل إطلاق نموذج VTA-LDM تقدمًا مهمًا في مجال توليد الفيديو والصوت ويأمل الباحثون في استخدام هذا النموذج لتعزيز تطوير التقنيات ذات الصلة وإنشاء إمكانيات تطبيق أكثر ثراءً.
## أبرز النقاط:
لقد أدى ظهور نموذج VTA-LDM إلى تحقيق اختراقات جديدة في مجال توليد الفيديو والصوت، وتبشر أساليب التشغيل الفعالة والمريحة والوظائف القوية باحتمال تطبيق أوسع في المستقبل. ومن المعتقد أنه مع التطور المستمر للتكنولوجيا، سيلعب نموذج VTA-LDM دورًا مهمًا في المزيد من المجالات.