محرر Downcodes يجلب أخبارًا كبيرة! تم إطلاق تقنية تسريع المحولات الثورية FlashAttention-3 رسميًا! ستحدث هذه التقنية ثورة في سرعة الاستدلال وتكلفة نماذج اللغات الكبيرة (LLMs)، مما يحقق تحسينات غير مسبوقة في الكفاءة. تمت زيادة السرعة بمقدار 1.5 إلى 2 مرة، ويحافظ التشغيل منخفض الدقة (FP8) على دقة عالية، كما تم تحسين قدرات معالجة النصوص الطويلة بشكل كبير، مما سيوفر إمكانيات جديدة لتطبيقات الذكاء الاصطناعي! دعونا نلقي نظرة فاحصة على هذه التكنولوجيا المتقدمة.
لقد تم إطلاق تقنية تسريع المحولات الجديدة FlashAttention-3. هذه ليست مجرد ترقية، بل تبشر بزيادة حادة في سرعة الاستدلال وانخفاض تكلفة نماذجنا اللغوية الكبيرة (LLMs)!
دعونا نتحدث عن FlashAttention-3 أولاً، مقارنةً بالإصدار السابق، فهو مجرد تغيير جذري:
تم تحسين استخدام وحدة معالجة الرسومات بشكل كبير: باستخدام FlashAttention-3 لتدريب وتشغيل نماذج لغوية كبيرة، تمت مضاعفة السرعة بشكل مباشر، بمعدل 1.5 إلى 2 مرة، وهذه الكفاءة مذهلة!
دقة منخفضة وأداء عالٍ: يمكن أيضًا تشغيله بأرقام منخفضة الدقة (FP8) مع الحفاظ على الدقة. ماذا يعني هذا بتكلفة أقل دون المساس بالأداء؟
تعد معالجة النصوص الطويلة أمرًا سهلاً للغاية: يعمل FlashAttention-3 على تعزيز قدرة نموذج الذكاء الاصطناعي بشكل كبير على معالجة النصوص الطويلة، وهو ما لم يكن من الممكن تصوره من قبل.
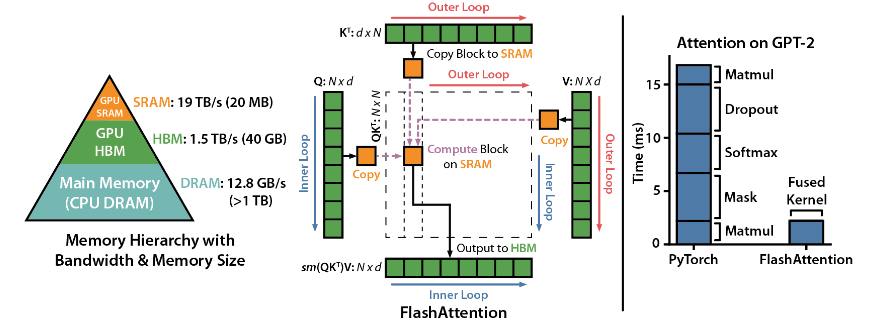
FlashAttention هي مكتبة مفتوحة المصدر تم تطويرها بواسطة Dao-AILab وهي تعتمد على ورقتين ثقيلتين وتوفر تنفيذًا محسنًا لآلية الانتباه في نماذج التعلم العميق. هذه المكتبة مناسبة بشكل خاص لمعالجة مجموعات البيانات واسعة النطاق والتسلسلات الطويلة. هناك علاقة خطية بين استهلاك الذاكرة وطول التسلسل، وهي أكثر كفاءة بكثير من العلاقة التربيعية التقليدية.
أبرز النقاط الفنية:
دعم التكنولوجيا المتقدمة: الاهتمام المحلي، والانتشار العكسي الحتمي، وALiBi، وما إلى ذلك. تعمل هذه التقنيات على رفع القوة التعبيرية والمرونة للنموذج إلى مستوى أعلى.
تحسين وحدة معالجة الرسومات Hopper: قام FlashAttention-3 بتحسين دعمه خصيصًا لوحدة معالجة الرسوميات Hopper، وتم تحسين الأداء بأكثر من نقطة ونصف.
سهل التثبيت والاستخدام: يدعم CUDA11.6 وPyTorch1.12 أو أعلى، وسهل التثبيت باستخدام أمر pip ضمن نظام Linux، على الرغم من أن مستخدمي Windows قد يحتاجون إلى المزيد من الاختبارات، إلا أنه بالتأكيد يستحق المحاولة.
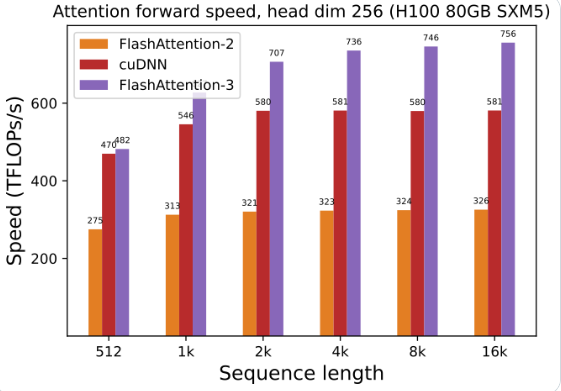
الوظائف الأساسية:
أداء فعال: تعمل الخوارزمية المحسنة على تقليل متطلبات الحوسبة والذاكرة بشكل كبير، خاصة لمعالجة البيانات ذات التسلسل الطويل، ويكون تحسين الأداء مرئيًا بالعين المجردة.
تحسين الذاكرة: مقارنة بالطرق التقليدية، يستهلك FlashAttention ذاكرة أقل، كما أن العلاقة الخطية تجعل استخدام الذاكرة لم يعد يمثل مشكلة.
الميزات المتقدمة: يؤدي دمج مجموعة متنوعة من التقنيات المتقدمة إلى تحسين أداء النموذج ونطاق التطبيق بشكل كبير.
سهولة الاستخدام والتوافق: يسمح دليل التثبيت والاستخدام البسيط، إلى جانب دعم بنيات GPU المتعددة، بدمج FlashAttention-3 بسرعة في مجموعة متنوعة من المشاريع.
عنوان المشروع: https://github.com/Dao-AILab/flash-attention
لا شك أن ظهور FlashAttention-3 سيؤدي إلى تسريع تطبيق وتطوير نماذج لغوية واسعة النطاق وتحقيق اختراقات جديدة في مجال الذكاء الاصطناعي. أداءه الفعال وسهولة استخدامه يجعله خيارًا مثاليًا للمطورين. عجلوا وتجربة ذلك!