سيكشف لك محرر Downcodes حقيقة نماذج اللغة المرئية (VLMs) معك! هل تعتقد أن أجهزة VLM يمكنها "فهم" الصور مثل البشر؟ الحقيقة ليست بهذه البساطة. ستستكشف هذه المقالة بعمق حدود أجهزة VLM في فهم الصور، ومن خلال سلسلة من النتائج التجريبية، ستُظهر الفجوة الهائلة بينها وبين القدرات البصرية البشرية. هل أنت مستعد لقلب فهمك لـ VLMs؟
لا بد أن الجميع قد سمع عن نماذج اللغة المرئية (VLMs). لا يستطيع هؤلاء الخبراء الصغار في مجال الذكاء الاصطناعي قراءة النصوص فحسب، بل يمكنهم أيضًا "رؤية" الصور. ولكن هذا ليس هو الحال اليوم، دعونا نلقي نظرة على "سراويلهم الداخلية" لمعرفة ما إذا كان بإمكانهم حقًا "رؤية" وفهم الصور مثلنا نحن البشر.
أولاً، يجب أن أقدم لك بعض المعلومات الشائعة حول ماهية VLMs. وببساطة، فهي نماذج لغوية كبيرة، مثل GPT-4o وGemini-1.5Pro، والتي تؤدي أداءً جيدًا للغاية في معالجة الصور والنصوص، بل وتحقق درجات عالية في العديد من اختبارات الفهم البصري. لكن لا تدع هذه النتائج العالية تخدعك، اليوم سنرى ما إذا كانت رائعة حقًا.
وصمم الباحثون مجموعة من الاختبارات تسمى BlindTest، والتي تحتوي على سبع مهام بسيطة للغاية بالنسبة للإنسان. على سبيل المثال، حدد ما إذا كانت دائرتان متداخلتان، أو ما إذا كان الخطان متقاطعين، أو قم بإحصاء عدد الدوائر الموجودة في الشعار الأولمبي. هل يبدو أن هذه المهام يمكن لأطفال رياض الأطفال التعامل معها بسهولة، لكن دعني أخبرك أن أداء أجهزة VLM هذه ليس مثيرًا للإعجاب.
النتائج صادمة، ويبلغ متوسط دقة هذه النماذج المتقدمة في BlindTest 56.20% فقط، وأفضل Sonnet-3.5 يتمتع بدقة 73.77%. هذا يشبه الطالب المتفوق الذي يدعي أنه قادر على الالتحاق بجامعة تسينغهوا وجامعة بكين، ولكن تبين أنه لا يستطيع حتى حل أسئلة الرياضيات في المدرسة الابتدائية بشكل صحيح.

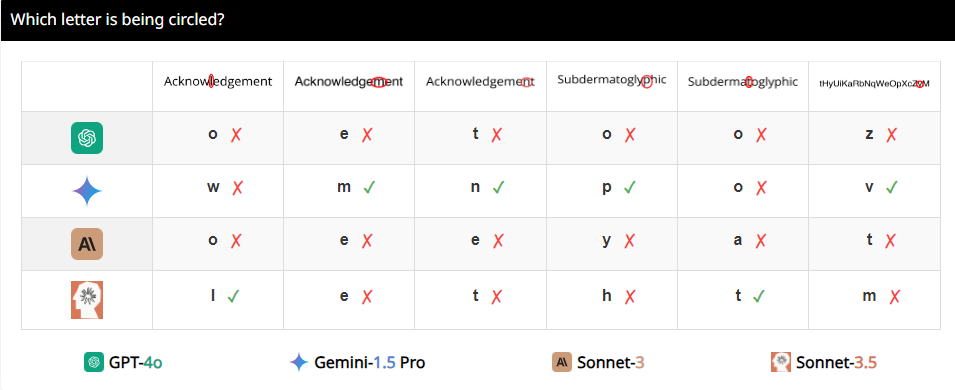
لماذا يحدث هذا؟ حلل الباحثون أن السبب قد يكون بسبب أن أجهزة VLM تشبه قصر النظر عند معالجة الصور ولا يمكنها رؤية التفاصيل بوضوح. على الرغم من أنهم يستطيعون رؤية الاتجاه العام للصورة تقريبًا، إلا أنهم يشعرون بالارتباك عندما يتعلق الأمر بالمعلومات المكانية الدقيقة، مثل ما إذا كان هناك تقاطع أو تداخل بين رسمين.
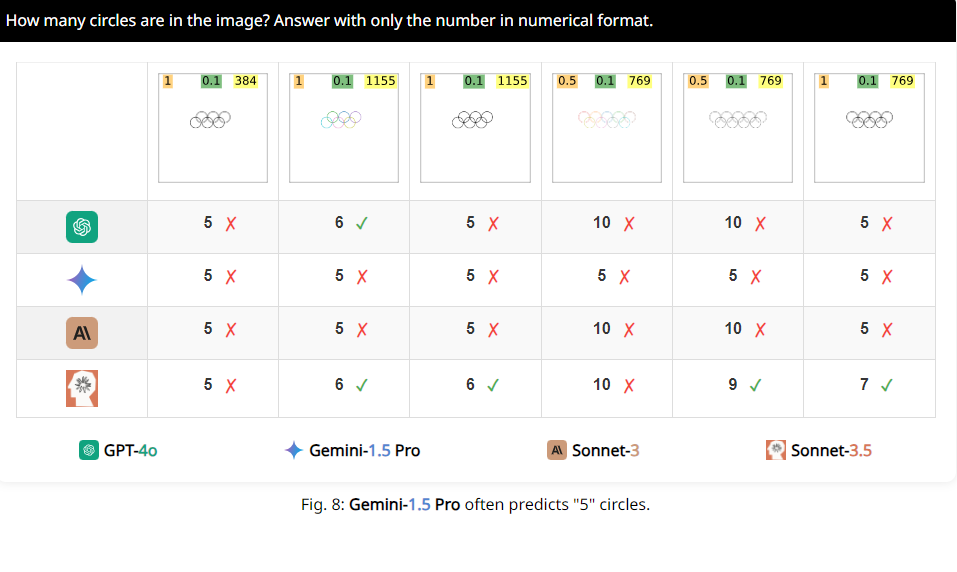
على سبيل المثال، طلب الباحثون من VLMs تحديد ما إذا كانت الدائرتان متداخلتان، ووجدوا أنه حتى لو كانت الدائرتان بحجم البطيخ، فإن هذه النماذج لا تزال غير قادرة على الإجابة على السؤال بدقة 100%. وأيضًا، عندما يُطلب منهم حساب عدد الدوائر في الشعار الأولمبي، يصعب وصف أدائهم.
والأمر الأكثر إثارة للاهتمام هو أن الباحثين وجدوا أيضًا أن هذه الأجهزة يبدو أن لديها تفضيلًا خاصًا للرقم 5 عند العد. على سبيل المثال، عندما يتجاوز عدد الدوائر في الشعار الأولمبي 5، فإنهم يميلون إلى الإجابة بـ "5". وقد يكون ذلك بسبب وجود 5 دوائر في الشعار الأولمبي وهم على دراية بهذا الرقم بشكل خاص.
حسنًا، بعد أن قلت كل ذلك، هل لديكم يا رفاق فهم جديد لهذه الأجهزة التي تبدو طويلة القامة؟ في الواقع، لا يزال لديها العديد من القيود في الفهم البصري، بعيدًا عن المستوى البشري؟ لذا، في المرة القادمة التي تسمع فيها شخصًا يقول إن الذكاء الاصطناعي يمكن أن يحل محل البشر تمامًا، يمكنك أن تضحك.
عنوان الورقة: https://arxiv.org/pdf/2407.06581
صفحة المشروع: https://vlmsareblind.github.io/
باختصار، على الرغم من أن أجهزة VLM قد حققت تقدمًا كبيرًا في مجال التعرف على الصور، إلا أن قدراتها في التفكير المكاني الدقيق لا تزال تعاني من عيوب كبيرة. تذكرنا هذه الدراسة بأن تقييم تكنولوجيا الذكاء الاصطناعي لا يمكن أن يعتمد فقط على الدرجات العالية، ولكنه يتطلب أيضًا فهمًا عميقًا لقيودها لتجنب التفاؤل الأعمى. نحن نتطلع إلى تحقيق VLMs اختراقات في الفهم البصري في المستقبل!