علم محرر Downcodes أن العلماء الصينيين من معهد جورجيا للتكنولوجيا وNVIDIA اقترحوا إطار عمل مبتكر للضبط الدقيق يسمى RankRAG، والذي يبسط بشكل كبير العملية المعقدة لتوليد تعزيز الاسترجاع (RAG). يقوم برنامج RankRAG بضبط نموذج لغة واحد كبير (LLM) للقيام في نفس الوقت بمهام الاسترجاع والتصنيف والتوليد، وبالتالي تحسين الأداء والكفاءة بشكل كبير وتحقيق نتائج تجريبية تتفوق على النماذج مفتوحة المصدر الحالية. توفر هذه التكنولوجيا المتقدمة إمكانيات جديدة لتطبيق الذكاء الاصطناعي في مختلف المجالات.
في الآونة الأخيرة، اقترح عالمان صينيان من معهد جورجيا للتكنولوجيا وNVIDIA إطار عمل جديد للضبط الدقيق يسمى RankRAG. يعمل هذا الإطار على تبسيط خط أنابيب RAG المعقد الأصلي إلى حد كبير ويستخدم طريقة الضبط الدقيق للسماح لنفس برنامج LLM باستكمال الاسترجاع والتصنيف والتوليد. المهام، مما أدى أيضًا إلى تحسن كبير في الأداء.

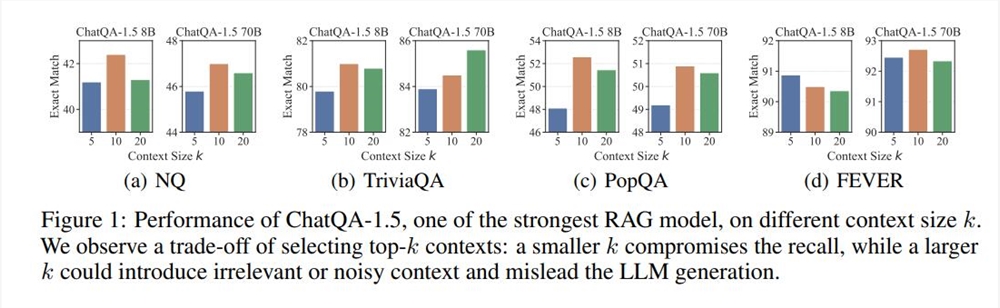
RAG (جيل الاسترجاع المعزز) هي تقنية شائعة الاستخدام في نشر LLM، وهي مناسبة بشكل خاص لمهام إنشاء النص التي تتطلب قدرًا كبيرًا من المعرفة الواقعية. بشكل عام، عملية RAG هي: نموذج كثيف يعتمد على ترميز النص يسترد مقاطع نصية من نوع Top-K من قاعدة بيانات خارجية، ثم يقوم LLM بقراءتها وإنشاءها. وقد تم استخدام هذه العملية على نطاق واسع، ولكن لها أيضًا قيود، مثل اختيار قيمة k. إذا كانت قيمة k كبيرة جدًا، فحتى LLM الذي يدعم السياق الطويل سيواجه صعوبة في معالجتها بسرعة إذا كانت قيمة k صغيرة جدًا، فستكون هناك حاجة إلى آلية استرجاع عالية الاستدعاء، والمستردون الحاليون ونماذج التصنيف لديهم عيوبهم الخاصة.
بناءً على المشكلات المذكورة أعلاه، يطرح إطار عمل RankRAG فكرة جديدة: توسيع قدرات LLM من خلال الضبط الدقيق والسماح لـ LLM بإكمال عملية الاسترجاع والتصنيف بنفسها. تظهر النتائج التجريبية أن هذه الطريقة لا تعمل على تحسين كفاءة البيانات فحسب، بل تعمل أيضًا على تحسين أداء النموذج بشكل كبير. خاصة فيما يتعلق بالمعايير العامة المتعددة ومعايير المعرفة الطبية الحيوية المكثفة، تجاوز نموذج Llama38B/70B الذي تم ضبطه بواسطة RankRAG نموذجي ChatQA-1.58B وChatQA-1.570B على التوالي.
المفتاح إلى RankRAG هو درجة التفاعل العالية وقابلية التحرير. لا يمكن للمستخدمين عرض المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي في الوقت الفعلي فحسب، بل يمكنهم أيضًا التعديل والتكرار مباشرة على الواجهة. تعمل آلية ردود الفعل الفورية هذه على تحسين كفاءة العمل بشكل كبير وتجعل الذكاء الاصطناعي مساعدًا قويًا حقًا في العملية الإبداعية. والأكثر إثارة هو أن هذا التحديث يجعل هذه القطع الأثرية لم تعد مقتصرة على منصة Claude، ويمكن للمستخدمين مشاركتها بسهولة في أي مكان.
يتضمن هذا الابتكار في إطار الضبط الدقيق RankRAG أيضًا مرحلتين من الضبط الدقيق للتعليمات. المرحلة الأولى هي الضبط الدقيق تحت الإشراف (SFT)، والذي يمزج مجموعات بيانات متعددة لتحسين القدرة على متابعة تعليمات LLM. تحتوي مجموعة بيانات الضبط الدقيق للمرحلة الثانية على مجموعة متنوعة من بيانات ضمان الجودة، وبيانات ضمان الجودة المعززة بالاسترجاع، وبيانات التصنيف السياقية لزيادة تعزيز قدرات الاسترجاع والتصنيف في LLM.
في التجارب، يتفوق RankRAG باستمرار على نموذج SOTA مفتوح المصدر الحالي ChatQA-1.5 في تسع مجموعات بيانات عامة. خاصة في مهام ضمان الجودة الصعبة، مثل ضمان الجودة طويل الذيل وضمان الجودة متعدد القفزات، يعمل RankRAG على تحسين الأداء بنسبة تزيد عن 10% مقارنة بـ ChatQA-1.5.
بشكل عام، لا يؤدي RankRAG أداءً جيدًا في مهام الاسترجاع والتوليد فحسب، بل يُظهر أيضًا قدرته القوية على التكيف مع معيار RAG الطبي الحيوي Mirage. حتى بدون الضبط الدقيق، يتفوق RankRAG في الأداء على العديد من النماذج مفتوحة المصدر في المجالات المتخصصة في مهام الإجابة على الأسئلة الطبية.
مع تقديم إطار عمل RankRAG والتحسين المستمر له، لدينا سبب للاعتقاد بأن مستقبل الإبداع التعاوني بين الذكاء الاصطناعي والبشر سيكون أكثر إشراقًا. يمكن لكل من المطورين والباحثين المستقلين استخدام هذا الإطار المبتكر لإلهام المزيد من الأفكار والإمكانيات وتعزيز تطوير التكنولوجيا والتطبيقات.
عنوان الورقة: https://arxiv.org/abs/2407.02485
يبشر ظهور إطار عمل RankRAG بقفزة أخرى للأمام لنماذج اللغة واسعة النطاق في مجالات استرجاع المعلومات وإنشاء النص. ولا شك أن تصميمها الفعال والبسيط والأداء الممتاز سيوفر اتجاهات ودوافع جديدة لتطوير تكنولوجيا الذكاء الاصطناعي في المستقبل. نحن نتطلع إلى إظهار RankRAG لإمكاناتها القوية في المزيد من المجالات!