في السنوات الأخيرة، ظهرت الابتكارات في نماذج اللغات الكبيرة (LLM) الواحدة تلو الأخرى، مما يشكل تحديًا مستمرًا لحدود البنى القائمة. علم محرر Downcodes أن الباحثين من جامعة ستانفورد، وجامعة كاليفورنيا في سان دييغو، وجامعة كاليفورنيا في بيركلي، وجامعة ميتا اقترحوا بشكل مشترك بنية جديدة تسمى TTT (طبقات وقت الاختبار والتدريب)، ومن المتوقع أن تغير فهمنا للغة تمامًا يتم التعرف على النموذج وتطبيقه. من خلال الجمع بين مزايا RNN وTransformer بذكاء، تعمل بنية TTT على تحسين القدرة التعبيرية للنموذج بشكل كبير مع ضمان التعقيد الخطي، كما أنها تؤدي أداءً جيدًا بشكل خاص عند معالجة النصوص الطويلة، مما يوفر رؤى جديدة في مجالات مثل إمكانية نمذجة الفيديو الطويل.
في عالم الذكاء الاصطناعي، يأتي التغيير دائمًا بشكل غير متوقع. في الآونة الأخيرة، ظهرت بنية جديدة تسمى TTT تم اقتراحها بشكل مشترك من قبل باحثين من جامعة ستانفورد، وجامعة كاليفورنيا في سان دييغو، وجامعة كاليفورنيا في بيركلي، وجامعة ميتا، وقد دمرت ترانسفورمر ومامبا بين عشية وضحاها وأحدثت تغييرات ثورية في نماذج اللغة.
TTT، الاسم الكامل لطبقات وقت الاختبار والتدريب، عبارة عن بنية جديدة تمامًا تعمل على ضغط السياق من خلال النسب المتدرج وتحل محل آلية الانتباه التقليدية مباشرةً. لا يعمل هذا النهج على تحسين الكفاءة فحسب، بل يفتح أيضًا بنية التعقيد الخطي ذات الذاكرة التعبيرية، مما يسمح لنا بتدريب LLMs التي تحتوي على ملايين أو حتى مليارات الرموز المميزة في السياق.

يعتمد اقتراح طبقة TTT على رؤى عميقة حول بنيات RNN وTransformer الحالية. على الرغم من أن RNN عالي الكفاءة، إلا أنه محدود بقدرته التعبيرية؛ بينما يتمتع Transformer بقدرة تعبيرية قوية، لكن تكلفته الحسابية تزيد خطيًا مع طول السياق. تجمع طبقة TTT بذكاء بين مزايا كليهما، مع الحفاظ على التعقيد الخطي وتعزيز القدرات التعبيرية.
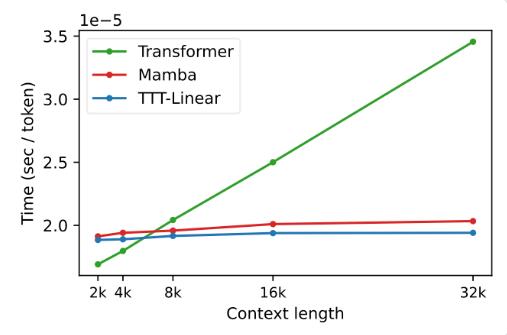
في التجارب، أظهر كلا الخيارين، TTT-Linear وTTT-MLP، أداءً ممتازًا، متفوقًا على Transformer وMamba في كل من السياقات القصيرة والطويلة. خاصة في سيناريوهات السياق الطويل، تكون مزايا طبقة TTT أكثر وضوحًا، مما يوفر إمكانات هائلة لسيناريوهات التطبيق مثل نمذجة الفيديو الطويل.
إن اقتراح طبقة TTT ليس مبتكرًا من الناحية النظرية فحسب، بل يُظهر أيضًا إمكانات كبيرة في التطبيقات العملية. في المستقبل، من المتوقع أن يتم تطبيق طبقة TTT على نمذجة الفيديو الطويل لتوفير معلومات أكثر ثراءً من خلال إطارات أخذ العينات الكثيفة، وهذا يمثل عبئًا على المحول، ولكنه نعمة لطبقة TTT.
هذا البحث هو نتيجة خمس سنوات من العمل الشاق الذي قام به الفريق، وهو قيد الإعداد منذ فترة ما بعد الدكتوراه للدكتور يو سون. لقد استمروا في الاستكشاف والمحاولة، وحققوا أخيرًا هذه النتيجة الرائعة. إن نجاح طبقة TTT هو نتيجة لجهود الفريق المتواصلة وروح الابتكار.
جلب ظهور طبقة TTT حيوية وإمكانيات جديدة إلى مجال الذكاء الاصطناعي. فهو لا يغير فهمنا لنماذج اللغة فحسب، بل يفتح أيضًا طريقًا جديدًا لتطبيقات الذكاء الاصطناعي المستقبلية. دعونا نتطلع إلى التطبيق والتطوير المستقبلي لطبقة TTT ونشهد التقدم والاختراقات في تكنولوجيا الذكاء الاصطناعي.
عنوان الورقة: https://arxiv.org/abs/2407.04620
لا شك أن ظهور بنية TTT قد ضخ دفعة قوية في مجال الذكاء الاصطناعي، ويشير التقدم المذهل في معالجة النصوص الطويلة إلى أن تطبيقات الذكاء الاصطناعي المستقبلية ستتمتع بقدرات معالجة أكثر قوة وآفاق تطبيقية أوسع. دعونا ننتظر ونرى كيف ستغير بنية TTT عالمنا بشكل أكبر.