يقدم لك محرر Downcodes أخبارًا كبيرة! أطلقت شركة Cerebras Systems أسرع خدمة استدلال للذكاء الاصطناعي في العالم - Cerebras Inference، والتي غيرت قواعد اللعبة تمامًا في مجال استدلال الذكاء الاصطناعي بسرعتها المذهلة وسعرها التنافسي للغاية. إنه يؤدي أداءً جيدًا في معالجة نماذج الذكاء الاصطناعي المختلفة، وخاصة نماذج اللغات الكبيرة (LLMs)، وهو أسرع 20 مرة من أنظمة GPU التقليدية بسعر منخفض يصل إلى عُشر أو حتى جزء من مائة. كيف سيؤثر ذلك على التطوير المستقبلي لتطبيقات الذكاء الاصطناعي؟ دعونا نلقي نظرة فاحصة.
قدمت شركة Cerebras Systems، الشركة الرائدة في مجال حوسبة أداء الذكاء الاصطناعي، حلاً رائدًا سيحدث ثورة في استدلال الذكاء الاصطناعي. وفي 27 أغسطس 2024، أعلنت الشركة عن إطلاق خدمة Cerebras Inference، وهي أسرع خدمة استدلال للذكاء الاصطناعي في العالم. تتفوق مؤشرات أداء Cerebras Inference على الأنظمة التقليدية المعتمدة على وحدة معالجة الرسومات، حيث توفر 20 ضعف السرعة بتكلفة منخفضة للغاية، مما يضع معيارًا جديدًا لحوسبة الذكاء الاصطناعي.
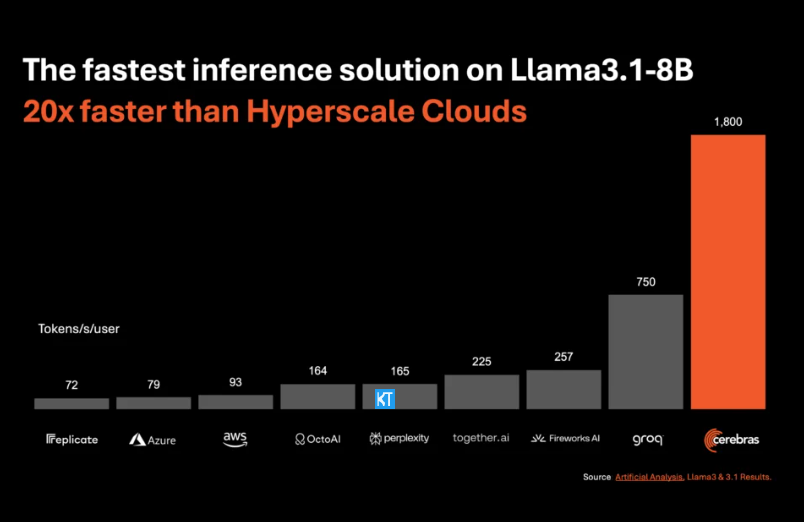
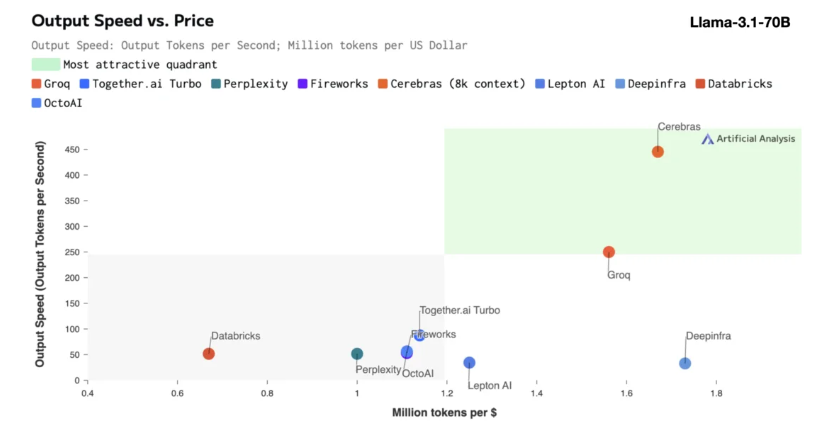
يعد استنتاج Cerebras مناسبًا بشكل خاص لمعالجة أنواع مختلفة من نماذج الذكاء الاصطناعي، وخاصة "نماذج اللغات الكبيرة" سريعة التطور (LLMs). بأخذ أحدث طراز Llama3.1 كمثال، يمكن لإصدار 8B معالجة 1800 رمز في الثانية، بينما يمكن للإصدار 70B معالجة 450 رمزًا. لا يعد هذا أسرع 20 مرة من حلول NVIDIA GPU فحسب، بل إنه أيضًا بسعر أكثر تنافسية. يبدأ سعر Cerebras Inference بـ 10 سنتات فقط لكل مليون رمز، والإصدار 70B هو 60 سنتًا. بالمقارنة مع منتجات GPU الحالية، تم تحسين نسبة السعر/الأداء بمقدار 100 مرة.
ومن المثير للإعجاب أن Cerebras Inference يحقق هذه السرعة مع الحفاظ على الدقة الرائدة في الصناعة. على عكس حلول السرعة الأولى الأخرى، تقوم Cerebras دائمًا بإجراء الاستدلال في مجال 16 بت، مما يضمن أن تحسينات الأداء لا تأتي على حساب جودة مخرجات نموذج الذكاء الاصطناعي. وقال ميشا هيل سميث، الرئيس التنفيذي لشركة Artificial Analytics، إن Cerebras حققت سرعة تزيد عن 1800 رمز إخراج في الثانية على نموذج Llama3.1 من Meta، مسجلاً رقمًا قياسيًا جديدًا.
يعد استدلال الذكاء الاصطناعي هو القطاع الأسرع نموًا في حوسبة الذكاء الاصطناعي، حيث يمثل حوالي 40% من سوق أجهزة الذكاء الاصطناعي بالكامل. إن استنتاج الذكاء الاصطناعي عالي السرعة، مثل ذلك الذي توفره شركة سيريبراس، يشبه ظهور الإنترنت عريض النطاق، مما يفتح فرصًا جديدة ويبشر بعصر جديد لتطبيقات الذكاء الاصطناعي. يمكن للمطورين استخدام Cerebras Inference لإنشاء تطبيقات الذكاء الاصطناعي من الجيل التالي التي تتطلب أداءً معقدًا في الوقت الفعلي، مثل الوكلاء الأذكياء والأنظمة الذكية.
يقدم Cerebras Inference ثلاثة مستويات خدمة بأسعار معقولة: الطبقة المجانية، وطبقة المطورين، وطبقة المؤسسة. توفر الطبقة المجانية إمكانية الوصول إلى واجهة برمجة التطبيقات (API) مع حدود استخدام سخية، مما يجعلها مثالية لمجموعة واسعة من المستخدمين. توفر طبقة المطورين خيارات نشر مرنة بدون خادم، بينما توفر طبقة المؤسسة خدمات مخصصة ودعمًا للمؤسسات ذات أعباء العمل المستمرة.
فيما يتعلق بالتكنولوجيا الأساسية، تستخدم Cerebras Inference نظام CerebrasCS-3، مدفوعًا بمحرك Wafer Scale Engine3 (WSE-3) الرائد في الصناعة. معالج الذكاء الاصطناعي هذا لا مثيل له من حيث الحجم والسرعة، ويوفر عرض نطاق ترددي للذاكرة أكبر بـ 7000 مرة من NVIDIA H100.
لا تقود شركة Cerebras Systems الاتجاه في مجال حوسبة الذكاء الاصطناعي فحسب، بل تلعب أيضًا دورًا مهمًا في العديد من الصناعات مثل الطب والطاقة والحكومة والحوسبة العلمية والخدمات المالية. من خلال التقدم المستمر للابتكار التكنولوجي، تساعد Cerebras المؤسسات في مختلف المجالات على مواجهة تحديات الذكاء الاصطناعي المعقدة.
تسليط الضوء على:
تمت زيادة سرعة خدمة Cerebras Systems بمقدار 20 مرة، وأصبح سعرها أكثر تنافسية، ويفتح حقبة جديدة من استدلال الذكاء الاصطناعي.
يدعم العديد من نماذج الذكاء الاصطناعي، وخاصةً الأداء الجيد في نماذج اللغات الكبيرة (LLMs).
يتم توفير ثلاثة مستويات من الخدمة لتسهيل الاختيار بمرونة بين المطورين ومستخدمي المؤسسات.
بشكل عام، يمثل ظهور Cerebras Inference علامة فارقة مهمة في مجال استدلال الذكاء الاصطناعي، وسيعمل أدائها واقتصادها الممتازان على تعزيز النشر الواسع النطاق والتطوير المبتكر لتطبيقات الذكاء الاصطناعي، وهو يستحق اهتمام وترقب الصناعة! سيستمر محرر Downcodes في تقديم المزيد من المعلومات التقنية المتطورة لك.