في مجال الذكاء الاصطناعي، كانت تقنية التعرف على الكلام دائمًا موضوعًا بحثيًا ساخنًا. اليوم، حقق محرك Seed-ASR الذي أطلقته ByteDance اختراقات جديدة في تقنية التعرف على الكلام بأدائه القوي ومجموعة واسعة من دعم اللغة. سوف يشرح محرر Downcodes تميز Seed-ASR بالتفصيل.
لطالما كانت تقنية التعرف على الكلام أحد المجالات الرئيسية في تطوير الذكاء الاصطناعي. الآن، يعمل محرك Seed-ASR الذي أطلقته ByteDance على كسر حواجز اللغة واللهجة بشكل كامل وضخ حيوية جديدة في هذه التكنولوجيا.
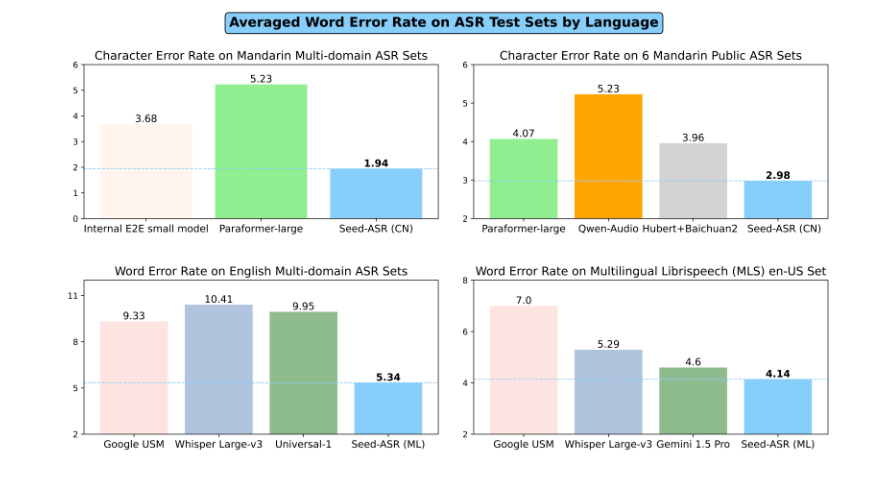
تم تدريب Seed-ASR على أكثر من 20 مليون ساعة من بيانات الكلام وما يقرب من 900000 ساعة من البيانات المقترنة، مما يدل على قدرات التعرف الممتازة. لا يمكنه التعرف بدقة على لغة الماندرين فحسب، بل يمكنه أيضًا نسخ 13 لهجة صينية و7 لغات أجنبية بدقة، بما في ذلك اللغة الإنجليزية بلهجات مختلفة. وهذا بلا شك يجلب إمكانيات جديدة للتواصل بين اللغات.
الميزة الرئيسية لـ Seed-ASR هي الوعي الممتاز بالسياق. يمكنه الجمع بين سجلات المحادثات التاريخية ومحاضر الاجتماعات والمعلومات الأخرى لتحديد أسماء الأشخاص وأسماء الأماكن والكلمات الرئيسية بشكل أكثر دقة. وهذا يجعلها تؤدي أداءً جيدًا بشكل خاص في سيناريوهات محددة، مما يؤدي إلى تحسين دقة التعرف بشكل كبير.
سواء كانت محادثة يومية بسيطة أو اتصالات جماعية معقدة، يمكن لـ Seed-ASR التعامل معها بسهولة. يمكنه نسخ المحتوى بدقة حتى في حالة وجود عدة أشخاص يتحدثون أو وجود ضوضاء في الخلفية. يمكنه أيضًا التكيف مع مختلف الصفات والبيئات الصوتية عند معالجة الفيديو والصوت المباشر.
يمكن لـ Seed-ASR أيضًا التعرف على المصطلحات في مجموعة متنوعة من المجالات المهنية، بما في ذلك الطب والتكنولوجيا والسيارات وحتى الموسيقى. وهذا يجعلها تتألق في سيناريوهات المساعد الذكي والبحث الصوتي، مما يحسن تجربة المستخدم بشكل كبير.
عنوان المشروع: https://bytedancespeech.github.io/seedasr_tech_report/
يمثل ظهور Seed-ASR ارتفاعًا جديدًا في تقنية التعرف على الكلام، وهي تستحق التطلع إلى وظائفها القوية وآفاق تطبيقها الواسعة. يعتقد محرر Downcodes أن Seed-ASR سيلعب دورًا متزايد الأهمية في تطوير الذكاء الاصطناعي في المستقبل.