اليوم، مع التطور السريع لتكنولوجيا الذكاء الاصطناعي، جذبت نماذج اللغات الصغيرة (SLM) الكثير من الاهتمام بسبب قدرتها على العمل على أجهزة محدودة الموارد. أصدر فريق Nvidia مؤخرًا Llama-3.1-Minitron4B، وهو نموذج لغة صغير ممتاز يعتمد على ضغط نموذج Llama 3. فهو يستخدم تقنيات تقليم والتقطير النموذجية لمنافسة النماذج الأكبر حجمًا في الأداء، مع الحصول على مزايا التدريب والنشر الفعالة، مما يوفر إمكانيات جديدة لتطبيقات الذكاء الاصطناعي. سيأخذك محرر Downcodes إلى فهم متعمق لهذا التقدم التكنولوجي.
في عصر تسعى فيه شركات التكنولوجيا إلى مطاردة الذكاء الاصطناعي على الأجهزة، تظهر المزيد والمزيد من نماذج اللغات الصغيرة (SLM) والتي يمكن تشغيلها على أجهزة محدودة الموارد. مؤخرًا، استخدم فريق بحث Nvidia أحدث تقنيات التقليم والتقطير لإطلاق Llama-3.1-Minitron4B، وهو نسخة مضغوطة من نموذج Llama3. هذا النموذج الجديد لا يمكن مقارنته في الأداء بالنماذج الأكبر حجمًا فحسب، بل يتنافس أيضًا مع نماذج أصغر من نفس الحجم، مع كونه أكثر كفاءة في التدريب والنشر.
يعد التقليم والتقطير من التقنيات الأساسية لإنشاء نماذج لغوية أصغر حجمًا وأكثر كفاءة. يشير التقليم إلى إزالة أجزاء غير مهمة من النموذج، بما في ذلك "تشذيب العمق" - إزالة الطبقات بأكملها، و"تشذيب العرض" - إزالة عناصر محددة مثل الخلايا العصبية ورؤوس الانتباه. ومن ناحية أخرى، ينقل نموذج التقطير المعرفة والقدرات من نموذج كبير (أي "نموذج المعلم") إلى "نموذج الطالب" الأصغر والأبسط.
هناك طريقتان رئيسيتان للتقطير، الأولى من خلال "تدريب SGD"، والتي تسمح لنموذج الطالب بتعلم مدخلات واستجابة نموذج المعلم، والثانية هي "التقطير المعرفي الكلاسيكي"، بالإضافة إلى نتائج التعلم. كما يحتاج نموذج الطالب إلى تفعيل داخلي لنموذج المعلم المتعلم.
في دراسة سابقة، نجح باحثو Nvidia في تقليل نموذج Nemotron15B إلى نموذج مكون من 800 مليون معلمة من خلال التقليم والتقطير، وفي النهاية خفضوه إلى 400 مليون معلمة. لا تعمل هذه العملية على تحسين الأداء بنسبة 16% وفقًا لمعيار MMLU الشهير فحسب، بل تتطلب أيضًا بيانات تدريب أقل 40 مرة من التدريب من الصفر.
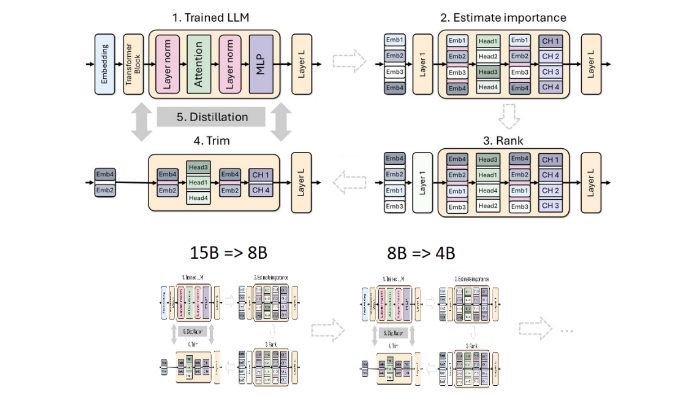
هذه المرة، استخدم فريق Nvidia نفس الطريقة لإنشاء نموذج مكون من 400 مليون معلمة استنادًا إلى نموذج Llama3.18B. أولاً، قاموا بضبط نموذج 8B غير المنقّح على مجموعة بيانات تحتوي على 94 مليار رمز للتعامل مع اختلافات التوزيع بين بيانات التدريب ومجموعة البيانات المقطرة. بعد ذلك، تم استخدام طريقتين للتقليم العميق والتقليم العرضي، وأخيرًا تم الحصول على نسختين مختلفتين من Llama-3.1-Minitron4B.
قام الباحثون بضبط النموذج المقطوع من خلال NeMo-Aligner وقاموا بتقييم قدراته في متابعة التعليمات، ولعب الأدوار، وتوليد زيادة الاسترجاع (RAG)، واستدعاء الوظائف.
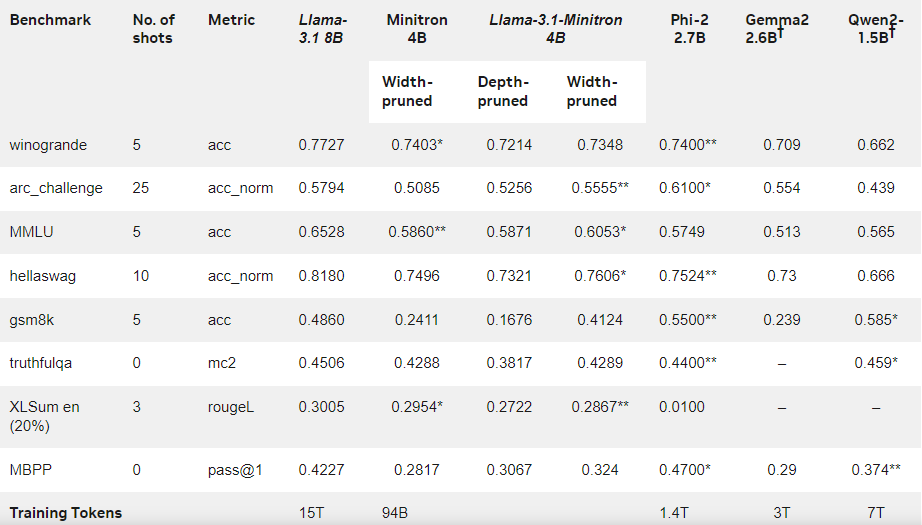
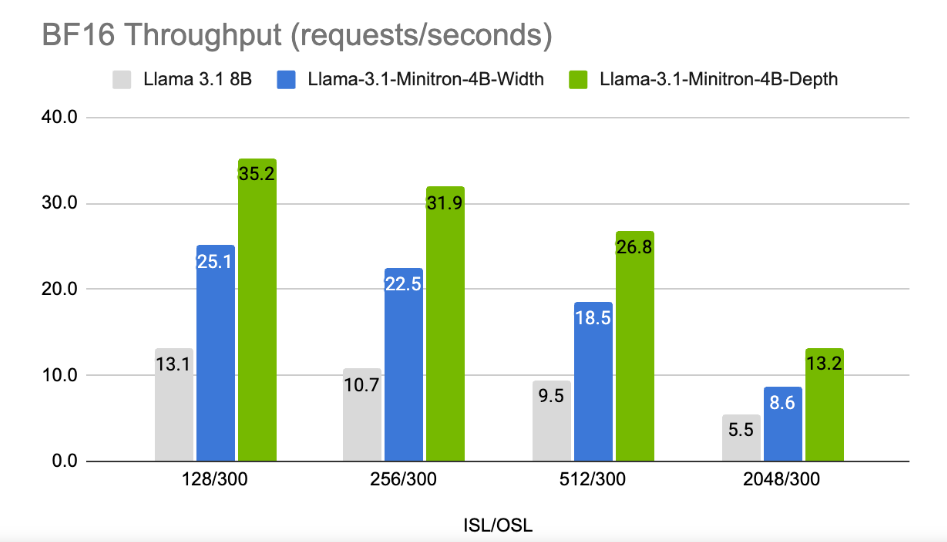
وتظهر النتائج أنه على الرغم من الكمية الصغيرة من بيانات التدريب، فإن أداء Llama-3.1-Minitron4B لا يزال قريبًا من النماذج الصغيرة الأخرى ويقدم أداءً جيدًا. تم إصدار النسخة المقطوعة من النموذج على Hugging Face، مما يسمح بالاستخدام التجاري لمساعدة المزيد من المستخدمين والمطورين على الاستفادة من كفاءته وأدائه الممتاز.
المدونة الرسمية: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
تسليط الضوء على:
Llama-3.1-Minitron4B هو نموذج لغة صغير أطلقته شركة Nvidia يعتمد على تقنية التقليم والتقطير، مع إمكانات تدريب ونشر فعالة.
تم تقليل كمية العلامات المستخدمة في عملية التدريب لهذا النموذج بمقدار 40 مرة مقارنة بالتدريب من الصفر، ولكن تم تحسين الأداء بشكل ملحوظ.
تم إصدار نسخة تقليم العرض على Hugging Face لتسهيل الاستخدام التجاري والتطوير على المستخدمين.
بشكل عام، يمثل ظهور Llama-3.1-Minitron4B علامة فارقة جديدة في تطوير نماذج اللغات الصغيرة. وسيجلب أدائها الفعال وطريقة نشرها المريحة أخبارًا جيدة لمزيد من المطورين والمستخدمين وتسريع نشر تكنولوجيا الذكاء الاصطناعي وتطبيقها. يتطلع محرر Downcodes إلى المزيد من الابتكارات المماثلة في المستقبل.