في تدريب نموذج اللغة الكبيرة (LLM)، تعد آلية نقطة التفتيش أمرًا بالغ الأهمية، حيث يمكنها بشكل فعال تجنب الخسائر الفادحة الناجمة عن انقطاع التدريب. ومع ذلك، غالبًا ما تواجه أنظمة نقاط التفتيش التقليدية اختناقات الإدخال/الإخراج وتكون غير فعالة. ولتحقيق هذه الغاية، اقترح علماء من ByteDance وجامعة هونغ كونغ نظامًا جديدًا لنقاط التفتيش يسمى ByteCheckpoint، والذي يمكنه تحسين كفاءة التدريب على LLM بشكل كبير.
في عالم رقمي تهيمن عليه البيانات والخوارزميات، لا يمكن فصل كل خطوة من خطوات نمو الذكاء الاصطناعي عن عنصر أساسي - نقطة التفتيش. تخيل أنه عندما تقوم بتدريب نموذج لغوي واسع النطاق يمكنه فهم عقول الناس والإجابة على الأسئلة بطلاقة، فإن هذا النموذج ذكي للغاية، ولكنه أيضًا مستهلك كبير ويتطلب موارد حاسوبية ضخمة لتغذيته. أثناء عملية التدريب، إذا حدث انقطاع مفاجئ للتيار الكهربائي أو فشل في الأجهزة، فستكون الخسارة فادحة. في هذا الوقت، تشبه نقطة التفتيش آلة الزمن، مما يسمح لكل شيء بالعودة إلى الحالة الآمنة السابقة ومواصلة المهام غير المكتملة.
ومع ذلك، فإن آلة الزمن نفسها تتطلب أيضًا تصميمًا دقيقًا. قدم لنا علماء من ByteDance وجامعة هونغ كونغ نظامًا جديدًا لنقاط التفتيش -ByteCheckpoint في الورقة البحثية "ByteCheckpoint: نظام نقاط تفتيش موحد لتطوير LLM". إنها ليست مجرد أداة نسخ احتياطي بسيطة، ولكنها أيضًا قطعة أثرية يمكنها تحسين كفاءة التدريب لنماذج اللغات الكبيرة بشكل كبير.
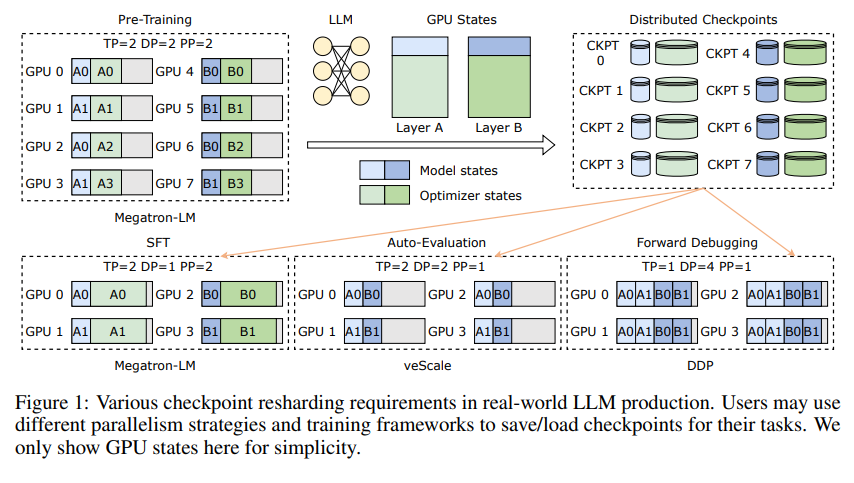
أولاً، نحتاج إلى فهم التحديات التي تواجهها النماذج اللغوية الكبيرة (LLMs). السبب وراء ضخامة هذه النماذج هو أنها تحتاج إلى معالجة وتذكر كميات هائلة من المعلومات، مما يؤدي إلى مشاكل مثل ارتفاع تكاليف التدريب، والاستهلاك الكبير للموارد، وضعف تحمل الأخطاء. بمجرد حدوث عطل، قد يتسبب ذلك في جعل فترة التدريب الطويلة غير مرضية.
يشبه نظام نقاط التفتيش لقطة للنموذج، حيث يقوم بحفظ الحالة بانتظام أثناء عملية التدريب، بحيث يمكن استعادتها بسرعة إلى الحالة الأحدث حتى لو حدث خطأ ما وتقليل الخسائر. ومع ذلك، غالبًا ما تعاني أنظمة نقاط التفتيش الحالية من عدم الكفاءة بسبب اختناقات الإدخال/الإخراج (الإدخال/الإخراج) عند معالجة النماذج الكبيرة.
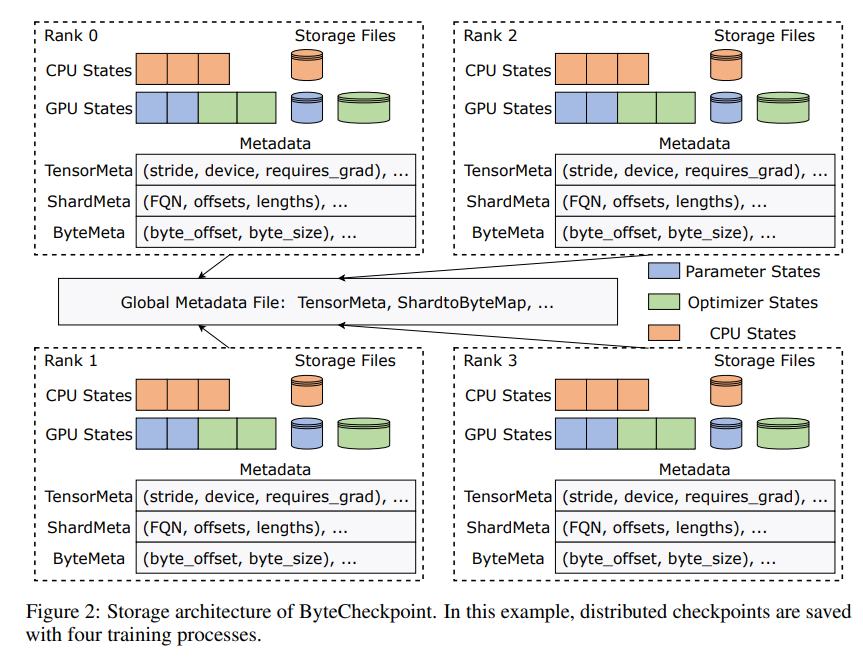
يكمن ابتكار ByteCheckpoint في اعتماد بنية تخزين جديدة تفصل البيانات والبيانات الوصفية وتتعامل بشكل أكثر مرونة مع نقاط التفتيش ضمن تكوينات متوازية مختلفة وأطر تدريب. والأفضل من ذلك، أنه يدعم إعادة تقسيم نقاط التفتيش تلقائيًا عبر الإنترنت، والتي يمكنها ضبط نقاط التفتيش ديناميكيًا للتكيف مع بيئات الأجهزة المختلفة دون مقاطعة التدريب.
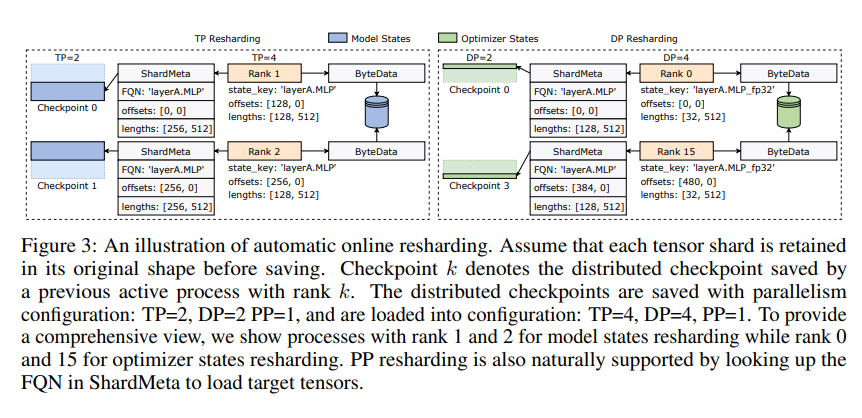
تقدم ByteCheckpoint أيضًا تقنية رئيسية - دمج الموتر غير المتزامن. يمكن أن يتعامل هذا بكفاءة مع الموترات الموزعة بشكل غير متساو على وحدات معالجة الرسومات المختلفة، مما يضمن عدم تأثر سلامة النموذج واتساقه عند إعادة فحص نقاط التفتيش.
من أجل تحسين سرعة حفظ نقاط التفتيش وتحميلها، تدمج ByteCheckpoint أيضًا سلسلة من مقاييس تحسين أداء الإدخال/الإخراج، مثل خط أنابيب الحفظ/التحميل المتطور، وتجمع ذاكرة Ping-Pong، والحفظ المتوازن لأعباء العمل والتحميل بدون تكرار، وما إلى ذلك. مما يقلل بشكل كبير من وقت الانتظار أثناء عملية التدريب.
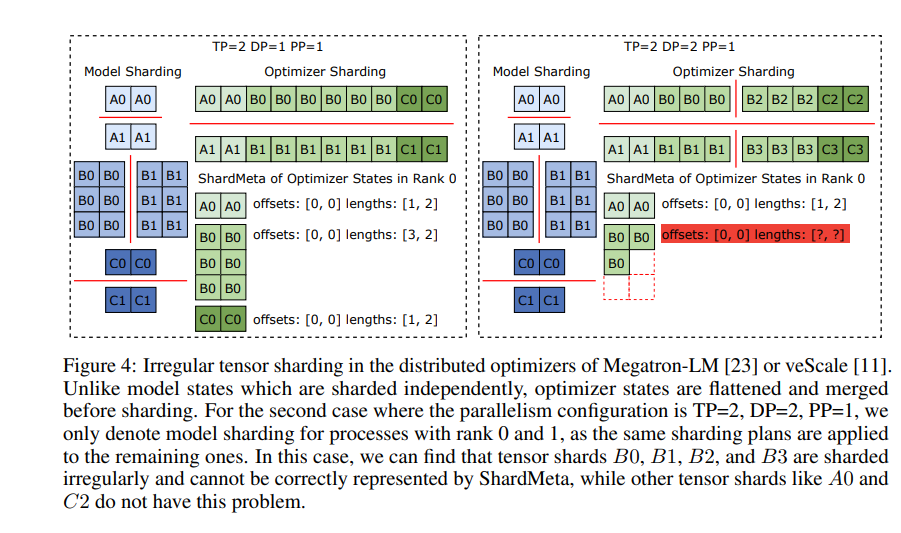
من خلال التحقق التجريبي، مقارنة بالطرق التقليدية، تتم زيادة سرعات حفظ وتحميل نقاط التفتيش الخاصة بـ ByteCheckpoint بعشرات أو حتى مئات المرات على التوالي، مما يؤدي إلى تحسين كفاءة التدريب لنماذج اللغات الكبيرة بشكل كبير.
ByteCheckpoint ليس مجرد نظام نقاط تفتيش، ولكنه أيضًا مساعد قوي في عملية تدريب نماذج اللغات الكبيرة، وهو المفتاح لتدريب الذكاء الاصطناعي الأكثر كفاءة واستقرارًا.
عنوان الورقة: https://arxiv.org/pdf/2407.20143
يلخص محرر Downcodes ما يلي: يؤدي ظهور ByteCheckpoint إلى حل مشكلة انخفاض كفاءة نقاط التفتيش في تدريب LLM ويوفر دعمًا فنيًا قويًا لتطوير الذكاء الاصطناعي. الأمر يستحق الاهتمام به!