لقد اجتذب مشروع Llama3 الأخير من Meta AI اهتمامًا واسع النطاق، وسيمنحك محرر Downcodes فهمًا متعمقًا لتقنيته الأساسية واتجاه التطوير المستقبلي. تمت مقابلة باحث Meta AI توماس سكيلوم مؤخرًا، حيث شارك تفاصيل تطوير Llama3 وقدم رؤى فريدة حول المشكلات الموجودة في التدريب على نماذج اللغة واسعة النطاق. وشدد بشكل خاص على الدور الهام للبيانات الاصطناعية في تدريب Llama3 وكيفية استخدام التعليقات البشرية بشكل فعال لتحسين أداء النموذج. ستشرح هذه المقالة بالتفصيل أساليب التدريب ومجالات التطبيق وخطط التطوير المستقبلية لـ Llama3، مما يقدم للقراء منظورًا شاملاً ومتعمقًا.
شارك توماس سكيلوم، الباحث في Meta AI، مؤخرًا بعض الأفكار حول مشروعهم الأخير، Llama3، في مقابلة. ويشير بصراحة إلى أن الكميات الكبيرة من النصوص الموجودة على الويب متفاوتة الجودة، ويعتقد أن التدريب على هذه البيانات هو مضيعة للموارد. ولذلك، فإن عملية تدريب Llama3 لا تعتمد على أي إجابات مكتوبة من قبل الإنسان، ولكنها تعتمد بالكامل على البيانات الاصطناعية التي تم إنشاؤها بواسطة Llama2.
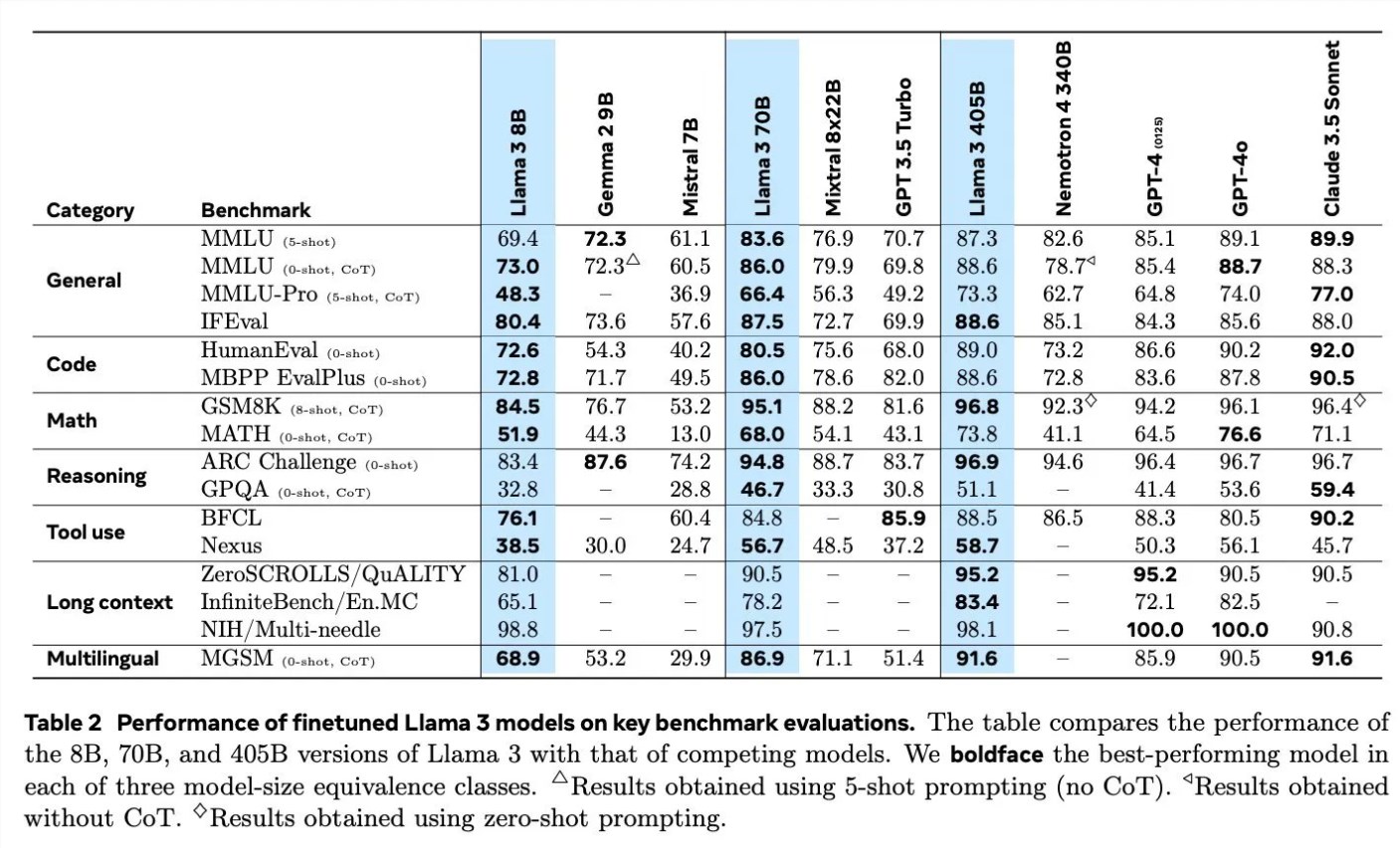
عند مناقشة تفاصيل تدريب Llama3، قام Scialom بتفصيل تطبيق البيانات الاصطناعية في مجالات مختلفة. على سبيل المثال، فيما يتعلق بإنشاء التعليمات البرمجية، استخدموا ثلاث طرق مختلفة لإنشاء بيانات تركيبية، بما في ذلك ردود الفعل من تنفيذ التعليمات البرمجية، وترجمة لغات البرمجة، والترجمة الخلفية للوثائق. وفيما يتعلق بالاستدلال الرياضي، فقد اعتمدوا على نهج البحث "دعونا خطوة بخطوة" لتوليد البيانات. بالإضافة إلى ذلك، يستمر تدريب Llama3 مسبقًا بنسبة 90% من الرموز المميزة متعددة اللغات لجمع التعليقات التوضيحية البشرية عالية الجودة، وهو أمر مهم بشكل خاص في المعالجة متعددة اللغات.
تعد معالجة النصوص الطويلة أيضًا محور اهتمام Llama3، وهي تعتمد على البيانات الاصطناعية للتعامل مع الإجابة على الأسئلة النصية الطويلة وتلخيص المستندات الطويلة والاستدلال الأساسي للتعليمات البرمجية. فيما يتعلق باستخدام الأداة، تم تدريب Llama3 على بحث Brave ومترجمي Wolfram Alpha وPython لتنفيذ استدعاءات دالة فردية ومتداخلة ومتوازية ومتعددة الجولات.
ذكر Scialom أيضًا أهمية التعلم المعزز بالتغذية الراجعة البشرية (RLHF) في تدريب Llama3. لقد استخدموا بيانات التفضيل البشري على نطاق واسع لتدريب النموذج، مع التركيز على قدرة البشر على الاختيار (مثل اختيار أي من القصيدتين يفضلون) بدلاً من البدء من الصفر.
بدأت Meta تدريب Llama4 في يونيو، وكشف Scialom أن التركيز الرئيسي لـ Llama4 سيكون حول العميل الذكي. بالإضافة إلى ذلك، ذكر أيضًا نسخة متعددة الوسائط من Llama، والتي ستحتوي على المزيد من المعلمات ومن المقرر إصدارها في المستقبل القريب.
تكشف مقابلة Scialom عن أحدث التقدم الذي حققته Meta AI واتجاهات التطوير المستقبلية في مجال الذكاء الاصطناعي، خاصة في كيفية استخدام البيانات الاصطناعية وردود الفعل البشرية لتحسين أداء النموذج.
من خلال مقابلة Scialom، تعرفنا على ابتكارات Llama3 في استخدام البيانات والتدريب على النماذج، بالإضافة إلى استكشاف Meta AI المستمر في مجال نماذج اللغة واسعة النطاق. توفر تجربة Llama3 الناجحة مرجعًا قيمًا لتطوير نماذج الذكاء الاصطناعي المستقبلية، وتشير أيضًا إلى أن تكنولوجيا الذكاء الاصطناعي ستتطور في اتجاه أكثر دقة وكفاءة. يتطلع محرر Downcodes إلى إصدار Llama4 وLlama متعدد الوسائط، ويواصل الاهتمام بالتقدم المذهل الذي حققته Meta AI في مجال الذكاء الاصطناعي.