الإصدار الكبير لشركة Meta! مفتوح المصدر، أحدث نموذج لغوي كبير Llama 3.1 405B، مع حجم معلمات يصل إلى 128 مليار، وأدائه مشابه لـ GPT-4 في مهام متعددة. بعد عام من الإعداد الدقيق، بدءًا من تخطيط المشروع وحتى المراجعة النهائية، وصلت نماذج سلسلة Llama 3 إلى الجمهور أخيرًا. لا يشمل هذا المصدر المفتوح النموذج نفسه فحسب، بل يشمل أيضًا المعالجة المحسنة لبيانات ما قبل التدريب، وضمان جودة بيانات ما بعد التدريب، وتقنية القياس الكمي الفعالة لتقليل متطلبات الحوسبة وتسهيل استخدامها على المطورين. سيشرح محرر Downcodes بالتفصيل التحسينات والميزات المميزة لـ Llama 3.1 405B.
أعلنت Meta الليلة الماضية عن المصدر المفتوح لأحدث نموذج لغوي كبير لها Llama3.1 405B. تشير هذه الأخبار الكبيرة إلى أنه بعد عام من الإعداد الدقيق، بدءًا من تخطيط المشروع وحتى المراجعة النهائية، وصلت نماذج سلسلة Llama3 إلى الجمهور أخيرًا.
Llama3.1405B هو نموذج استخدام أداة متعدد اللغات يحتوي على 128 مليار معلمة. بعد التدريب المسبق بطول سياق يبلغ 8 كيلو بايت، يتم تدريب النموذج بشكل أكبر بطول سياق يبلغ 128 كيلو بايت. وفقًا لـ Meta، فإن أداء هذا النموذج في مهام متعددة يمكن مقارنته بـ GPT-4 الرائد في الصناعة.
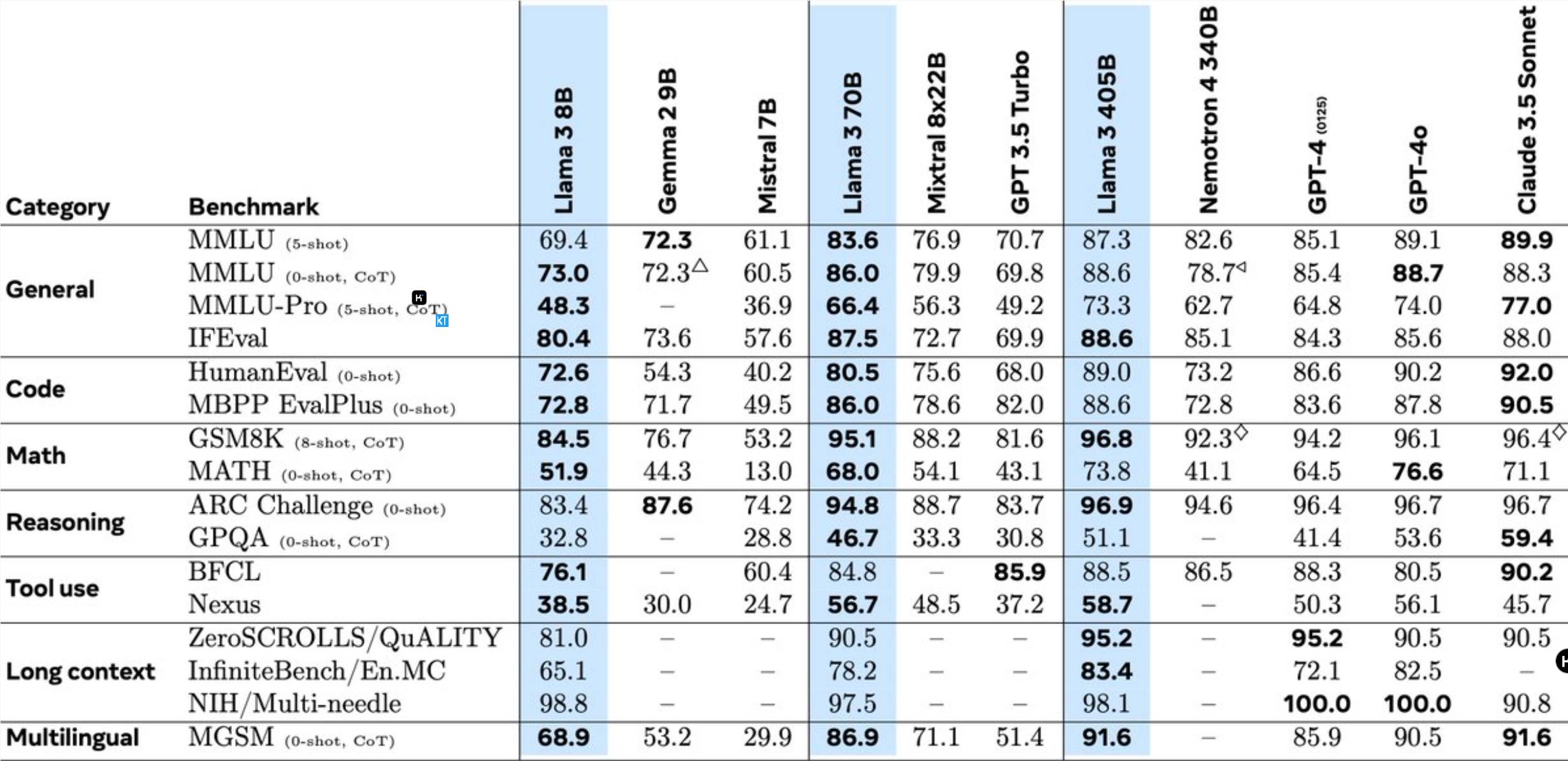
بالمقارنة مع نموذج اللاما السابق، تم تحسين Meta في العديد من الجوانب:
يمثل التدريب المسبق لنموذج 405B تحديًا كبيرًا، حيث يتضمن 15.6 تريليون رمز و3.8×10^25 عملية نقطة عائمة. ولتحقيق هذه الغاية، قامت Meta بتحسين بنية التدريب بأكملها واستخدمت أكثر من 16000 وحدة معالجة رسوميات H100.
لدعم استنتاج الإنتاج الضخم لنموذج 405B، قامت Meta بقياسه من 16 بت (BF16) إلى 8 بت (FP8)، مما أدى إلى تقليل متطلبات الحوسبة بشكل كبير وتمكين عقدة خادم واحدة من تشغيل النموذج.
بالإضافة إلى ذلك، تستخدم Meta نموذج 405B لتحسين جودة ما بعد التدريب لنموذجي 70B و8B. في مرحلة ما بعد التدريب، قام الفريق بتحسين نموذج الدردشة من خلال جولات متعددة من عمليات المحاذاة، بما في ذلك الضبط الدقيق الخاضع للإشراف (SFT)، وأخذ عينات الرفض، وتحسين التفضيل المباشر. ومن الجدير بالذكر أن معظم عينات SFT يتم إنشاؤها باستخدام البيانات الاصطناعية.
يدمج Llama3 أيضًا وظائف الصورة والفيديو والصوت، باستخدام نهج مشترك لتمكين النموذج من التعرف على الصور ومقاطع الفيديو ودعم التفاعل الصوتي. ومع ذلك، فإن هذه الميزات لا تزال قيد التطوير ولم يتم إصدارها رسميًا بعد.
قامت Meta أيضًا بتحديث اتفاقية الترخيص الخاصة بها للسماح للمطورين باستخدام مخرجات نموذج Llama لتحسين النماذج الأخرى.
قال الباحثون في Meta: من المثير للغاية العمل في طليعة الذكاء الاصطناعي مع أفضل المواهب في الصناعة ونشر نتائج الأبحاث بشكل مفتوح وشفاف. نحن نتطلع إلى رؤية الابتكار الذي تجلبه النماذج مفتوحة المصدر، وإمكانات نماذج سلسلة Llama المستقبلية!
ستوفر هذه المبادرة مفتوحة المصدر بلا شك فرصًا وتحديات جديدة في مجال الذكاء الاصطناعي وستعزز التطوير الإضافي لتكنولوجيا نماذج اللغة الكبيرة.
سيعمل المصدر المفتوح لـ Llama 3.1 405B على تعزيز تقدم تكنولوجيا نماذج اللغة الكبيرة بشكل كبير وسيجلب المزيد من الإمكانيات إلى مجال الذكاء الاصطناعي. نحن نتطلع إلى قيام المطورين بإنشاء المزيد من التطبيقات المذهلة بناءً على هذا النموذج!