لقد كان تحسين كفاءة نماذج اللغات الكبيرة دائمًا نقطة اهتمام بحثية في مجال الذكاء الاصطناعي. في الآونة الأخيرة، طورت فرق البحث من Aleph Alpha والجامعة التقنية في دارمشتات ومؤسسات أخرى طريقة جديدة تسمى T-FREE، والتي تعمل على تحسين كفاءة تشغيل نماذج اللغات الكبيرة بشكل كبير. تعمل هذه الطريقة على تقليل عدد معلمات طبقة التضمين باستخدام الأحرف الثلاثية للتنشيط المتناثر، وتشكل بشكل فعال التشابه المورفولوجي بين الكلمات، كما أنها تقلل بشكل كبير من استهلاك موارد الحوسبة مع ضمان أداء النموذج. توفر هذه التكنولوجيا المتقدمة إمكانيات جديدة لتطبيق نماذج لغوية كبيرة.
قدم فريق البحث مؤخرًا طريقة جديدة مثيرة تسمى T-FREE، والتي تتيح زيادة كفاءة تشغيل نماذج اللغات الكبيرة بشكل كبير. أطلق علماء من Aleph Alpha وTU Darmstadt وhessian.AI ومركز الأبحاث الألماني للذكاء الاصطناعي (DFKI) بشكل مشترك هذه التكنولوجيا المذهلة، واسمها الكامل هو "التمثيل المتناثر الخالي من العلامات، والتضمين الفعال للذاكرة ممكن."
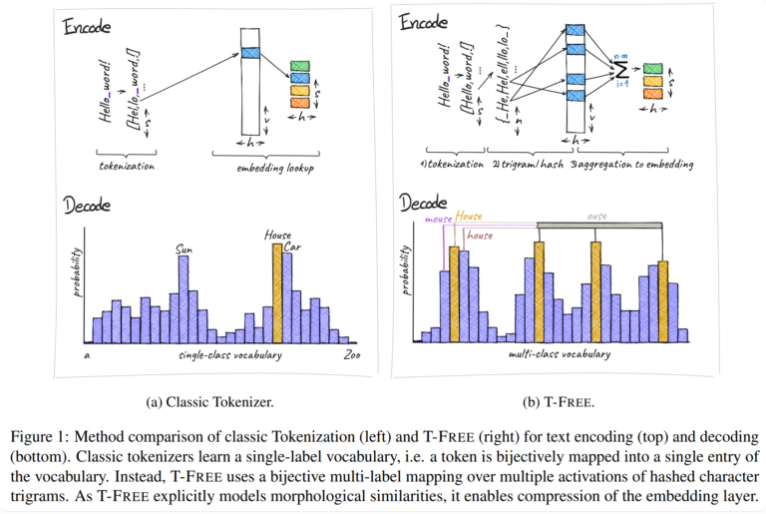
تقليديًا، نستخدم الرموز المميزة لتحويل النص إلى نموذج رقمي يمكن لأجهزة الكمبيوتر فهمه، لكن T-FREE اختارت مسارًا مختلفًا. ويستخدم الأحرف الثلاثية، ما نسميه "ثلاثية"، لتضمين الكلمات مباشرة في النموذج من خلال التنشيط المتناثر. ونتيجة لهذه الخطوة المبتكرة، تم تقليل عدد المعلمات في طبقة التضمين بنسبة مذهلة بلغت 85% أو أكثر، في حين لم يتأثر أداء النموذج على الإطلاق عند التعامل مع المهام مثل تصنيف النص والإجابة على الأسئلة.
ميزة أخرى لـ T-FREE هي أنها تصمم بذكاء شديد أوجه التشابه المورفولوجية بين الكلمات. تمامًا مثل الكلمات "منزل" و"منازل" و"محلي" التي نواجهها غالبًا في الحياة اليومية، يمكن لـ T-FREE تمثيل هذه الكلمات المشابهة بشكل أكثر فعالية في النموذج. ويعتقد الباحثون أن الكلمات المتشابهة يجب أن تكون مدمجة بالقرب من بعضها البعض لتحقيق معدلات ضغط أعلى. لذلك، لا يؤدي T-FREE إلى تقليل حجم طبقة التضمين فحسب، بل يقلل أيضًا من متوسط طول ترميز النص بنسبة 56%.
والجدير بالذكر أن T-FREE يؤدي أداءً جيدًا بشكل خاص في نقل التعلم بين اللغات المختلفة. في إحدى التجارب، استخدم الباحثون نموذجًا يحتوي على 3 مليارات معلمة، وتم تدريبهم أولاً باللغة الإنجليزية ثم باللغة الألمانية، ووجدوا أن T-FREE كان أكثر قدرة على التكيف من الأساليب التقليدية القائمة على العلامات.
ومع ذلك، لا يزال الباحثون متواضعين بشأن نتائجهم الحالية. ويعترفون بأن التجارب حتى الآن اقتصرت على نماذج تحتوي على ما يصل إلى 3 مليارات من المعلمات، ومن المقرر إجراء المزيد من التقييمات على نماذج أكبر ومجموعات بيانات أكبر في المستقبل.
يوفر ظهور طريقة T-FREE أفكارًا جديدة لتحسين كفاءة النماذج اللغوية الكبيرة، كما أن مزاياها في تقليل التكاليف الحسابية وتحسين أداء النموذج تستحق الاهتمام. ستركز اتجاهات البحث المستقبلية على التحقق من النماذج ومجموعات البيانات واسعة النطاق لتوسيع نطاق تطبيق T-FREE وتعزيز التطوير المستمر لتكنولوجيا نماذج اللغة واسعة النطاق. ومن المعتقد أن T-FREE ستلعب دورًا مهمًا في المزيد من المجالات في المستقبل القريب.