أصدرت Jina AI Reader-LM، وهو نموذج لغة خفيف الوزن مصمم خصيصًا لتحويل HTML إلى Markdown نظيف. يمكنه إزالة المحتوى المزدحم من صفحات الويب بكفاءة، مثل الإعلانات والبرامج النصية، لإنشاء ملفات Markdown منظمة بشكل واضح دون تعبيرات عادية معقدة أو عمليات يدوية. يتوفر Reader-LM في نسختين: Reader-LM-0.5B وReader-LM-1.5B، وكلاهما تم تحسينهما للعمل بكفاءة حتى في البيئات المحدودة الموارد وسياقات الدعم التي تصل إلى 256 ألف رمز مميز.
أطلقت Jina AI نموذجين لغويين صغيرين مصممين خصيصًا لتحويل محتوى HTML الأصلي إلى تنسيق Markdown نظيف وأنيق، مما يسمح لنا بالتخلص من معالجة بيانات صفحة الويب المملة.
أهم ما يميز هذا النموذج المسمى Reader-LM هو أنه يمكنه تحويل محتوى الويب بسرعة وكفاءة إلى ملفات Markdown.
وتتمثل ميزة استخدامه في أنك لم تعد بحاجة إلى الاعتماد على قواعد معقدة أو تعبيرات عادية شاقة. تعمل هذه النماذج على إزالة المحتوى المزدحم من صفحات الويب بذكاء وتلقائي، مثل الإعلانات والبرامج النصية وأشرطة التنقل، وفي النهاية تقدم تنسيق Markdown واضحًا ومنظمًا.
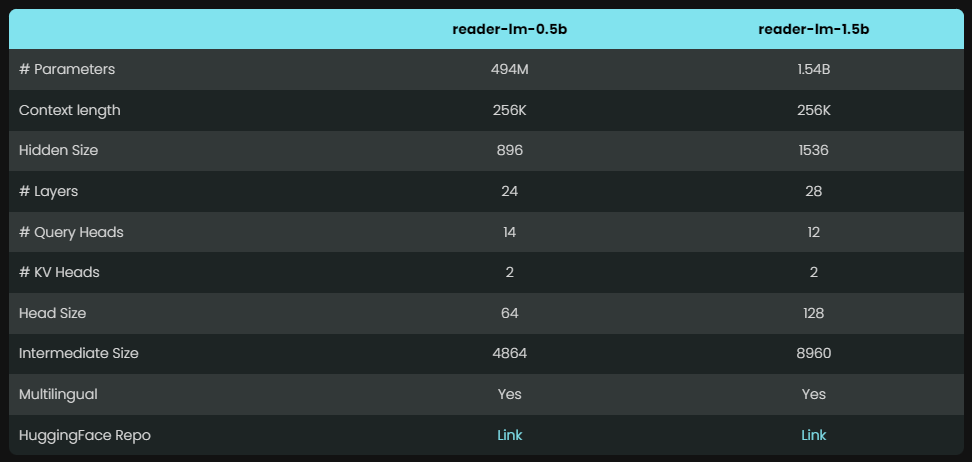
يوفر Reader-LM نموذجين بمعلمات مختلفة، وهما Reader-LM-0.5B وReader-LM-1.5B. على الرغم من أن عدد معلمات هذين النموذجين ليس كبيرًا، إلا أنه تم تحسينهما لمهمة تحويل HTML إلى Markdown، وكانت النتائج مفاجئة، وأداؤهما يفوق العديد من نماذج اللغات الكبيرة.
وبفضل تصميمها المدمج، يمكن لهذه النماذج أن تعمل بكفاءة في البيئات المحدودة الموارد. والأمر الأكثر جدارة بالثناء هو أن Reader-LM لا يدعم لغات متعددة فحسب، بل يمكنه أيضًا التعامل مع بيانات السياق التي تصل إلى 256 ألف رمز مميز، مما يجعل من الممكن التعامل حتى مع ملفات HTML المعقدة بسهولة.
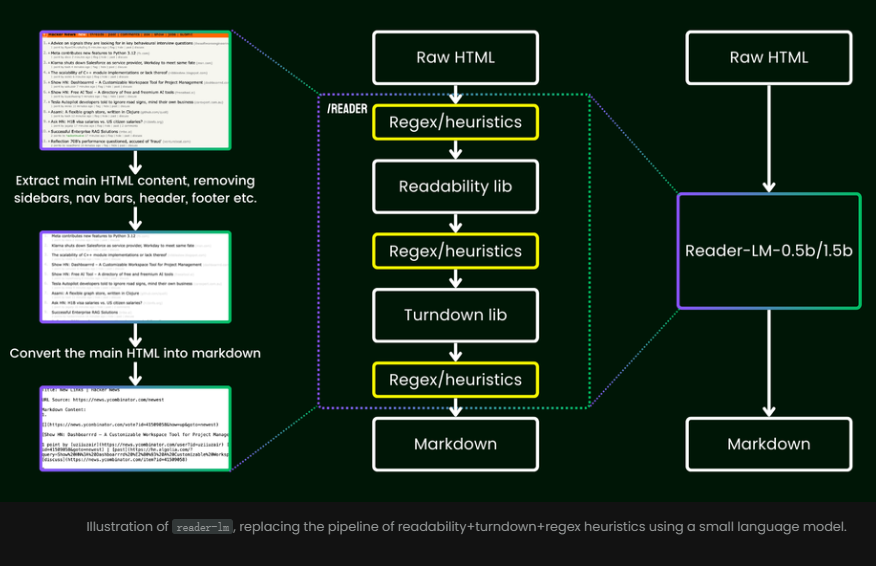
على عكس الطرق التقليدية التي تعتمد على التعبيرات العادية أو الإعدادات اليدوية، يوفر Reader-LM حلاً شاملاً يقوم تلقائيًا بتنظيف بيانات HTML واستخراج المعلومات الأساسية.
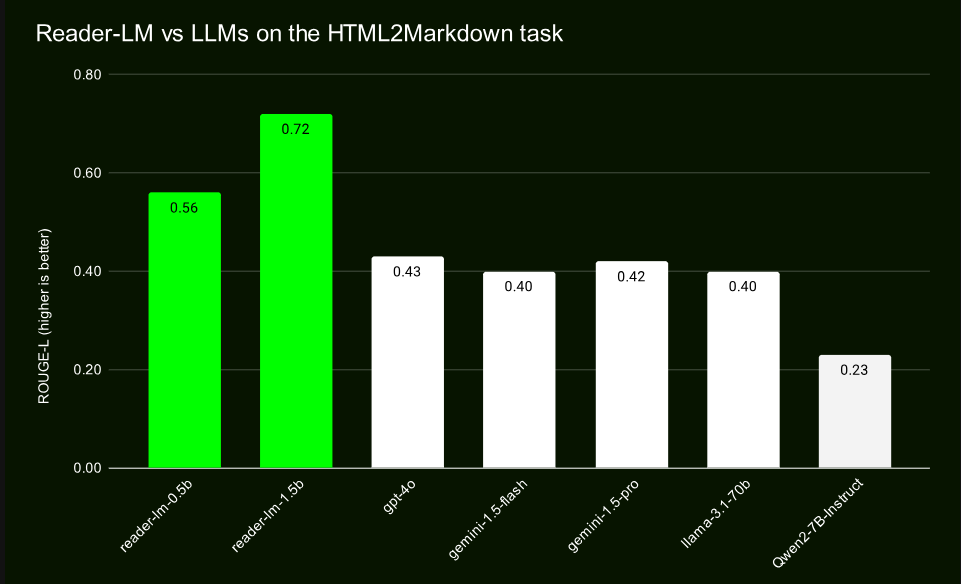
من خلال الاختبارات المقارنة مع نماذج واسعة النطاق مثل GPT-4 وGemini، أظهر Reader-LM أداءً ممتازًا، خاصة فيما يتعلق بالحفاظ على البنية واستخدام صيغة Markdown. يقدم Reader-LM-1.5B أداءً جيدًا بشكل خاص في مختلف المؤشرات، حيث تبلغ درجة ROUGE-L 0.72، مما يوضح دقته العالية في إنشاء المحتوى، كما أن معدل الخطأ فيه أقل بكثير من المنتجات المماثلة.
نظرًا للتصميم المدمج لـ Reader-LM، فهو أخف من حيث استخدام موارد الأجهزة، وخاصة الطراز 0.5B، والذي يمكن أن يعمل بسلاسة في بيئات منخفضة التكوين مثل Google Colab. على الرغم من صغر حجمه، لا يزال Reader-LM يتمتع بقدرات قوية لمعالجة السياق الطويل ويمكنه معالجة محتوى الويب الكبير والمعقد بكفاءة دون التأثير على الأداء.
فيما يتعلق بالتدريب، يعتمد Reader-LM عملية متعددة المراحل ويركز على استخراج محتوى Markdown من HTML الأصلي والصاخب.
تتضمن عملية التدريب اقتران عدد كبير من صفحات الويب الحقيقية والبيانات الاصطناعية، مما يضمن كفاءة النموذج ودقته. بعد تدريب مصمم بعناية على مرحلتين، قام Reader-LM بتحسين قدرته تدريجياً على معالجة ملفات HTML المعقدة وتجنب مشكلة الإنشاء المتكرر بشكل فعال.
المقدمة الرسمية: https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown/
بشكل عام، يوفر Reader-LM حلاً فعالاً ومريحًا ودقيقًا لتحويل HTML إلى Markdown، كما أن تصميمه خفيف الوزن يجعل من السهل تشغيله في بيئات مختلفة، مما يجعله خيارًا مثاليًا لمعالجة بيانات صفحة الويب. لمزيد من المعلومات، يرجى زيارة الرابط التعريفي الرسمي.