أعلنت شركة Kunlun Technology مؤخرًا أن نموذجي المكافآت اللذين طورتهما، Skywork-Reward-Gemma-2-27B وSkywork-Reward-Llama-3.1-8B، حققا نتائج ممتازة على RewardBench، مع تصدر نموذج 27B القائمة. يشير هذا إلى أن شركة Kunlun Wanwei قد حققت تقدمًا كبيرًا في مجال الذكاء الاصطناعي، خاصة في البحث وتطوير نماذج المكافآت، وتوفر دعمًا فنيًا جديدًا للتدريب على نماذج اللغات الكبيرة. تعتبر نماذج المكافأة حاسمة في التعلم المعزز، حيث يمكنها توجيه التعلم النموذجي وإنشاء محتوى أكثر انسجاما مع التفضيلات البشرية. يتمتع نموذج Kunlun Wanwei بمزايا فريدة في اختيار البيانات والتدريب على النماذج، مما يجعله يؤدي أداءً جيدًا في جوانب مثل الحوار والأمن، ويظهر بشكل خاص قدرات قوية عند معالجة العينات الصعبة.
أعلنت شركة Kunlun Wanwei Technology Co., Ltd. مؤخرًا أن نموذجي المكافآت الجديدين اللذين طورتهما الشركة، Skywork-Reward-Gemma-2-27B وSkywork-Reward-Llama-3.1-8B، حققا أداءً جيدًا على RewardBench، نموذج المكافآت المعتمد عالميًا ومن بينها، فاز نموذج Skywork-Reward-Gemma-2-27B بالمركز الأول وحصل على تقدير كبير من قبل مسؤولي RewardBench.
يحتل نموذج المكافأة موقعًا أساسيًا في التعلم المعزز، وتقييم أداء الوكيل في حالات مختلفة، وتوفير إشارات المكافأة لتوجيه عملية تعلم الوكيل، حتى يتمكن من اتخاذ الاختيار الأمثل في بيئة معينة. في تدريب نماذج اللغات الكبيرة، يلعب نموذج المكافأة دورًا حاسمًا بشكل خاص، حيث يساعد النموذج على فهم وإنشاء محتوى يتوافق مع التفضيلات البشرية بشكل أكثر دقة.
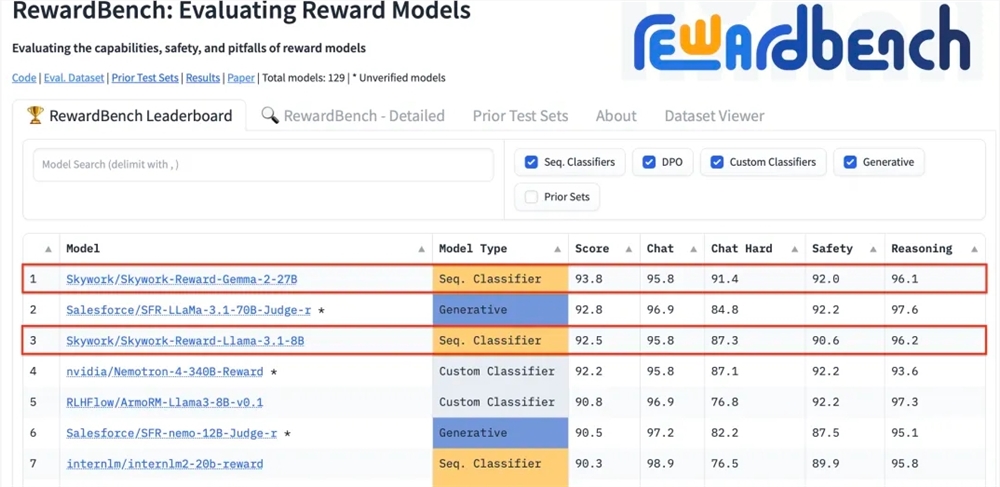
RewardBench عبارة عن قائمة قياس أداء تقوم على وجه التحديد بتقييم فعالية نماذج المكافأة في نماذج اللغات الكبيرة، وتقوم بتقييم النماذج بشكل شامل من خلال مهام متعددة، بما في ذلك الحوار والاستدلال والأمان. تتكون مجموعة بيانات الاختبار في هذه القائمة من ثلاث مرات تتكون من كلمات سريعة، واستجابات محددة، واستجابات مرفوضة، ويتم استخدامها لاختبار ما إذا كان نموذج المكافأة يمكنه تصنيف الاستجابات المحددة بشكل صحيح بين الاستجابات المرفوضة بالنظر إلى الكلمات السريعة قبل رفض الاستجابة .
تم تطوير نموذج Skywork-Reward الخاص بـ Kunlun Wanwei من خلال مجموعات بيانات مرتبة جزئيًا مختارة بعناية ونماذج أساسية صغيرة نسبيًا، وبالمقارنة مع نماذج المكافآت الحالية، فإن بياناتها المرتبة جزئيًا تأتي فقط من البيانات العامة على الإنترنت ويتم تصفيتها من خلال استراتيجيات محددة للحصول على نقاط عالية -مجموعات بيانات تفضيلات الجودة. تغطي البيانات مجموعة واسعة من المواضيع، بما في ذلك الأمان والرياضيات والتعليمات البرمجية، ويتم التحقق منها يدويًا لضمان موضوعية البيانات وأهمية فجوات المكافآت.
بعد الاختبار، أظهر نموذج المكافأة الخاص بـ Kunlun Wanwei أداءً ممتازًا في مجالات مثل الحوار والأمن، خاصة عند مواجهة عينات صعبة، فقط نموذج Skywork-Reward-Gemma-2-27B أعطى تنبؤات صحيحة. ويمثل هذا الإنجاز القوة التقنية وقدرات الابتكار لشركة كونلون وانو في مجال الذكاء الاصطناعي العالمي، كما يوفر إمكانيات جديدة لتطوير وتطبيق تكنولوجيا الذكاء الاصطناعي.
عنوان نموذج 27B:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
عنوان النموذج 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
يُظهر أداء Kunlun Wanwei الممتاز على RewardBench قدراتها التكنولوجية والابتكارية الرائدة في مجال الذكاء الاصطناعي، كما أنه يوفر اتجاهات وإمكانيات جديدة للتطوير المستقبلي لنماذج اللغات الكبيرة. ونحن نتطلع إلى تحقيق المزيد من النتائج في المستقبل.