حقق بحث فريق مامبا تقدمًا كبيرًا، حيث نجحوا في "تقطير" نموذج المحول الكبير لاما إلى نموذج مامبا أكثر كفاءة. يجمع هذا البحث بذكاء بين تقنيات مثل التقطير التدريجي، والضبط الدقيق الخاضع للإشراف، وتحسين التفضيلات الاتجاهية، ويصمم خوارزمية فك تشفير استدلالية جديدة تعتمد على البنية الفريدة لنموذج مامبا، والتي تعمل على تحسين سرعة الاستدلال للنموذج بشكل كبير دون ضمان تحسين كبير في الأداء في الكفاءة تم تحقيقها دون خسارة. لا يقلل هذا البحث من تكلفة التدريب على النماذج واسعة النطاق فحسب، بل يقدم أيضًا أفكارًا جديدة لتحسين النموذج في المستقبل، وهو ما له أهمية أكاديمية وقيمة تطبيقية مهمة.
في الآونة الأخيرة، كان البحث الذي أجراه فريق مامبا ملفتًا للنظر: فقد نجح باحثون من جامعات مثل كورنيل وبرينستون في "تقطير" اللاما، وهو نموذج محول كبير، إلى مامبا، وصمموا خوارزمية جديدة لفك تشفير الاستدلال أدت إلى تحسين سرعة الاستدلال النموذجي بشكل كبير.
هدف الباحثين هو تحويل اللاما إلى مامبا. لماذا نفعل ذلك؟ لأن تدريب نموذج كبير من الصفر أمر مكلف، وقد حظيت مامبا باهتمام واسع النطاق منذ بدايتها، لكن القليل من الفرق تقوم بالفعل بتدريب نماذج مامبا واسعة النطاق بنفسها. على الرغم من وجود بعض المتغيرات ذات السمعة الطيبة في السوق، مثل Jamba من AI21 وHybrid Mamba2 من NVIDIA، إلا أن هناك ثروة من المعرفة مضمنة في العديد من نماذج Transformer الناجحة. إذا تمكنا من الاحتفاظ بهذه المعرفة وضبط المحول إلى Mamba، فسيتم حل المشكلة.
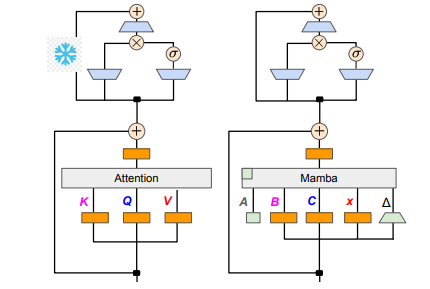
نجح فريق البحث في تحقيق هذا الهدف من خلال الجمع بين أساليب مختلفة مثل التقطير التدريجي والضبط الدقيق الخاضع للإشراف وتحسين التفضيل الاتجاهي. ومن الجدير بالذكر أن السرعة أمر بالغ الأهمية أيضًا دون المساس بالأداء. تتمتع Mamba بمزايا واضحة في الاستدلال بالتسلسل الطويل، ولدى Transformer أيضًا حلول تسريع الاستدلال، مثل فك التشفير التأملي. نظرًا لأن بنية Mamba الفريدة لا يمكنها تطبيق هذه الحلول بشكل مباشر، فقد صمم الباحثون خوارزمية جديدة خصيصًا ودمجوها مع ميزات الأجهزة لتنفيذ فك التشفير التأملي القائم على Mamba.
وأخيرًا، نجح الباحثون في تحويل Zephyr-7B وLlama-38B إلى نماذج RNN خطية، وكان أدائها مشابهًا للنموذج القياسي قبل التقطير. تستخدم عملية التدريب بأكملها 20B من الرموز المميزة فقط، والنتائج قابلة للمقارنة بنموذج Mamba7B الذي تم تدريبه من الصفر باستخدام 1.2T من الرموز المميزة ونموذج NVIDIA Hybrid Mamba2 الذي تم تدريبه باستخدام 3.5T من الرموز المميزة.
من حيث التفاصيل الفنية، يتم توصيل RNN الخطي والانتباه الخطي، بحيث يمكن للباحثين إعادة استخدام مصفوفة الإسقاط مباشرة في آلية الانتباه واستكمال بناء النموذج من خلال تهيئة المعلمة. بالإضافة إلى ذلك، قام فريق البحث بتجميد معلمات طبقة MLP في Transformer، واستبدال رأس الانتباه تدريجيًا بطبقة RNN خطية (أي Mamba)، ومعالجة استعلام المجموعة للمفاتيح والقيم المشتركة عبر الرؤوس.
أثناء عملية التقطير، يتم اعتماد استراتيجية استبدال طبقات الانتباه تدريجيًا. يتضمن الضبط الدقيق الخاضع للإشراف طريقتين رئيسيتين: إحداهما تعتمد على اختلاف KL على مستوى الكلمة، والأخرى هي تقطير المعرفة على مستوى التسلسل. في مرحلة ضبط تفضيلات المستخدم، استخدم الفريق طريقة تحسين التفضيلات المباشرة (DPO) للتأكد من أن النموذج يمكنه تلبية توقعات المستخدم بشكل أفضل عند إنشاء المحتوى من خلال مقارنته بمخرجات نموذج المعلم.
بعد ذلك، بدأ الباحثون في تطبيق فك التشفير التأملي للمحول على نموذج مامبا. يمكن فهم فك التشفير التأملي ببساطة على أنه استخدام نموذج صغير لإنشاء مخرجات متعددة، ثم استخدام نموذج كبير للتحقق من هذه المخرجات. تعمل النماذج الصغيرة بسرعة ويمكنها إنشاء متجهات مخرجات متعددة بسرعة، بينما تكون النماذج الكبيرة مسؤولة عن تقييم دقة هذه المخرجات، وبالتالي زيادة سرعة الاستدلال الإجمالية.
ومن أجل تنفيذ هذه العملية، صمم الباحثون مجموعة من الخوارزميات التي تستخدم نموذجًا صغيرًا لتوليد مخرجات مسودة K في كل مرة، ومن ثم يقوم النموذج الكبير بإرجاع المخرجات النهائية وذاكرة التخزين المؤقت للحالات المتوسطة من خلال التحقق. حققت هذه الطريقة نتائج جيدة على وحدة معالجة الرسومات Mamba2.8B التي حققت 1.5 مرة من تسريع الاستدلال، ووصل معدل القبول إلى 60%. على الرغم من أن التأثيرات تختلف على وحدات معالجة الرسومات ذات البنى المختلفة، فقد قام فريق البحث بتحسينها بشكل أكبر من خلال دمج النواة وتعديل طرق التنفيذ، وحقق أخيرًا تأثير التسريع المثالي.
في المرحلة التجريبية، استخدم الباحثون Zephyr-7B وLlama-3Instruct8B لإجراء تدريب على التقطير على ثلاث مراحل. وفي النهاية، استغرق الأمر من 3 إلى 4 أيام فقط للتشغيل على 80G A100 المكونة من 8 بطاقات لإعادة إنتاج نتائج البحث بنجاح. لا يوضح هذا البحث التحول بين Mamba وLlama فحسب، بل يقدم أيضًا أفكارًا جديدة لتحسين سرعة الاستدلال وأداء النماذج المستقبلية.
عنوان الورقة: https://arxiv.org/pdf/2408.15237
يوفر هذا البحث خبرة قيمة وحلولًا تقنية لتحسين كفاءة النماذج اللغوية واسعة النطاق، ومن المتوقع أن يتم تطبيق النتائج على المزيد من المجالات وتعزيز التطوير الإضافي لتكنولوجيا الذكاء الاصطناعي. إن توفير عنوان الورقة يسهل على القراء الحصول على فهم أعمق لتفاصيل البحث.