تعاونت Google DeepMind مع عدد من الجامعات لتطوير طريقة جديدة تسمى نموذج المكافأة التوليدية (GenRM)، والتي تهدف إلى حل مشكلة عدم كفاية الدقة والموثوقية للذكاء الاصطناعي التوليدي في مهام التفكير. على الرغم من أن نماذج الذكاء الاصطناعي التوليدية الحالية تُستخدم على نطاق واسع في مجالات مثل معالجة اللغة الطبيعية، إلا أنها غالبًا ما تنتج معلومات خاطئة بثقة، خاصة في المجالات التي تتطلب دقة عالية للغاية، مما يحد من نطاق تطبيقها. يتمثل ابتكار GenRM في إعادة تعريف عملية التحقق باعتبارها مهمة تنبؤ بالكلمات التالية، ودمج إمكانات إنشاء النص لنماذج اللغة الكبيرة (LLMs) في عملية التحقق، ودعم المنطق المتسلسل، وبالتالي تحقيق تحقق أكثر شمولاً ومنهجية.
في الآونة الأخيرة، تعاون فريق بحث Google DeepMind مع عدد من الجامعات لاقتراح طريقة جديدة تسمى نموذج المكافأة التوليدية (GenRM)، والتي تهدف إلى تحسين دقة وموثوقية الذكاء الاصطناعي التوليدي في مهام التفكير.
يستخدم الذكاء الاصطناعي التوليدي على نطاق واسع في العديد من المجالات مثل معالجة اللغة الطبيعية، فهو ينتج بشكل أساسي نصًا متماسكًا من خلال التنبؤ بالكلمة التالية في سلسلة من الكلمات. ومع ذلك، أحيانًا ما تقوم هذه النماذج بإخراج معلومات غير صحيحة بثقة، وهو ما يمثل مشكلة كبيرة خاصة في المجالات التي تكون فيها الدقة أمرًا بالغ الأهمية، مثل التعليم والتمويل والرعاية الصحية.
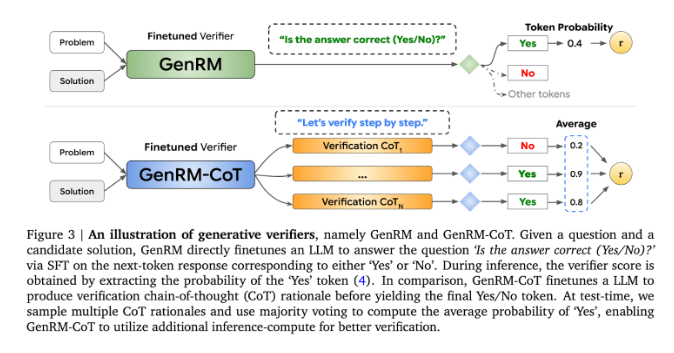
حاليًا، جرب الباحثون حلولًا مختلفة للصعوبات التي تواجهها نماذج الذكاء الاصطناعي التوليدية في دقة الإخراج. من بينها، تُستخدم نماذج المكافأة التمييزية (RMs) لتحديد ما إذا كانت الإجابات المحتملة صحيحة بناءً على الدرجات، ولكن هذه الطريقة تفشل في الاستفادة الكاملة من القدرات التوليدية لنماذج اللغات الكبيرة (LLMs). هناك طريقة أخرى شائعة الاستخدام وهي "LLM as القاضي"، ولكن هذه الطريقة غالبًا ما لا تكون فعالة مثل المدقق المحترف عند حل مهام التفكير المعقدة.
يتمثل ابتكار GenRM في إعادة تعريف عملية التحقق باعتبارها مهمة تنبؤ بالكلمة التالية. وهذا يعني أنه، على عكس نماذج المكافآت التمييزية التقليدية، يدمج GenRM إمكانات إنشاء النص الخاصة بـ LLMs في عملية التحقق، مما يسمح للنموذج بإنشاء الحلول المحتملة وتقييمها في وقت واحد. بالإضافة إلى ذلك، يدعم GenRM أيضًا الاستدلال المتسلسل (CoT)، أي أن النموذج يمكنه إنشاء خطوات استدلال وسيطة قبل الوصول إلى الاستنتاج النهائي، مما يجعل عملية التحقق أكثر شمولاً ومنهجية.
من خلال الجمع بين التوليد والتحقق من الصحة، يعتمد نهج GenRM استراتيجية تدريب موحدة تمكن النموذج من تحسين قدرات التوليد والتحقق في نفس الوقت أثناء التدريب. في التطبيقات الحقيقية، يقوم النموذج بإنشاء خطوات استدلال وسيطة تستخدم للتحقق من الإجابة النهائية.
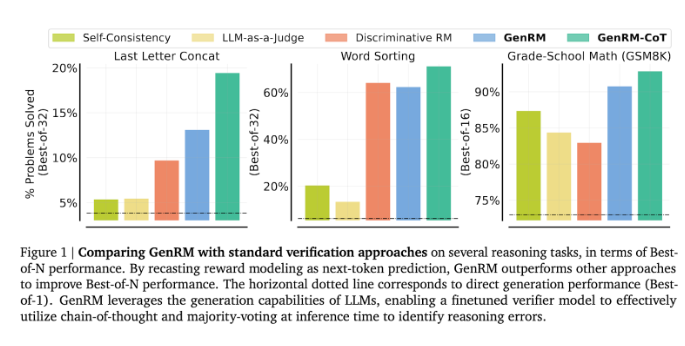
وجد الباحثون أن نموذج GenRM كان أداؤه جيدًا في العديد من الاختبارات الصارمة، مثل الدقة المحسنة بشكل كبير في الرياضيات في مرحلة ما قبل المدرسة ومهام حل المشكلات الخوارزمية. بالمقارنة مع نموذج المكافأة التمييزية وطريقة LLM كحكم، ارتفع معدل نجاح GenRM في حل المشكلات بنسبة 16% إلى 64%.
على سبيل المثال، عند التحقق من مخرجات نموذج Gemini1.0Pro، قام GenRM بزيادة معدل نجاح حل المشكلات من 73% إلى 92.8%.
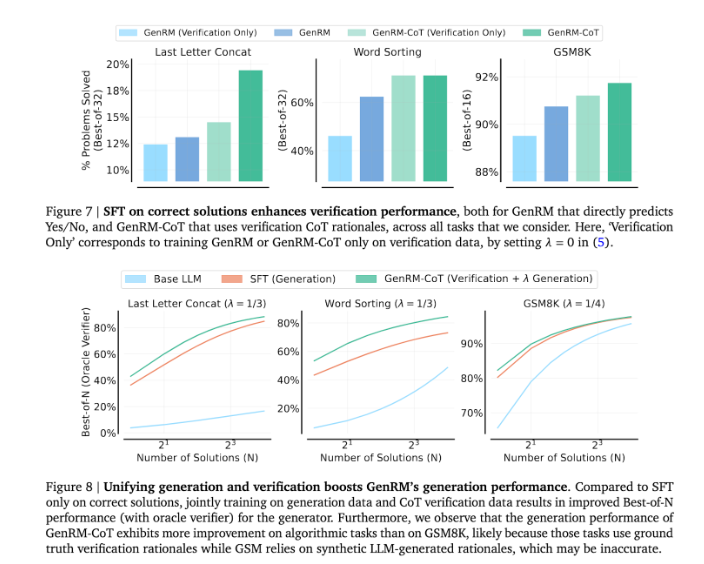
يمثل إدخال طريقة GenRM تقدمًا كبيرًا في مجال الذكاء الاصطناعي التوليدي، مما يؤدي إلى تحسين كبير في دقة وموثوقية الحلول التي ينشئها الذكاء الاصطناعي من خلال توحيد توليد الحلول والتحقق منها في عملية واحدة.
بشكل عام، يوفر ظهور GenRM أفكارًا جديدة لتحسين موثوقية الذكاء الاصطناعي التوليدي، ويشير تحسنه الكبير في حل مشكلات التفكير المعقدة إلى إمكانية تطبيق الذكاء الاصطناعي التوليدي في المزيد من المجالات، وهو أمر يستحق المزيد من البحث والاستكشاف.