يعتمد مُحسِّن استعلام قاعدة البيانات بشكل كبير على تقدير العلاقة الأساسية (CE) للتنبؤ بأحجام نتائج الاستعلام وبالتالي تحديد أفضل خطة تنفيذ. يمكن أن تؤدي التقديرات الأساسية غير الدقيقة إلى انخفاض أداء الاستعلام. أساليب CE الحالية لها قيود، خاصة عند التعامل مع الاستعلامات المعقدة. على الرغم من أن نموذج التعلم CE أكثر دقة، إلا أن تكلفة تدريبه مرتفعة ويفتقر إلى التقييم المرجعي المنهجي.
في قواعد البيانات العلائقية الحديثة، يلعب تقدير العلاقة الأساسية (CE) دورًا حاسمًا. ببساطة، تقدير العلاقة الأساسية هو توقع لعدد النتائج الوسيطة التي سيرجعها استعلام قاعدة البيانات. هذا التنبؤ له تأثير كبير على اختيارات خطة تنفيذ مُحسِّن الاستعلام، مثل تحديد ترتيب الانضمام، وما إذا كان سيتم استخدام الفهارس، واختيار أفضل أسلوب ربط. إذا كان تقدير الأصل غير دقيق، فقد تتعرض خطة التنفيذ للخطر بشكل كبير، مما يؤدي إلى سرعات استعلام بطيئة للغاية ويؤثر بشكل خطير على الأداء العام لقاعدة البيانات.
ومع ذلك، فإن أساليب تقدير العلاقة الأساسية الحالية لها العديد من القيود. تعتمد تقنية CE التقليدية على بعض الافتراضات المبسطة وغالبًا ما تتنبأ بدقة بأصل الاستعلامات المعقدة، خاصة عندما تتضمن جداول وشروط متعددة. على الرغم من أن نماذج التعلم CE يمكن أن توفر دقة أفضل، إلا أن تطبيقها محدود بسبب أوقات التدريب الطويلة، والحاجة إلى مجموعات كبيرة من البيانات، وعدم وجود تقييم مرجعي منهجي.
ولسد هذه الفجوة، أطلق فريق بحث جوجل CardBench، وهو إطار عمل جديد لقياس الأداء. يتضمن CardBench أكثر من 20 قاعدة بيانات واقعية وآلاف الاستعلامات، وهو ما يتجاوز بكثير المعايير السابقة. يتيح ذلك للباحثين إجراء تقييم منهجي ومقارنة نماذج التعلم CE المختلفة في ظل ظروف مختلفة. يدعم المعيار ثلاثة إعدادات رئيسية: النماذج القائمة على المثيلات، ونماذج اللقطة الصفرية، والنماذج المضبوطة بدقة، والمناسبة لاحتياجات التدريب المختلفة.
تم تصميم CardBench أيضًا ليشمل مجموعة من الأدوات التي يمكنها حساب الإحصائيات الضرورية، وإنشاء استعلامات SQL حقيقية، وإنشاء رسوم بيانية استعلامية مشروحة لتدريب نماذج CE.
يوفر المعيار مجموعتين من بيانات التدريب: واحدة لاستعلام جدول واحد مع مسندات مرشح متعددة، وواحدة لاستعلام ربط ثنائي يتضمن جدولين. يتضمن المعيار 9125 استعلامًا لجدول واحد و8454 استعلام ربط ثنائي في إحدى مجموعات البيانات الأصغر، مما يضمن بيئة قوية ومليئة بالتحديات لتقييم النموذج. تطلبت تسميات بيانات التدريب من Google BigQuery 7 سنوات من وقت تنفيذ الاستعلام لوحدة المعالجة المركزية، مما يسلط الضوء على الاستثمار الحسابي الكبير في إنشاء هذا المعيار. ومن خلال توفير مجموعات البيانات والأدوات هذه، تعمل CardBench على تقليل العوائق أمام الباحثين لتطوير واختبار نماذج CE جديدة.
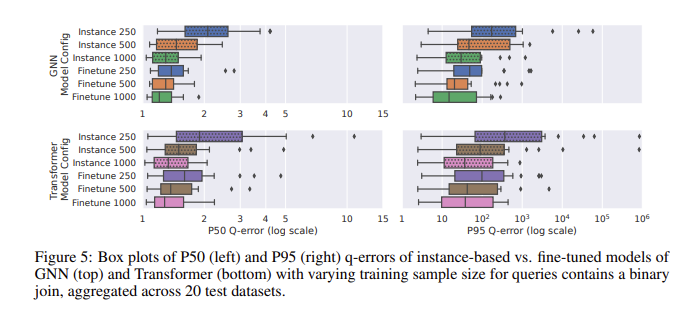
في تقييم الأداء باستخدام CardBench، كان أداء النموذج المضبوط جيدًا بشكل خاص. في حين أن النماذج الصفرية تكافح من أجل تحسين الدقة عند تطبيقها على مجموعات البيانات غير المرئية، خاصة في الاستعلامات المعقدة التي تتضمن الصلات، يمكن للنماذج المضبوطة بدقة تحقيق دقة مماثلة للطرق القائمة على المثيلات مع بيانات تدريب أقل بكثير. على سبيل المثال، حقق نموذج الشبكة العصبية الرسومية (GNN) المضبوط بدقة متوسط خطأ q يبلغ 1.32 وخطأ q مئوي 95 قدره 120 في استعلامات الربط الثنائية، وهو أفضل بكثير من نموذج اللقطة الصفرية. تظهر النتائج أنه حتى مع وجود 500 استعلام، فإن الضبط الدقيق للنموذج الذي تم تدريبه مسبقًا يمكن أن يؤدي إلى تحسين أدائه بشكل كبير. وهذا يجعلها مناسبة للتطبيقات العملية حيث قد تكون بيانات التدريب محدودة.
يجلب تقديم CardBench أملاً جديدًا في مجال تقدير العلاقة الأساسية المستفادة، مما يسمح للباحثين بتقييم النماذج وتحسينها بشكل أكثر فعالية، وبالتالي دفع المزيد من التطوير في هذا المجال المهم.
المدخل الورقي: https://arxiv.org/abs/2408.16170
باختصار، يوفر CardBench إطارًا مرجعيًا شاملاً وقويًا، ويوفر أدوات وموارد مهمة للبحث وتطوير نماذج تقدير أصل التعلم، ويعزز تقدم تقنية تحسين استعلام قاعدة البيانات. إن الأداء الممتاز لنموذجه المضبوط يستحق الاهتمام بشكل خاص، مما يوفر إمكانيات جديدة لسيناريوهات التطبيق العملي.