مؤخرًا، أظهرت دراسة نُشرت في مجلة Cureus أن نموذج GPT-4 من OpenAI اجتاز بنجاح الاختبار الوطني الياباني للعلاج الطبيعي دون تدريب إضافي. اختبر الباحثون اختبار GPT-4 باستخدام 1000 سؤال يغطي الذاكرة والفهم والتطبيق والتحليل والتقييم، وأظهرت النتائج أن معدل دقة الاختبار بلغ 73.4% واجتاز جميع أجزاء الاختبار الخمسة. يثير هذا البحث مخاوف بشأن إمكانات GPT-4 للتطبيقات الطبية، بينما يكشف أيضًا عن حدوده في التعامل مع أنواع معينة من المشكلات، مثل المشكلات العملية وتلك التي تحتوي على جداول صور.
أظهرت دراسة حديثة تمت مراجعتها من قبل النظراء ونشرت في مجلة Cureus أن نموذج اللغة GPT-4 الخاص بـ OpenAI اجتاز بنجاح الاختبار الوطني الياباني للعلاج الطبيعي دون أي تدريب إضافي.
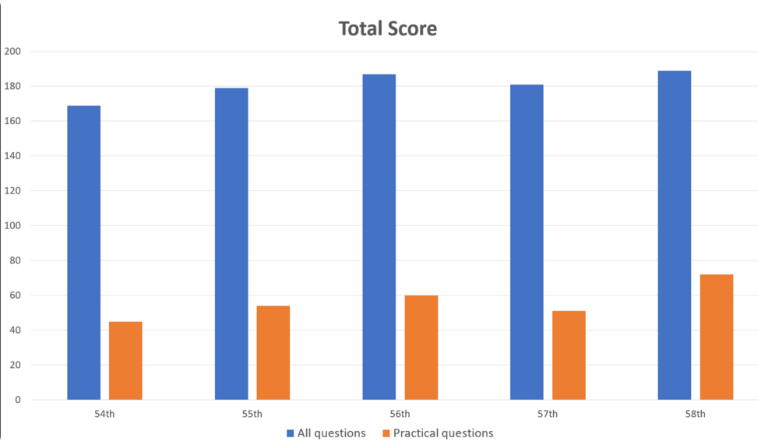
قام الباحثون بتغذية 1000 سؤال في GPT-4، والتي تغطي مجالات مثل الذاكرة والفهم والتطبيق والتحليل والتقييم. أظهرت النتائج أن اختبار GPT-4 أجاب على 73.4% من الأسئلة بشكل صحيح بشكل عام، مجتازًا جميع أجزاء الاختبار الخمسة. ومع ذلك، كشفت الأبحاث أيضًا عن قيود الذكاء الاصطناعي في بعض المجالات.

كان أداء GPT-4 جيدًا في المشكلات العامة، بدقة بلغت 80.1%، ولكن بنسبة 46.6% فقط في المشكلات العملية. وبالمثل، فهو أفضل بكثير في التعامل مع الأسئلة النصية فقط (صحيح بنسبة 80.5%) مقارنة بالأسئلة التي تحتوي على صور وجداول (صحيح بنسبة 35.4%). تتوافق هذه النتيجة مع الأبحاث السابقة حول قيود الفهم البصري لـ GPT-4.
تجدر الإشارة إلى أن صعوبة السؤال وطول النص لهما تأثير ضئيل على أداء GPT-4. على الرغم من أن النموذج تم تدريبه في المقام الأول باستخدام البيانات الإنجليزية، إلا أنه كان أداؤه جيدًا أيضًا عند التعامل مع المدخلات اليابانية.
وأشار الباحثون إلى أنه على الرغم من أن هذه الدراسة توضح إمكانات GPT-4 في إعادة التأهيل السريري والتعليم الطبي، إلا أنه ينبغي النظر إليها بحذر. وشددوا على أن GPT-4 لا يجيب على جميع الأسئلة بشكل صحيح وأن هناك حاجة إلى تقييمات مستقبلية للإصدارات الجديدة وقدرات النموذج في الاختبارات الكتابية والاستدلالية.
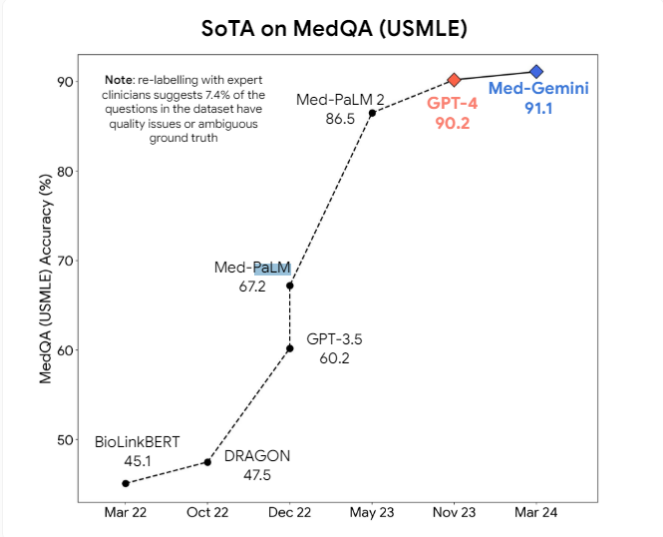
بالإضافة إلى ذلك، اقترح الباحثون أن النماذج متعددة الوسائط مثل GPT-4v قد تجلب المزيد من التحسينات في الفهم البصري. حاليًا، يجري تطوير نماذج الذكاء الاصطناعي الطبية الاحترافية مثل Med-PaLM2 وMed-Gemini من Google، بالإضافة إلى نموذج Meta الطبي المعتمد على Llama3، بهدف تجاوز النماذج ذات الأغراض العامة في المهام الطبية.
ومع ذلك، يعتقد الخبراء أن الأمر قد يستغرق وقتًا طويلاً قبل استخدام نماذج الذكاء الاصطناعي الطبية على نطاق واسع في الممارسة العملية. تظل مساحة الخطأ في النماذج الحالية كبيرة جدًا في البيئات الطبية، ويلزم تحقيق تقدم كبير في قدرات الاستدلال لدمج هذه النماذج بأمان في الممارسة الطبية اليومية.
على الرغم من أن هذه الدراسة توضح إمكانات GPT-4 في المجال الطبي، إلا أنها تذكرنا أيضًا بأن تكنولوجيا الذكاء الاصطناعي لا تزال بحاجة إلى التحسين المستمر قبل أن يتم تطبيقها حقًا على السيناريوهات الطبية المعقدة. في المستقبل، ستكون النماذج متعددة الوسائط وقدرات الاستدلال الأكثر قوة بمثابة تحسينات رئيسية لضمان سلامة وموثوقية الذكاء الاصطناعي في الرعاية الطبية.