لقد التزم مجال الذكاء الاصطناعي بالسماح للآلات بفهم العالم المادي المعقد، وتعد الإنجازات في هذا المجال حاسمة في العديد من المجالات. في الآونة الأخيرة، قامت فرق بحثية من جامعة رنمين الصينية، وجامعة بكين للبريد والاتصالات، ومختبر شنغهاي للذكاء الاصطناعي ومؤسسات أخرى بتطوير تقنية Ref-AVS، مما يوفر حلاً جديدًا لهذه المشكلة. تدمج تقنية Ref-AVS معلومات وسائط متعددة مثل تجزئة كائن الفيديو وتجزئة مرجع كائن الفيديو وتجزئة الصوت والصورة من خلال طريقة دمج ذكية متعددة الوسائط، مما يمكّن نظام الذكاء الاصطناعي من فهم تعليمات اللغة الطبيعية بدقة أكبر وتنفيذ عمليات صوتية معقدة. المهام المرئية: إن تحديد المواقع بدقة للأشياء المستهدفة في المشهد يكسر القيود السابقة للذكاء الاصطناعي في الفهم متعدد الوسائط.
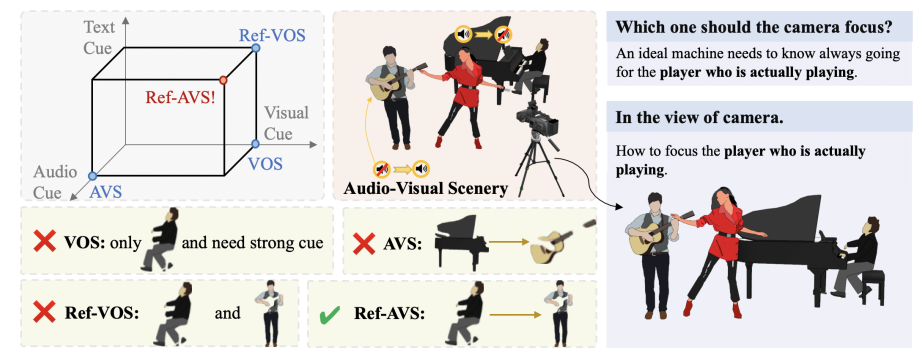
في مجال الذكاء الاصطناعي، كان جعل الآلات تفهم العالم المادي المعقد مثل البشر دائمًا تحديًا كبيرًا. في الآونة الأخيرة، اقترح فريق بحث مكون من جامعة رنمين الصينية، وجامعة بكين للبريد والاتصالات، ومختبر شنغهاي للذكاء الاصطناعي ومؤسسات أخرى، تقنية متقدمة - Ref-AVS، والتي تجلب أملًا جديدًا لحل هذه المشكلة.
يكمن جوهر تقنية Ref-AVS في طريقة الدمج الفريدة متعددة الوسائط. فهو يدمج بذكاء معلومات مشروطة متعددة مثل تجزئة كائن الفيديو (VOS)، وتجزئة مرجع كائن الفيديو (Ref-VOS)، وتجزئة الصوت والصورة (AVS). يمكّن هذا الاندماج المبتكر نظام الذكاء الاصطناعي ليس فقط من معالجة الكائنات التي تصدر أصواتًا، ولكن أيضًا من تحديد الكائنات غير الصوتية ولكن ذات الأهمية نفسها في المشهد. يسمح هذا الإنجاز للذكاء الاصطناعي بفهم التعليمات التي وصفها المستخدمون بدقة أكبر من خلال اللغة الطبيعية وتحديد مواقع كائنات محددة بدقة في المشاهد الصوتية والمرئية المعقدة.
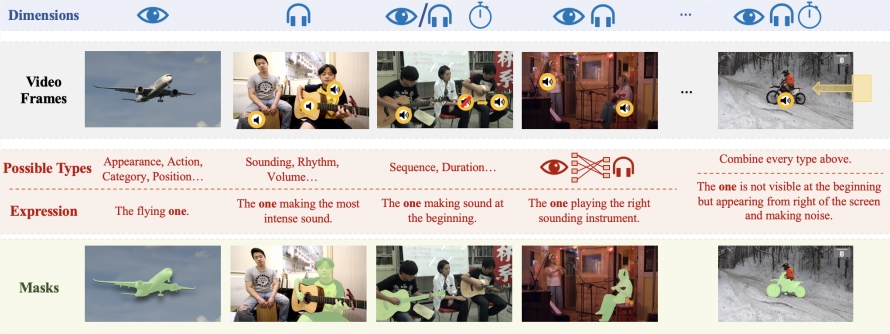
لدعم البحث والتحقق من تقنية Ref-AVS، أنشأ فريق البحث مجموعة بيانات واسعة النطاق تسمى Ref-AVS Bench. تحتوي مجموعة البيانات هذه على 40,020 إطار فيديو يغطي 6,888 كائنًا و20,261 تعبيرًا مرجعيًا. يكون كل إطار فيديو مصحوبًا بتعليق توضيحي تفصيلي على مستوى الصوت والبكسل. توفر مجموعة البيانات الغنية والمتنوعة هذه أساسًا متينًا للبحث متعدد الوسائط وتفتح إمكانيات جديدة للبحث المستقبلي في المجالات ذات الصلة.
وفي سلسلة من التجارب الكمية والنوعية الصارمة، أظهرت تقنية Ref-AVS أداءً ممتازًا. خاصة في المجموعة الفرعية Seen، يتفوق Ref-AVS في الأداء على الطرق الأخرى الموجودة، مما يثبت بشكل كامل قدراته القوية في التجزئة. والأمر الأكثر جديرًا بالملاحظة هو أن نتائج الاختبار على المجموعتين الفرعيتين Unseen وNull تتحقق بشكل أكبر من قدرة التعميم الممتازة وقوة تقنية Ref-AVS على المراجع الخالية، والتي تعد ضرورية لسيناريوهات التطبيق العملي.
لم يجذب نجاح تقنية Ref-AVS اهتمامًا واسع النطاق في الأوساط الأكاديمية فحسب، بل فتح أيضًا مسارات جديدة للتطبيقات العملية المستقبلية. ويمكننا أن نتوقع أن تلعب هذه التكنولوجيا دورًا مهمًا في العديد من المجالات مثل تحليل الفيديو ومعالجة الصور الطبية والقيادة الذاتية والملاحة الآلية. على سبيل المثال، في المجال الطبي، قد يساعد Ref-AVS الأطباء على تفسير الصور الطبية المعقدة بشكل أكثر دقة؛ وفي مجال القيادة الذاتية، قد يحسن إدراك السيارة للبيئة المحيطة في الروبوتات، وقد يسمح للروبوتات بفهم أفضل تنفيذ التعليمات اللفظية البشرية.
تم عرض نتائج هذا البحث في ECCV2024، كما تم أيضًا نشر الأوراق ذات الصلة ومعلومات المشروع، مما يوفر موارد تعليمية واستكشافية قيمة للباحثين والمطورين حول العالم المهتمين بهذا المجال. ولا يعكس هذا الموقف المنفتح والمشارك الروح الأكاديمية لفريق البحث العلمي الصيني فحسب، بل سيعزز أيضًا التطور السريع في مجال الذكاء الاصطناعي بأكمله.
يمثل ظهور تقنية Ref-AVS خطوة مهمة في الفهم متعدد الوسائط للذكاء الاصطناعي. إنه لا يوضح القدرات الابتكارية لفريق البحث العلمي الصيني في مجال الذكاء الاصطناعي فحسب، بل يرسم أيضًا مخططًا أكثر ذكاءً وطبيعيًا لمستقبل التفاعل بين الإنسان والحاسوب. ومع استمرار تحسين هذه التكنولوجيا وتطبيقها، لدينا سبب لنتوقع أن أنظمة الذكاء الاصطناعي المستقبلية ستكون قادرة على فهم عالم البشر المعقد والتكيف معه بشكل أفضل وإحداث تغييرات ثورية في جميع مناحي الحياة.
عنوان الورقة: https://arxiv.org/abs/2407.10957
الصفحة الرئيسية للمشروع:
https://gewu-lab.github.io/Ref-AVS/
باختصار، أدى ظهور تقنية Ref-AVS إلى تحقيق اختراقات جديدة في مجال الفهم متعدد الوسائط للذكاء الاصطناعي، وهو أمر يستحق التطلع إليه. وستعمل هذه التكنولوجيا على تعزيز تطوير الذكاء الاصطناعي نحو تفاعلات أكثر ذكاءً وطبيعية، مما يوفر المزيد من الراحة للمجتمع البشري.