في الآونة الأخيرة، أصدرت MLCommons نتائج استدلال MLPerf v4.1. وشاركت الشركات المصنعة لشرائح استدلال الذكاء الاصطناعي المتعددة، وكانت المنافسة شرسة. ولأول مرة، تشمل هذه المنافسة شرائح من AMD وGoogle وUntetherAI وغيرها من الشركات المصنعة، بالإضافة إلى أحدث شرائح Blackwell من Nvidia. بالإضافة إلى مقارنة الأداء، أصبحت كفاءة الطاقة أيضًا بُعدًا تنافسيًا مهمًا. لقد أظهر العديد من المصنعين مهاراتهم الخاصة وأظهروا مزايا كل منهم في اختبارات قياس الأداء المختلفة، مما جلب حيوية جديدة إلى سوق شرائح استدلال الذكاء الاصطناعي.
في مجال تدريب الذكاء الاصطناعي، تكاد تكون بطاقات الرسومات من Nvidia منقطعة النظير، ولكن عندما يتعلق الأمر باستدلال الذكاء الاصطناعي، يبدو أن المنافسين بدأوا في اللحاق بالركب، خاصة فيما يتعلق بكفاءة الطاقة. على الرغم من الأداء القوي لأحدث شرائح Blackwell من Nvidia، فمن غير الواضح ما إذا كانت قادرة على الحفاظ على ريادتها. أعلنت ML Commons اليوم عن نتائج أحدث مسابقة لاستدلال الذكاء الاصطناعي - MLPerf Inference v4.1. ويشارك لأول مرة مسرع Instinct من AMD، ومسرع Trillium من Google، وشرائح UntetherAI الكندية الناشئة، وشرائح Blackwell من Nvidia. أطلقت شركتان أخريان، Cerebras وFuriosaAI، شرائح استدلال جديدة ولكنهما لم تقدما MLPerf للاختبار.
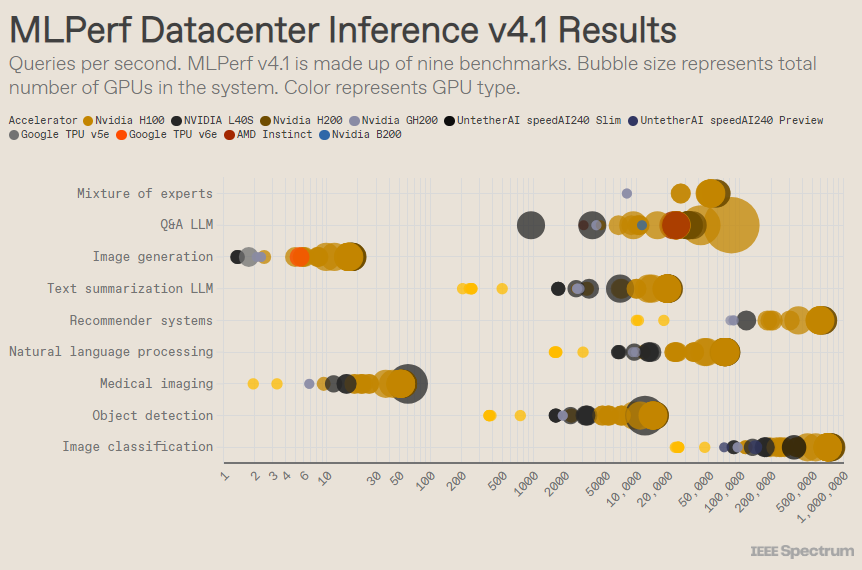
تم تصميم MLPerf مثل المنافسة الأولمبية، مع أحداث وأحداث فرعية متعددة. حصلت فئة "مرفق مركز البيانات" على أكبر عدد من الإدخالات. على عكس الفئة المفتوحة، تتطلب الفئة المغلقة من المشاركين إجراء الاستدلال مباشرة على نموذج معين دون تعديل البرنامج بشكل كبير. تختبر فئة مركز البيانات في المقام الأول القدرة على تجميع طلبات العمليات، بينما تركز فئة الحافة على تقليل زمن الوصول.
هناك 9 معايير مختلفة تحت كل فئة، تغطي مجموعة متنوعة من مهام الذكاء الاصطناعي، بما في ذلك إنشاء الصور الشائعة (مثل Midjourney) والإجابة على الأسئلة باستخدام نماذج لغوية كبيرة (مثل ChatGPT)، بالإضافة إلى بعض المهام المهمة ولكنها أقل شهرة، مثل محركات تصنيف الصور واكتشاف الأشياء والتوصية.
تضيف هذه الجولة معيارًا جديدًا - "النموذج الهجين الخبير". هذه طريقة شائعة بشكل متزايد لنشر نموذج اللغة، حيث تقوم بتقسيم نموذج اللغة إلى عدة نماذج صغيرة مستقلة، يتم ضبط كل منها بدقة لمهمة محددة، مثل المحادثة اليومية، أو حل المشكلات الرياضية، أو المساعدة في البرمجة. قال ميروسلاف هوداك، كبير الموظفين الفنيين في AMD، إنه من خلال تعيين كل استعلام لنموذجه الصغير المقابل، يتم تقليل استخدام الموارد، مما يؤدي إلى خفض التكاليف وزيادة الإنتاجية.

في اختبار "مركز البيانات المغلق" الشهير، لا تزال الفائزات عبارة عن عمليات إرسال تعتمد على وحدة معالجة الرسومات Nvidia H200 ورقاقة GH200 الفائقة، والتي تجمع بين وحدة معالجة الرسومات ووحدة المعالجة المركزية في حزمة واحدة. ومع ذلك، فإن نظرة فاحصة على النتائج تكشف بعض التفاصيل المثيرة للاهتمام. استخدم بعض المنافسين مسرعات متعددة، بينما استخدم آخرون مسرعًا واحدًا فقط. تكون النتائج أكثر إرباكًا إذا قمنا بتسوية الاستعلامات في الثانية حسب عدد المسرعات واحتفظنا بعمليات الإرسال الأفضل أداءً لكل نوع من أنواع المسرعات. تجدر الإشارة إلى أن هذا الأسلوب يتجاهل دور وحدة المعالجة المركزية والاتصال البيني.
على أساس كل مسرع، تفوقت شركة Nvidia's Blackwell في مهام الأسئلة والأجوبة ذات النماذج اللغوية الكبيرة، حيث قدمت سرعة 2.5 مرة مقارنة بتكرارات الرقائق السابقة، وهو المعيار الوحيد الذي قدمت إليه. كان أداء شريحة المعاينة speedAI240 من Untether AI تقريبًا مثل أداء H200 في مهمة التعرف على الصور الوحيدة التي تم إرسالها إليها. يؤدي أداء Trillium من Google أقل قليلاً من H100 وH200 في مهام إنشاء الصور، بينما يؤدي أداء Instinct من AMD ما يعادل H100 في مهام الأسئلة والأجوبة الخاصة بنموذج اللغة الكبيرة.
ينبع جزء من نجاح Blackwell من قدرتها على تشغيل نماذج لغوية كبيرة باستخدام دقة الفاصلة العائمة 4 بت. تعمل Nvidia والمنافسون على تقليل عدد البتات الممثلة في نماذج التحويل مثل ChatGPT لتسريع العمليات الحسابية. قدمت Nvidia رياضيات 8 بت في H100، وهذا التقديم هو أول عرض توضيحي لرياضيات 4 بت في معيار MLPerf.
وقال ديف سالفاتور، مدير تسويق المنتجات في نفيديا، إن التحدي الأكبر في العمل مع مثل هذه الأرقام منخفضة الدقة هو الحفاظ على الدقة. للحفاظ على الدقة العالية في عمليات تقديم MLPerf، قام فريق Nvidia بإجراء العديد من الابتكارات في البرنامج.
بالإضافة إلى ذلك، يتضاعف عرض النطاق الترددي لذاكرة بلاكويل تقريبًا ليصل إلى 8 تيرابايت في الثانية، مقارنة بـ 4.8 تيرابايت في H200.
يستخدم إصدار Blackwell من Nvidia شريحة واحدة، لكن Salvator يقول إنها مصممة للتواصل والتوسع، وستؤدي بشكل أفضل عند دمجها مع NVLink interconnect من Nvidia. تدعم وحدات معالجة الرسوميات Blackwell ما يصل إلى 18 اتصال NVLink بسرعة 100 جيجابايت في الثانية، مع عرض نطاق ترددي إجمالي يبلغ 1.8 تيرابايت في الثانية، أي ما يقرب من ضعف عرض النطاق الترددي للتوصيل البيني لـ H100.
يعتقد سلفاتور أنه مع استمرار نماذج اللغات الكبيرة في التوسع، فإن الاستدلال سيتطلب منصات متعددة وحدات معالجة الرسومات لتلبية الطلب، وقد تم تصميم Blackwell لهذا الموقف. قال سلفاتور: "هافيل عبارة عن منصة".
قامت Nvidia بتقديم نظام شرائح Blackwell الخاص بها إلى فئة Preview الفرعية، مما يعني أنه ليس متاحًا بعد، ولكن من المتوقع أن يكون متاحًا قبل إصدار MLPerf التالي، أي حوالي ستة أشهر من الآن.
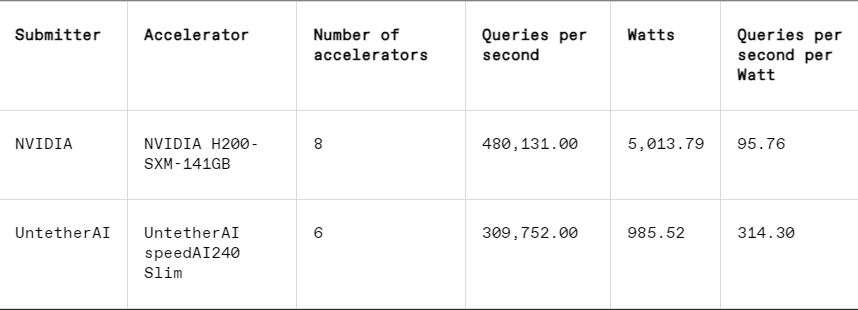
في كل معيار، يتضمن MLPerf أيضًا قسمًا لقياس الطاقة يقوم باختبار استهلاك الطاقة الفعلي لكل نظام بشكل منهجي أثناء أداء المهام. المنافسة الرئيسية لهذه الجولة (فئة الطاقة المغلقة لمركز البيانات) كان بها مقدمان فقط، Nvidia وUntether AI. بينما شاركت Nvidia في جميع الاختبارات، قدمت Untether النتائج المتعلقة بمهمة التعرف على الصور فقط.
يتفوق Untether AI في هذا الصدد، حيث نجح في تحقيق كفاءة ممتازة في استخدام الطاقة. تستخدم رقاقتهم أسلوبًا يسمى "الحوسبة في الذاكرة". تتكون شريحة Untether AI من بنك من خلايا الذاكرة مع معالج صغير موجود في مكان قريب. يعمل كل معالج بالتوازي، ويعالج البيانات في وقت واحد مع وحدات الذاكرة المجاورة، مما يقلل بشكل كبير من الوقت والطاقة المستهلكة في نقل بيانات النموذج بين الذاكرة ونواة الحوسبة.
قال روبرت بيتشلر، نائب رئيس المنتج في Untether AI: "لقد وجدنا أنه عند تشغيل أحمال عمل الذكاء الاصطناعي، فإن 90% من استهلاك الطاقة ينقل البيانات من ذاكرة الوصول العشوائي الديناميكية (DRAM) إلى وحدات معالجة ذاكرة التخزين المؤقت". "لذا فإن ما تفعله Untether هو تقريب العملية الحسابية من البيانات، بدلاً من نقل البيانات إلى وحدة الحوسبة."
يعمل هذا الأسلوب بشكل جيد بشكل خاص في فئة فرعية أخرى من MLPerf: إغلاق الحافة. وأوضح بيتشلر أن هذه الفئة تركز على حالات الاستخدام الأكثر عملية، مثل فحص الآلات في المصانع، وروبوتات الرؤية الموجهة، والمركبات ذاتية القيادة، وهي تطبيقات لها متطلبات صارمة لكفاءة الطاقة والمعالجة السريعة.
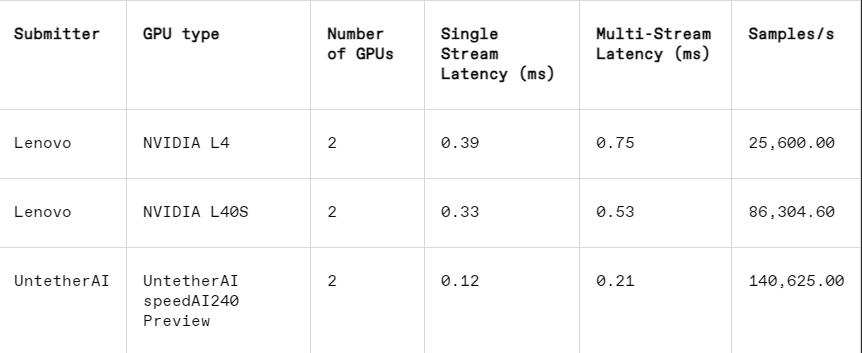
في مهمة التعرف على الصور، يكون أداء زمن الوصول لشريحة المعاينة speedAI240 الخاصة بـ Untether AI أسرع بمقدار 2.8 مرة من شريحة L40S من Nvidia، كما يتم زيادة الإنتاجية (عدد العينات في الثانية) بمقدار 1.6 مرة. قدمت الشركة الناشئة أيضًا نتائج استهلاك الطاقة في هذه الفئة، لكن منافسي Nvidia لم يفعلوا ذلك، مما يجعل المقارنات المباشرة صعبة. ومع ذلك، تتمتع شريحة المعاينة speedAI240 من Untether AI باستهلاك طاقة اسمي يبلغ 150 واط، في حين أن شريحة L40S من Nvidia تبلغ 350 واط، مما يظهر ميزة 2.3x في استهلاك الطاقة وأداء أفضل في زمن الوصول.
على الرغم من أن Cerebras وFuriosa لم يشاركا في MLPerf، إلا أنهما أصدرا أيضًا شرائح جديدة على التوالي. كشفت شركة Cerebras عن خدمة الاستدلال الخاصة بها في مؤتمر IEEE Hot Chips في جامعة ستانفورد. وتقوم شركة سيريبراس، التي يقع مقرها في ساني فالي بولاية كاليفورنيا، بتصنيع شرائح عملاقة كبيرة الحجم بالقدر الذي تسمح به رقائق السيليكون، وبالتالي تتجنب الترابط بين الرقائق وتزيد بشكل كبير من عرض النطاق الترددي للذاكرة للجهاز. وهي تستخدم بشكل أساسي لتدريب الشبكات العصبية العملاقة. والآن، قاموا بترقية أحدث أجهزة الكمبيوتر الخاصة بهم، CS3، لدعم الاستدلال.
على الرغم من أن Cerebras لم تقدم MLPerf، إلا أن الشركة تدعي أن منصتها تتفوق على H100 بمقدار 7x ورقاقة Groq المنافسة بمقدار 2x في عدد رموز LLM التي يتم إنشاؤها في الثانية. قال أندرو فيلدمان، الرئيس التنفيذي والمؤسس المشارك لشركة Cerebras: "اليوم، نحن في عصر الاتصال الهاتفي للذكاء الاصطناعي التوليدي". "كل هذا بسبب وجود عنق الزجاجة في النطاق الترددي للذاكرة. سواء كانت Nvidia's H100 أو AMD's MI300 أو TPU، فإنهم جميعًا يستخدمون نفس الذاكرة الخارجية، مما يؤدي إلى نفس القيود. لقد كسرنا هذا الحاجز لأننا نفعل ذلك على مستوى التصميم على مستوى الرقاقة. "
في مؤتمر Hot Chips، عرضت شركة Furiosa من سيول أيضًا شريحة الجيل الثاني RNGD (تُلفظ "المتمردة"). تتميز شريحة Furiosa الجديدة ببنية معالج Tensor Contraction (TCP). في أحمال عمل الذكاء الاصطناعي، تكون الوظيفة الرياضية الأساسية هي مضاعفة المصفوفات، وغالبًا ما يتم تنفيذها في الأجهزة كوظيفة بدائية. ومع ذلك، فإن حجم وشكل المصفوفة، أي الموتر الأوسع، يمكن أن يختلف بشكل كبير. ينفذ RNGD هذا الضرب الموتر الأكثر عمومية باعتباره بدائيًا. قال جون بايك، المؤسس والرئيس التنفيذي لشركة Furiosa، في Hot Chips: "أثناء الاستدلال، تختلف أحجام الدفعات بشكل كبير، لذلك من المهم الاستفادة الكاملة من التوازي المتأصل وإعادة استخدام البيانات لشكل موتر معين".
على الرغم من أن Furiosa لا تمتلك MLPerf، فقد قارنوا شريحة RNGD بمعيار ملخص LLM الخاص بـ MLPerf في الاختبار الداخلي، وكانت النتائج قابلة للمقارنة بشريحة L40S من Nvidia، ولكنها استهلكت 185 واط فقط مقارنة بـ 320 واط في L40S. وقال بايك إن الأداء سوف يتحسن مع المزيد من تحسينات البرامج.
وأعلنت شركة IBM أيضًا عن إطلاق شريحة Spyre الجديدة، المصممة للمؤسسات لتوليد أعباء عمل الذكاء الاصطناعي، ومن المتوقع أن تكون متاحة في الربع الأول من عام 2025.
من الواضح أن سوق شرائح الاستدلال بالذكاء الاصطناعي سيكون مزدحمًا في المستقبل المنظور.
المرجع: https://spectrum.ieee.org/new-inference-chips
بشكل عام، تظهر نتائج MLPerf v4.1 أن المنافسة في سوق شرائح الاستدلال للذكاء الاصطناعي أصبحت شرسة بشكل متزايد. على الرغم من أن Nvidia لا تزال تحافظ على الصدارة، إلا أنه لا يمكن تجاهل صعود الشركات المصنعة مثل AMD وGoogle وUntether AI. وفي المستقبل، ستصبح كفاءة استخدام الطاقة عاملاً تنافسيًا رئيسيًا، كما ستلعب التقنيات الجديدة مثل الحوسبة في الذاكرة دورًا مهمًا أيضًا. ستستمر الابتكارات التكنولوجية لمختلف الشركات المصنعة في تعزيز تحسين قدرات الذكاء الاصطناعي وتوفير زخم قوي لنشر تطبيقات الذكاء الاصطناعي وتطويرها.